{ }
Blog
Vespa.ai
Docs
Subscribe
Vespa Blog
We Make AI Work
Posts by Jo Kristian Bergum
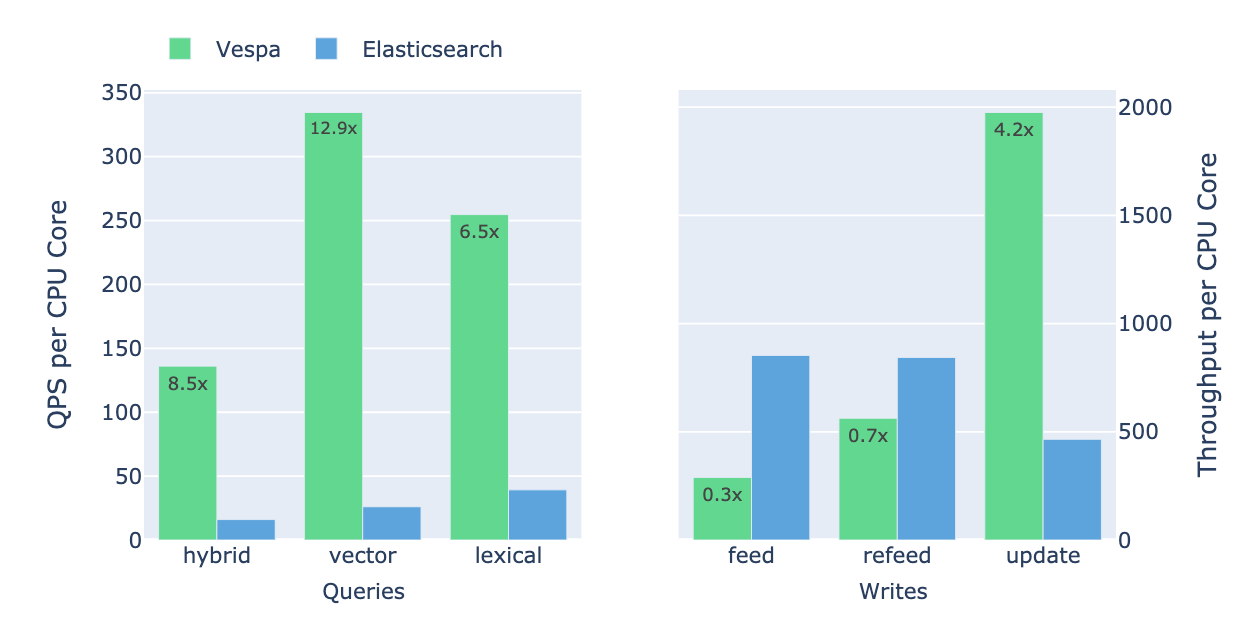
Elasticsearch vs Vespa Performance Comparison
Detailed report of a comprehensive performance comparison between Vespa and Elasticsearch for an e-commerce search application.
Scaling ColPali to billions of PDFs with Vespa
Scaling Vision-Driven Document Retrieval with ColPali to large collections.
Beyond Text: The Rise of Vision-Driven Document Retrieval for RAG
Imagine a world where search engines see documents with human-like vision.
Small but Mighty: Using Answer.ai's ColBERT embedding model in Vespa
Using Answer.ai's ColBERT-small model for efficient and effective passage search
PDF Retrieval with Vision Language Models
Connecting the ColPali model with Vespa for complex document format retrieval.
Adaptive In-Context Learning 🤝 Vespa - part one
Adaptive In-Context Learning (ICL) with Vespa to retrieve context-sensitive examples
Improving retrieval with LLM-as-a-judge
How to create your own reusable retrieval evaluation dataset for your data and use it to assess your retrieval system's effectiveness
Matryoshka 🤝 Binary vectors: Slash vector search costs with Vespa
Announcing Matryoshka (dimension flexibility) and binary quantization in Vespa and how these features slashes costs.
Perspectives on R in RAG
In this blog post, I share perspectives on the R in RAG.
Scaling vector search using Cohere binary embeddings and Vespa
Three comprehensive guides to using the Cohere Embed v3 binary embeddings with Vespa.
Announcing Vespa Long-Context ColBERT
Announcing long-context ColBERT, giving it larger context for scoring and simplifying long-document RAG applications.
Announcing the Vespa ColBERT embedder
Announcing the native Vespa ColBERT embedder in Vespa, enabling explainable semantic search using token-level vector representations
Redefining Hybrid Search Possibilities with Vespa - part one
This is the first blog post in a series on hybrid search. This first post focuses on efficient hybrid retrieval and representational approaches in IR...
Turbocharge RAG with LangChain and Vespa Streaming Mode for Sharded Data
A hands-on guide to connect LangChain with Vespa streaming mode to build cost-efficient RAG applications over naturally sharded data.
🎄Advent of Tensors 2023 🎅
Prepare to embark on a festive journey as we bring you the Advent of Tensors!
Hands-On RAG guide for personal data with Vespa and LLamaIndex
A hands-on guide to using Vespa streaming mode with PyVespa and LLamaIndex.
Announcing search.vespa.ai
A new search experience for Vespa-related content - powered by Vespa, LangChain, and OpenAI’s chatGPT model - our motivation for building it, features, limitations, and...
Representing BGE embedding models in Vespa using bfloat16
This post demonstrates how to use recently announced BGE embedding models in Vespa. We evaluate the effectiveness of two BGE variants on the BEIR trec-covid...
Accelerating Transformer-based Embedding Retrieval with Vespa
In this post, we’ll see how to accelerate embedding inference and retrieval with little impact on quality. We’ll take a holistic approach and deep-dive into...
Simplify Search with Multilingual Embedding Models
This blog post presents and shows how to represent a robust multilingual embedding model of the E5 family in Vespa.
Enhancing Vespa’s Embedding Management Capabilities
We are thrilled to announce significant updates to Vespa’s support for inference with text embedding models that maps texts into vector representations.
Minimizing LLM Distraction with Cross-Encoder Re-Ranking
Announcing global-phase re-ranking support in Vespa, unlocking efficient re-ranking with precise cross-encoder models. Cross-encoder models minimize distraction in retrieval-augmented completions generated by Large Language Models....
Customizing Reusable Frozen ML-Embeddings with Vespa
Deep-learned embeddings are popular for search and recommendation use cases. This post introduces the concept of using reusable frozen embeddings and tailoring them with Vespa....
Revolutionizing Semantic Search with Multi-Vector HNSW Indexing in Vespa
Announcing multi-vector indexing support in Vespa, which allows you to index multiple vectors per document and retrieve documents by the closest vector in each document....
Improving Search Ranking with Few-Shot Prompting of LLMs
Distilling the knowledge and power of generative Large Language Models (LLMs) with billions of parameters to ranking models with a few million parameters.
Improving Zero-Shot Ranking with Vespa Hybrid Search - part two
Where should you begin if you plan to implement search functionality but have not yet collected data from user interactions to train ranking models?
Improving Zero-Shot Ranking with Vespa Hybrid Search
If you are planning to implement search functionality but have not yet collected data from user interactions to train ranking models, where should you begin?...
Improving Product Search with Learning to Rank - part three
This is the third blog post on applying learning to rank to enhance E-commerce search.
Improving Product Search with Learning to Rank - part two
This is the second blog post on applying learning to rank to enhance E-commerce search.
Improving Product Search with Learning to Rank - part one
This is the first blog post on applying learning to rank to enhance E-commerce search.
Building Billion-Scale Vector Search - part two
Searching billion-scale datasets without breaking the bank.
Building Billion-Scale Vector Search - part one
How fast is fast? Many consider the blink of an eye, around 100-250ms, to be plenty fast.
Will new vector databases dislodge traditional search engines?
Doug Turnbull asks an interesting question on Linkedin; Will new vector databases dislodge traditional search engines?
Managed Vector Search using Vespa Cloud
This blog post describes how your organization can unlock the full potential of multimodal AI-powered vector representations using Vespa -- the industry-leading open-source big data...
Billion-scale vector search using hybrid HNSW-IF
This blog post describes HNSW-IF, a cost-efficient solution for high-accuracy vector search over billion scale vector datasets.
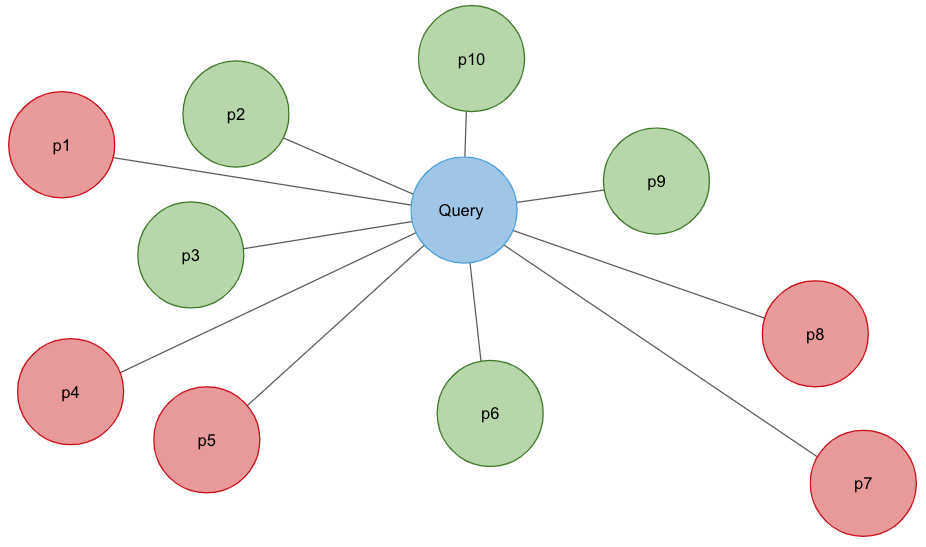
Query Time Constrained Approximate Nearest Neighbor Search
This blog post describes Vespa's industry leading support for combining approximate nearest neighbor search, or vector search, with query constraints to solve real-world search and...
Billion-scale vector search with Vespa - part two
Part two in a blog post series on billion-scale vector search with Vespa. This post explores the many trade-offs related to nearest neighbor search.
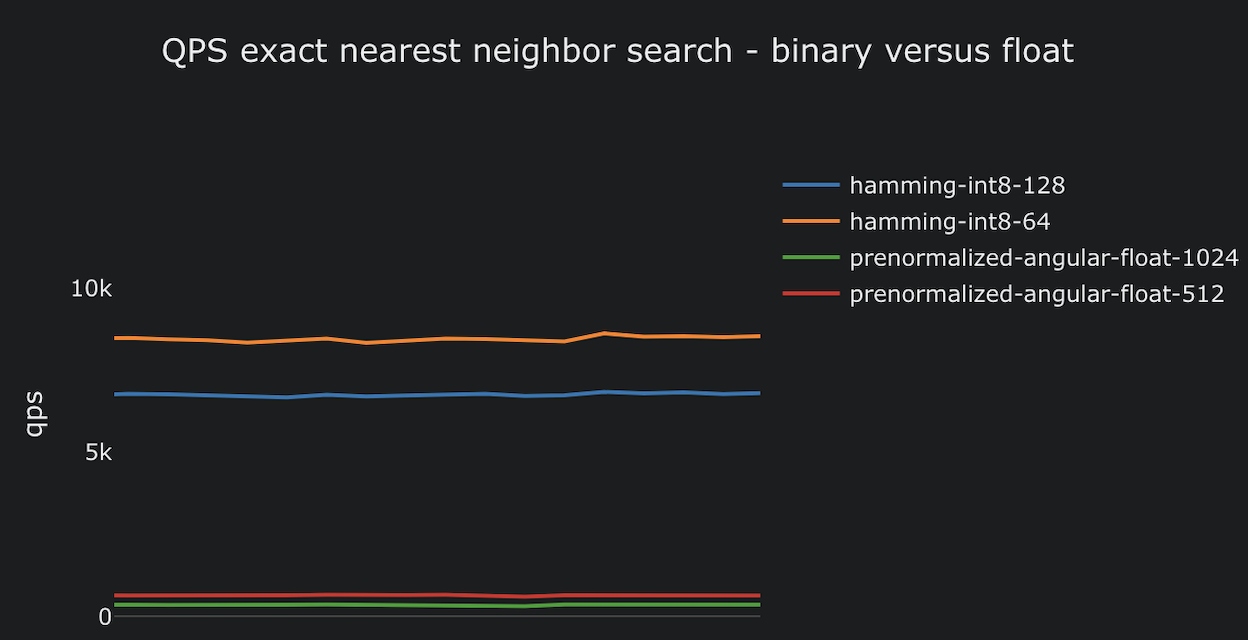
Billion-scale vector search with Vespa - part one
Part one in a blog post series on billion-scale vector search. This post covers using nearest neighbor search with compact binary representations and bitwise hamming...
Result diversification using Vespa result grouping
This blog post dives into how to achieve result diversification using Vespa's grouping framework.
Pretrained Transformer Language Models for Search - part 4
This is the fourth blog post in a series of posts where we introduce using pretrained Transformer models for search and document ranking with Vespa.ai....
Pretrained Transformer Language Models for Search - part 3
This is the third blog post in a series of posts where we introduce using pretrained Transformer models for search and document ranking with Vespa.ai....
Pretrained Transformer Language Models for Search - part 2
This is the second blog post in a series of posts where we introduce using pretrained Transformer models for search and document ranking with Vespa.ai....
Pretrained Transformer Language Models for Search - part 1
This is the first blog post in a series of posts where we introduce using pretrained Transformer models for search and document ranking with Vespa.ai....
Using approximate nearest neighbor search to find similar products
Approximate nearest neighbor search demonstration using Amazon Product dataset
E-commerce search and recommendation with Vespa.ai
Holiday shopping season is upon us and it’s time for a blog post on E-commerce search and recommendation using Vespa.ai. Vespa.ai is used as the...
Never miss a
story
from us, subscribe to our newsletter
Subscribe