

Photo by Rob Fuller on Unsplash
Updated 2022-10-21: Added links and clarified some sections
In this blog series we demonstrate how to represent transformer models in a multiphase retrieval and ranking pipeline using Vespa.ai. We also evaluate these models on the largest Information Retrieval relevance dataset, namely the MS Marco Passage ranking dataset. We demonstrate how to achieve close to state of the art ranking using miniature transformer models with just 22M parameters, beating large ensemble models with billions of parameters.
- Post one: Introduction to neural ranking and the MS Marco passage ranking dataset
- Post two: Efficient retrievers, sparse, dense, and hybrid retrievers
- Post three: Re-ranking using multi-representation models (ColBERT)
- Post four: Re-ranking using cross-encoders)
In the first post in this series we introduced using pre-trained models for ranking. In this second post we study efficient candidate retrievers which can be used to efficiently find candidate documents which are re-ranked using more advanced models.
Multiphase retrieval and ranking
Due to computational complexity of cross interaction transformer models there has been renewed interest in multiphase retrieval and ranking. In a multiphased retrieval and ranking pipeline, the first phase retrieves candidate documents using a cost efficient retrieval method and the more computationally complex cross-attention or late interaction model inference is limited to the top ranking documents from the first phase.
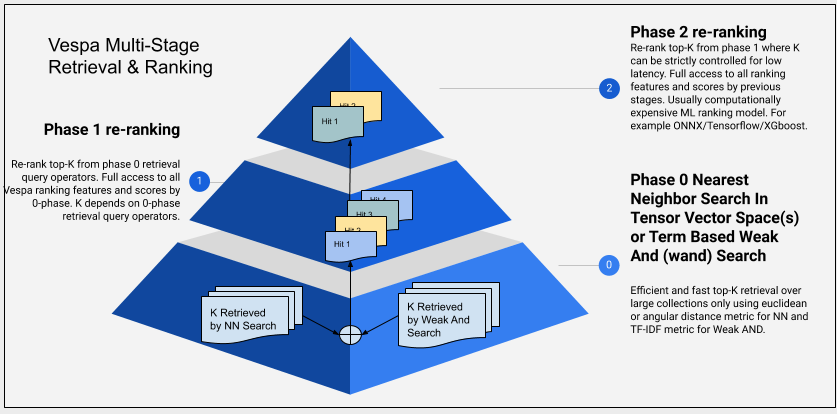
Illustration of a multi-stage retrieval and ranking architecture is given in the figure above. The illustration is from Phased ranking with Vespa. The three phases illustrated in the diagram is per content node, which is retrieving and re-ranking a subset of the total document volume. In addition one can also re-rank the global top scoring documents after the results from the nodes involved in the query are merged to find the global best documents. This step might also involve diversification of the result set before final re-ranking.
Broadly there are two categories of efficient sub-linear retrieval methods
- Sparse retrieval using lexical term matching over inverted indexes, potentially accelerated by the WAND algorithm
- Dense retrieval using dense vector representation of queries and documents, potentially accelerated by approximate nearest neighbor search algorithms
In the next sections we take a deep dive into these two methods and we also evaluate their effectiveness on the MS Marco Passage Ranking relevancy dataset. We also show how these two methods can be combined with Vespa.
Sparse lexical retrieval
Classic information retrieval (IR) relying on lexical matching which has been around since the early days of Information Retrieval. One example of a popular lexical based retrieval scoring function is BM25. Retrieval can be done in sub-linear time using inverted indexes and accelerated by dynamic pruning algorithms like WAND. Dynamic pruning algorithms avoid scoring exhaustively all documents which match at least one of the query terms. In the below Vespa document schema we declare a minimal passage document type which we can use to index the MS Marco Passage ranking dataset introduced in post 1.
search passage {
document passage {
field text type string {
indexing: summary |index
index:enable-bm25
}
field id type int {
indexing: summary |attribute
}
}
fieldset default {
fields: text
}
rank-profile bm25 {
first-phase {
expression: bm25(text)
}
}
}
We define a text field which we populate with the passage text. The indexing directive controls how the field is handled.The summary means that the text should be returned in the search result page and index specifies that we want to build inverted index data structures for efficient search and matching. We also define a ranking profile with only a single ranking phase using the Vespa bm25(name) text ranking feature, one out of many built in Vespa text matching ranking features.
Once we have indexed our data we can search using the Vespa HTTP POST query api:
{
"yql": "select id,text from passage where userQuery();",
"hits": 10,
"query": "is cdg airport in main paris?",
"ranking.profile": "bm25",
"type": "all"
}
- The yql parameter is the Vespa query language, userQuery() is a reference to the query parameter
- The hits parameter controls the number of hits in the Vespa response
- The query parameter contains the free text input query from the end user. Simple query language
- The ranking.profile parameter choses the ranking profile to use for the query
- The type specifies the query type (all, any, phrase) which controls the boolean query logic. All requires that all query terms are found in the document while any specifies at least one of the query terms should match in the document.
If we use the above query to search the MS Marco Passages we end up ranking only 2 passages and the query takes 7 ms. If we change type to any instead of all we end up ranking 7,926,256 passages (89% of the total collection) and the query takes 120 ms. Exact timing depends obviously on HW and number of threads used to evaluate the query but the main point is that brute force matching all documents which contains at least one term is expensive. While restricting to all is too restrictive, failing to recall the relevant documents. So what is the solution to this problem? How can we find the relevant documents without having to fully score almost all passages in the collection?
Meet the dynamic pruning algorithm WAND
The WAND algorithm is described in detail in Efficient Query Evaluation using a Two-Level Retrieval Process (PDF)
We have determined that our algorithm significantly reduces the total number of full evaluations by more than 90%, almost without any loss in precision or recall. At the heart of our approach there is an efficient implementation of a new Boolean construct called WAND or Weak AND that might be of independent interest
Vespa implements the WAND as a query operator and the below is an example of how to use it using our query example from above:
{
"yql": "select id, text from passage where ([{\"targetNumHits\": 10}]weakAnd(default contains \"is\", default contains \"cdg\", default contains \"airport\", default contains \"in\", default contains \"main\", default contains \"paris\"));",
"hits": 10,
"ranking.profile": "bm25"
}
Using the above WAND query only fully ranks 2409 passages using the bm25 ranking profile and recall at first positions is the same as with brute force any, so we did not lose any accuracy but saved a lot of resources. Using the weakAnd operator, the query takes 12 ms instead of 120ms with brute force any.
There are two WAND/WeakAnd implementations in Vespa where in the above example we used weakAnd() which fully integrates with text processing (tokenization and index statistics like IDF(Inverse Document Frequency)). The alternative is wand() where the end user can control the query and document side weights explicitly. The latter wand() operator can be used to implement DeepCT and HDCT: Context-Aware Term Importance Estimation For First Stage Retrieval as Vespa gives the user full control of query and document term weighting without having to bloat the regular index by repeating terms to increase or lower the term frequency. Read more in Using WAND with Vespa.
Dense Retrieval using bi-encoders over Transformer models
Embedding based models embed or map queries and documents into a latent low dimensional dense embedding vector space and use vector search to retrieve documents. Dense retrieval could be accelerated by using approximate nearest neighbor search, for example indexing the document vector representation using HNSW graph indexing. In-domain dense retrievers based on bi-encoder architecture trained on MS Marco passage data have demonstrated that they can outperform sparse lexical retrievers with a large margin. Let us introduce using dense retrievers with Vespa.
In this example we use a pre-trained dense retriever model from Huggingface 🤗 sentence-transformers/msmarco-MiniLM-L-6-v3 . The model is based on MiniLM and the output layer has 384 dimensions. The model has just 22.7M trainable parameters and encoding the query using a quantized model takes approximately 8 ms on cpu. The original model uses mean pooling over the last layer of the MiniLM model but we also add a L2 normalization to normalize vectors to unit length (1) so that we can use innerproduct distance metric instead of angular distance metric. This saves computations during the approximate nearest neighbor search.
We expand our passage document type with a dense tensor field mini_document_embedding and a new ranking profile.
search passage {
document passage {
field text type string {
indexing: summary |index
index:enable-bm25
}
field mini_document_embedding type tensor<float>(d0[384]) {
indexing: attribute | index
attribute {
distance-metric: innerproduct
}
index {
hnsw {
max-links-per-node: 32
neighbors-to-explore-at-insert: 500
}
}
}
field id type int {
indexing: summary |attribute
}
}
fieldset default {
fields: text
}
rank-profile bm25 {
first-phase {
expression: bm25(text)
}
}
rank-profile dense {
first-phase {
expression: closeness(field,mini_document_embedding)
}
}
}
The mini_document_embedding tensor is dense (denoted by d0[384]) and is of dimensionality 384 (determined by the Transformer model we use, and possible linear dimension reduction). We use float resolution (4 bytes) for the tensor cell values (valid choices are double, bfloat16 and int8). We also define HNSW index for the field, and we set 2 HNSW indexing parameters which is an accuracy versus performance tradeoff. See HNSW for details. Accuracy is typically measured by recall@k comparing brute force nearest neighbor search versus the approximate nearest neighbor search at level k. The dense ranking profile specifies how we want to rank (or actually re-rank) our documents, in this case we use the closeness ranking feature. Documents close to the query in the embedding space is ranked higher than documents which are far. At indexing time we need to convert the passage text into the dense vector representation and index. At query time, we need to encode the query and use approximate nearest neighbor search:
{
"yql": "select id, text from passage where [{\"targetNumHits\": 10]nearestNeighbor(mini_document_embedding, query_embedding);"
"hits": 10,
"query": "is cdg airport in main paris?",
"ranking.profile": "dense",
"ranking.features.query(query_embedding)": [0.08691329, -0.046273664, -0.010773866,..,..]
}
In the above example we use the Vespa nearestNeigbhor query operator to retrieve the 10 closests documents in embedding space for the input query embedding vector passed in the ranking.features.query(query_embedding) parameter. In this example, query encoding (the forward query encoding pass of the query to obtain the query embedding) is done outside but we can also represent the query encoding model inside Vespa, avoiding complicating our online serving deployment setup:
Representing the bi-encoder model inside Vespa
To represent the bi-encoder query model in Vespa, we need to export the Huggingface PyTorch model into ONNX format for efficient serving in Vespa. Vespa supports evaluating ONNX models for ranking and query encoding. To speed up evaluation on CPU we use quantized version.
Hybrid Dense Sparse Retrieval
Recent research indicates that combining dense and sparse retrieval could improve the recall, see for example A Replication Study of Dense Passage Retriever. The hybrid approach combines dense and sparse retrieval but requires search technology which supports both sparse lexical and dense retrieval. Vespa.ai supports hybrid retrieval in the same query by combining the WAND and ANN algorithms. There are two ways to do this:
Disjunction (OR)
{
"yql": "select id, text from passage where
([{\"targetNumHits\": 10]nearestNeighbor(mini_document_embedding, query_embedding)) or
([{\"targetNumHits\": 10}]weakAnd(default contains \"is\"...));"
"hits": 10,
"query": "is cdg airport in main paris?",
"ranking.profile": "hybrid",
"ranking.features.query(query_embedding)": [0.08691329, -0.046273664, -0.010773866,..,..]
}
In the above example we combine ANN with WAND using OR disjunction and we have a hybrid ranking profile which can combine using the dense and sparse ranking signals (e.g bm25 and vector distance/closeness). Approximately 10 + 10 documents will be exposed to the first-phase ranking function (depending on targetNumHits). It is then up to the first-phase ranking expression to combine the scores of these two different retrieval methods into a final score. See A Replication Study of Dense Passage Retriever for examples of parameter/weighting. For example it could look something like this:
rank-profile hybrid {
first-phase {
expression: 0.7*bm25(text) + 2.9*closeness(field, mini_document_embedding)
}
}
Rank:
{
"yql": "select id, text from passage where rank(
([{\"targetNumHits\": 10]nearestNeighbor(mini_document_embedding, query_embedding)),
([{\"targetNumHits\": 10}]weakAnd(default contains \"is\"...));"
"hits": 10,
"query": "is cdg airport in main paris?",
"ranking.profile": "hybrid",
"ranking.features.query(query_embedding)": [0.08691329, -0.046273664, -0.010773866,..,..]
}
Using rank() operator will retrieve using the nearest neighbor query operator (first operand to the rank()) but also produce sparse ranking features (e.g bm25) for those documents retrieved by the nearest neighbor search operator. This hybrid retrieval schema is more efficient than using disjunction OR. This could also be turned the other way around using the sparse weakAnd() as the first operand of rank().
Retriever evaluation
We evaluate the ranking effectiveness of two efficient retrievers on MS Marco Passage Ranking dev query split (6980 queries):
| Retrieval method | Ranking | MRR@10 | Recall@100 | Recall@200 | Recall@1000 |
|---|---|---|---|---|---|
| weakAnd | bm25 | 0.185 | 0.66 | 0.73 | 0.85 |
| nearestNeighbor | innerproduct | 0.310 | 0.82 | 0.87 | 0.94 |
The end to end runtime latency (including query encoding for the nearestNeighbor method) is roughly 20ms for the precision oriented run where we use it as a single stage retriever and retrieve 10 hits.
Example evaluation run using the dense retriever (single threaded client query execution). The Vespa api endpoint performs query encoding and retrieval using nearest neighbor search.
$ ./src/main/python/evaluate_passage_run.py --rank_profile dense --retriever dense --ann_hits 100 --hits 10 --run_file dev.test --query_split dev --endpoint https://$ENDPOINT:4443/search/ 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6980/6980 [02:21<00:00, 49.30it/s] $ ./msmarco_eval.py qrels.dev.small.tsv dev.test ##################### MRR @10: 0.309637342520579 QueriesRanked: 6980 #####################
50 iterations/s using a single thread translates to about 20 ms end to end (including query encoding and nearest neighbor search over 8.8M passages). Analysis shows about 8 ms on query encoding and 12 ms for the nearest neighbor search.
Sparse using WAND/BM25 is a little bit faster (no query encoding) and is at about 15 ms when used as a single stage retriever fetching 10 hits. Fetching 1000 hits to evaluate recall (using e.g trec_eval) with higher number of hits returned takes more time as one needs to transfer more data over the network. This is also an important observation as Vespa evalutes ranking stages inside the content node(s) so we don’t need to transfer data to perform re-ranking in an external serving system. As we can see from the recall metrics, with sparse (bm25) single stage retrieval one needs to fetch 1000 documents to have decent recall for the re-ranker to work on.
We did not perform any HNSW parameter exploration to document vector search recall accuracy (brute force versus approximate) and we also use quantization to speed up query encoding through the MiniLM model.
What stands out is not only the MRR@10 which is a precision oriented metric but the good Recall@k numbers for the dense retriever. We are more interested in the Recall@k numbers as we plan to introduce re-ranking steps later on and as we can see Recall@100 for the dense retriever is almost the same as the recall@1000 for the sparse retriever. This means we can re-rank about 10x less hits and still expect almost the same precision. Note that the dense retriever is trained on MS Marco, using this dense model on a different domain might not give the same benefit over weakAnd/BM25.
Summary
In this blog post we have demonstrated how one can represent three different efficient ways to retrieve
- Sparse lexical retrieval accelerated by the WAND query operator and how it compares to exhaustive search (OR)
- Dense retrieval accelerated by ANN query operator in Vespa (HNSW) and representing the Transformer based query encoder model in Vespa
- How to perform hybrid retrieval using a combination of WAND and ANN
- Evaluation on MS Marco Passage ranking
In the third post in this series we will look at re-rankers using ColBERT and in the fourth post we will finally add an all-to-all interaction model to the mix.