{ }
Blog
Vespa.ai
Docs
Subscribe
Vespa Blog
We Make AI Work
Featured
Your agent wants to search like a 2010 quant
The idea of empowering AI agents to retrieve information like a professional is going mainstream.
How Perplexity beat Google on AI Search with Vespa.ai
Perplexity demonstrates the quality of their search solution and show what it takes to achieve it
All Stories
Your agent wants to search like a 2010 quant
The idea of empowering AI agents to retrieve information like a professional is going mainstream.
Re-autoresearching MSMARCO BM25, on Vespa
BM25 is having a moment. We reproduce Doug Turnbull's MSMARCO autoresearch experiment in Vespa and get a comparable MRR@10 lift from existing rank features — with twice the generalization to...
Vespa Newsletter, May 2026
Advances in Vespa include finer control over deployments, smarter ranking, richer embedding integrations, and more scalable vector search.
Photo by
Shaun Sullivan
on
Unsplash
Scaling a Vespa Application: Feeding Fast and Furiously
A tutorial on how to scale the resources in a Vespa application to increase feed throughput. Using the metrics dashboard for informed and optimised scaling.
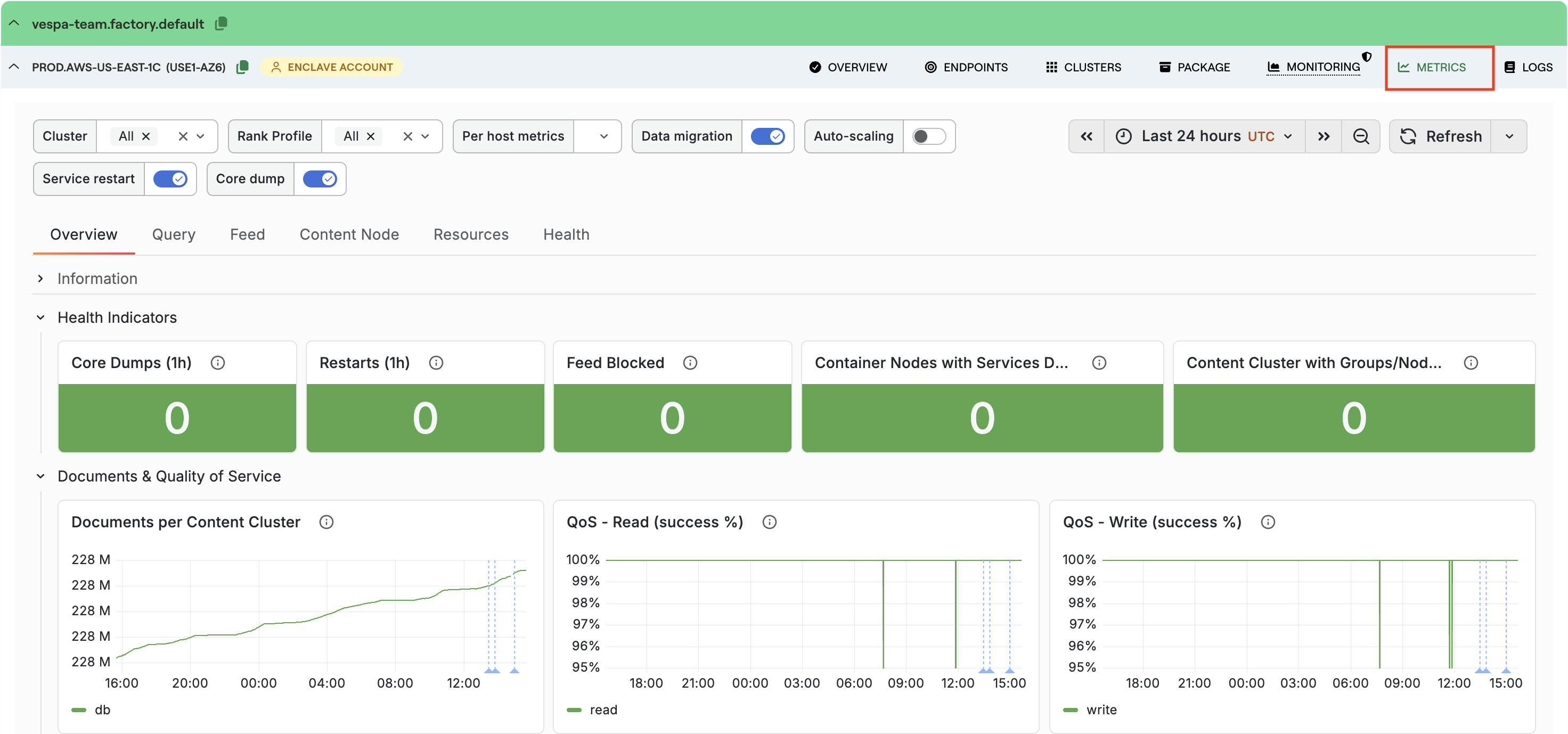
The Vespa Cloud Metrics Dashboard
A guide to the Vespa Cloud metrics dashboard — how to move from symptom to bottleneck to action, and what's new in the latest revision.
Using Large ONNX Models with External Data in Vespa Embedders
Many ONNX models exceed the 2GB protobuf limit and store weights in external data files. Vespa now supports these models for embedders.
Asymmetric Retrieval: Spend on Docs, Embed your Queries for Free
Documents are embedded once — worth the spend for maximum quality. Queries hit you on every request. This is what drives your cost at scale. Asymmetric retrieval with Voyage AI...
How Metal AI Built an Agent-Driven Intelligence Platform on Vespa Cloud
How Metal built an AI-Native Intelligence Platform on Vespa.ai, where 95% of retrieval is handled by AI agents.
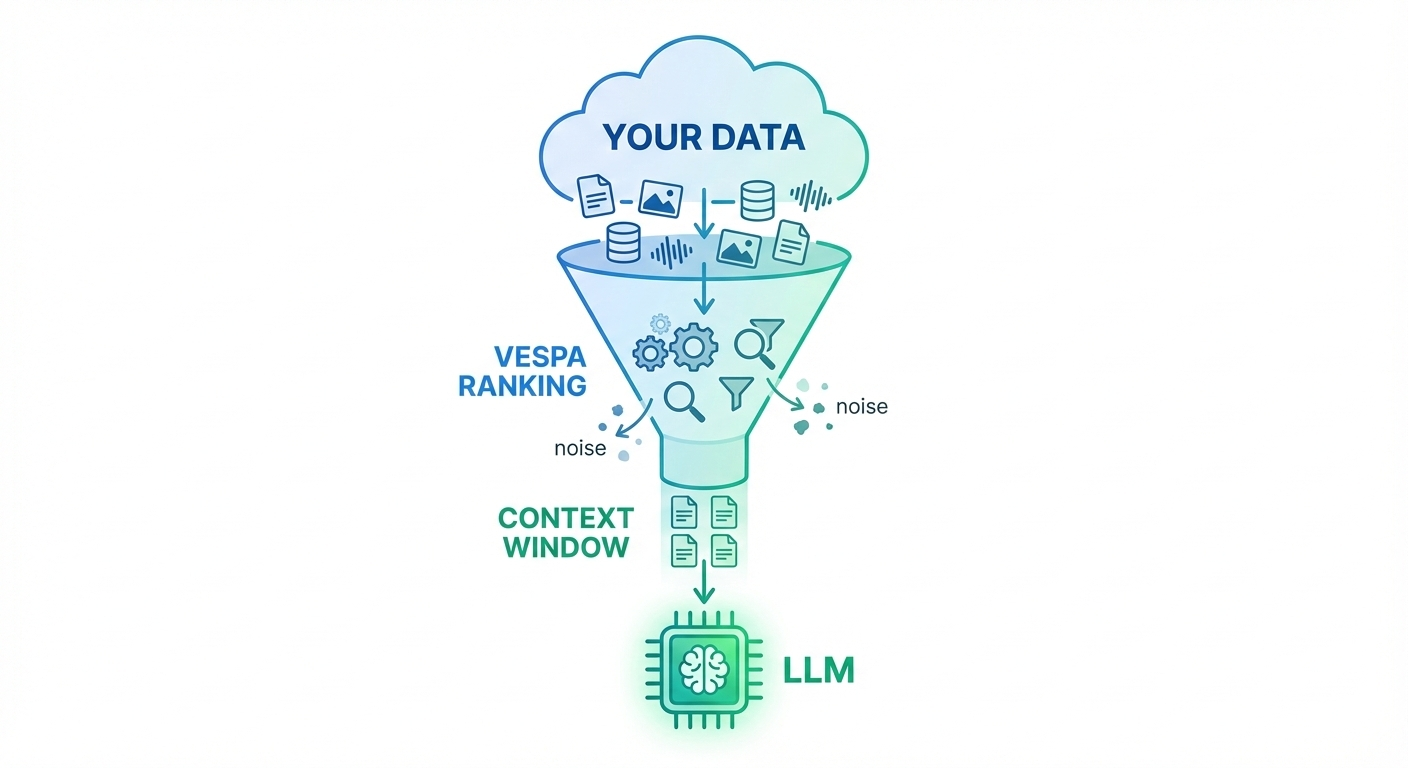
Build a High-Quality RAG App on Vespa Cloud in 15 Minutes
Retrieval-Augmented Generation (RAG) allows an LLM to answer questions using your data at query time. On their own, LLMs are powerful but limited: they can hallucinate, they have a fixed...
Vespa Newsletter, February 2026
Advances in Vespa's retrieval performance, flexibility, and developer productivity.
Nexla + Vespa, The Power Duo for AI-Ready Data Pipelines
Nexla solves data readiness. Vespa solves intelligence and precision at scale. Together, they give teams a clean, practical path from raw enterprise data to real-time AI applications.
Clarm: Agentic AI-powered Sales for Developers with Vespa Cloud
Agentic AI-powered Sales for Developers, built on Vespa
« Prev
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Next »
Never miss a
story
from us, subscribe to our newsletter
Subscribe