{ }
Blog
Vespa.ai
Docs
Subscribe
Vespa Blog
We Make AI Work
All Stories
Exploring Hierarchical Navigable Small World
This summer, we got to explore Hierarchical Navigable Small World, a foreign concept for us both - we’ll take you on the journey we went through.
Introducing Private Embedding Models in Vespa Cloud
We are thrilled to announce a new enhancement to Vespa Cloud, native support for private Hugging Face embedders!
Building the Next-Gen Diligence Engine: Why 8byte is Partnering with Vespa.ai
8byte is building a next-gen diligence engine for private equity, powered by Vespa.ai’s sub-100 ms search. The result: real-time risk scoring, 5× analyst throughput, and 50% lower infrastructure costs.
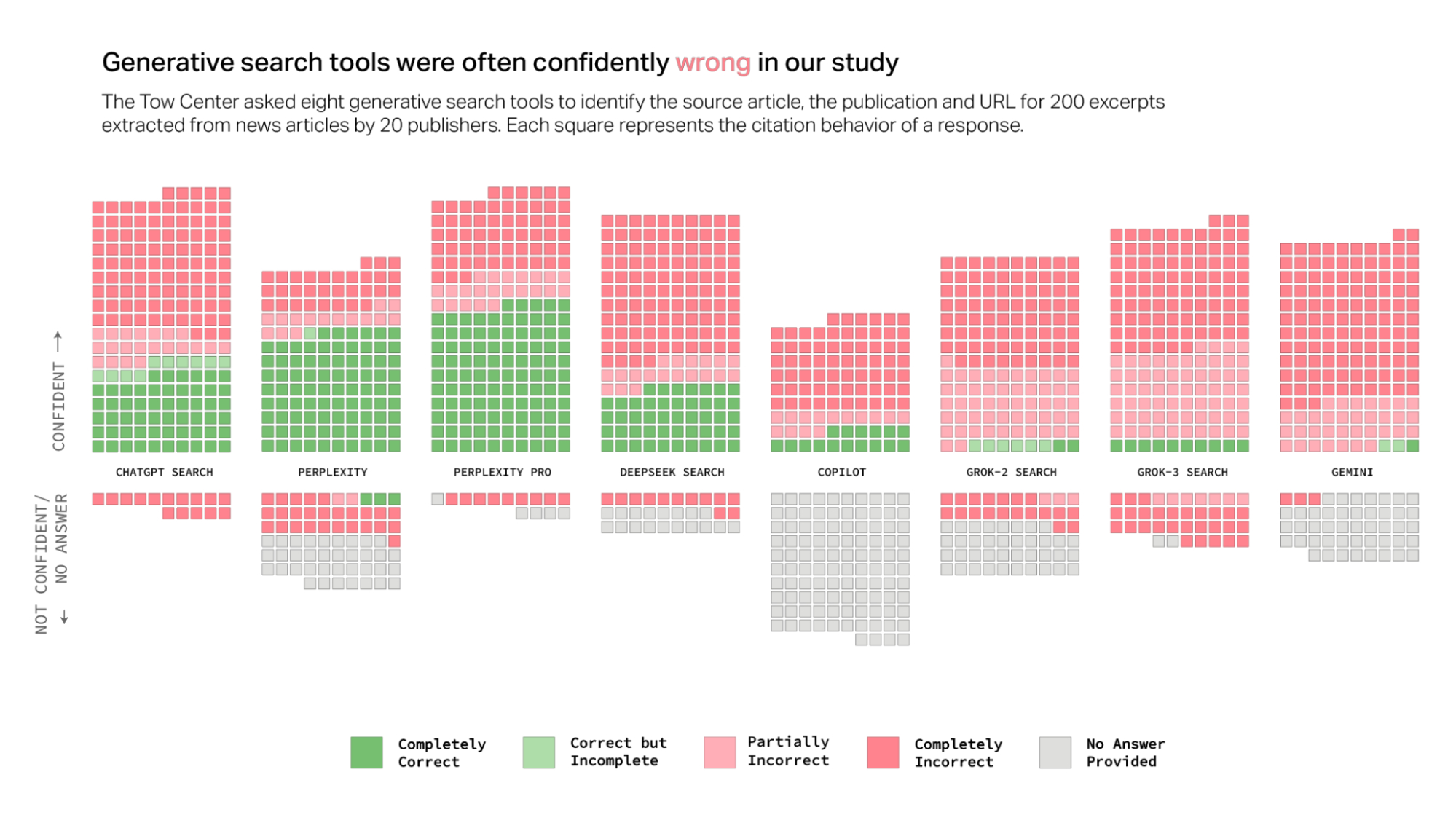
The secret to Perplexity's lead in AI Search
How can Perplexity crush it when they are using the models of their competitors?
Vespa Implementation Services: From Migration to Production Scale
Drawing from real-world experience, we offer flexible service packages tailored to common Vespa implementation challenges, allowing organizations to engage based on their unique needs and stage.
Unlocking Next-Gen RAG Applications for the Enterprise: Connecting Snowflake and Vespa.ai
Why intelligent RAG systems need both Snowflake (for structured scale) and Vespa (for high-performance retrieval across unstructured text.
Vespa Quickstart - How to build an Application with Vespa
Get started with Vespa and set up your first application. Build your first Vespa instance using Python.
The RAG Blueprint
An open source sample application that contains everything you need to create a RAG solution with world-class accuracy and infinite scalability.
Vespa Newsletter, June 2025
Advances in Vespa features and performance include layered ranking for RAG applications, chunking, and facet filtering.
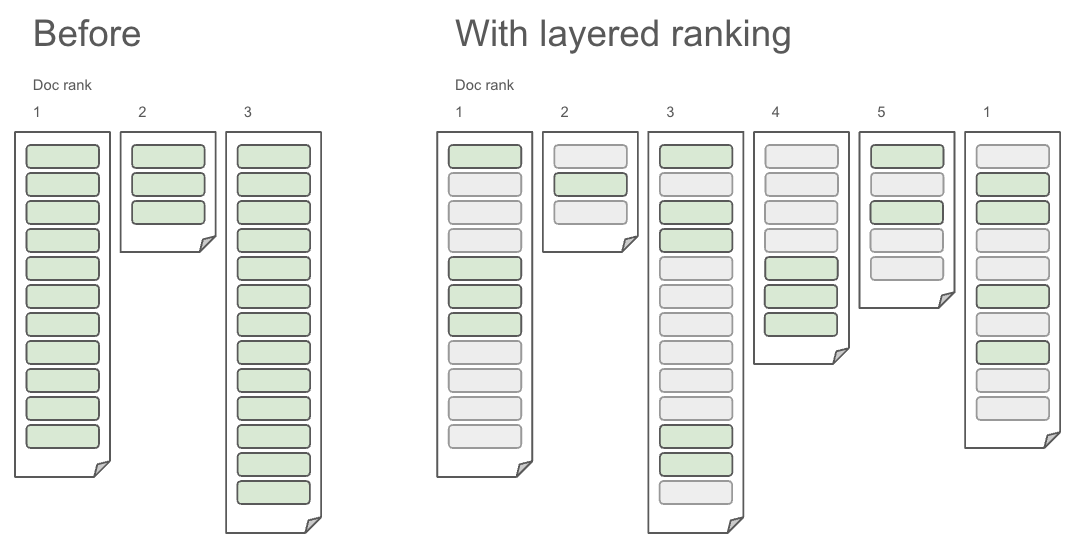
Introducing layered ranking for RAG applications
Introducing layered ranking: The missing piece for context engineering at scale.
Image generated using OpenAI.
Search me if You Can: Building the Next Generation Advanced RAG Solution in Lifesciences
It is now the age of RAG, semantic + hybrid search, domain reasoning, powering copilots and AI agents. Lets see how - lets build your next Scientific Search engine!
Beyond Vectors: AI for Life Sciences Needs More Than Vectors—Here’s Why
Learn how how Vespa’s native tensor capabilities are redefining AI-powered search and retrieval in life sciences, enabling faster, more accurate insights across complex, multimodal scientific data.
« Prev
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Next »
Never miss a
story
from us, subscribe to our newsletter
Subscribe