{ }
Blog
Vespa.ai
Docs
Subscribe
Vespa Blog
We Make AI Work
All Stories
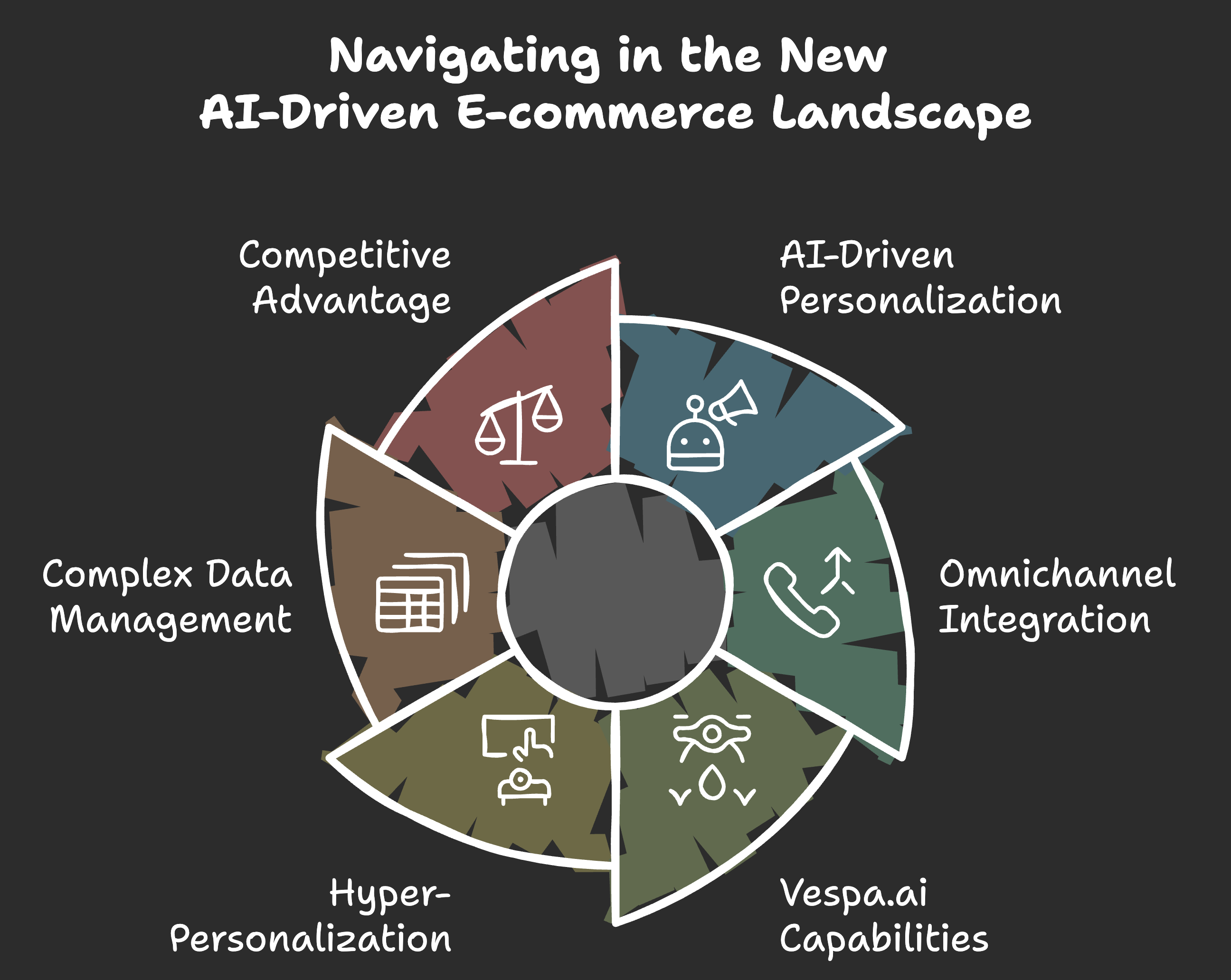
Navigating in the New AI-Driven E-commerce Landscape
This AI-driven ecommerce evolution is driven by consumer’s increasing demand for personalized experiences, real-time interactions, and seamless omnichannel integration.
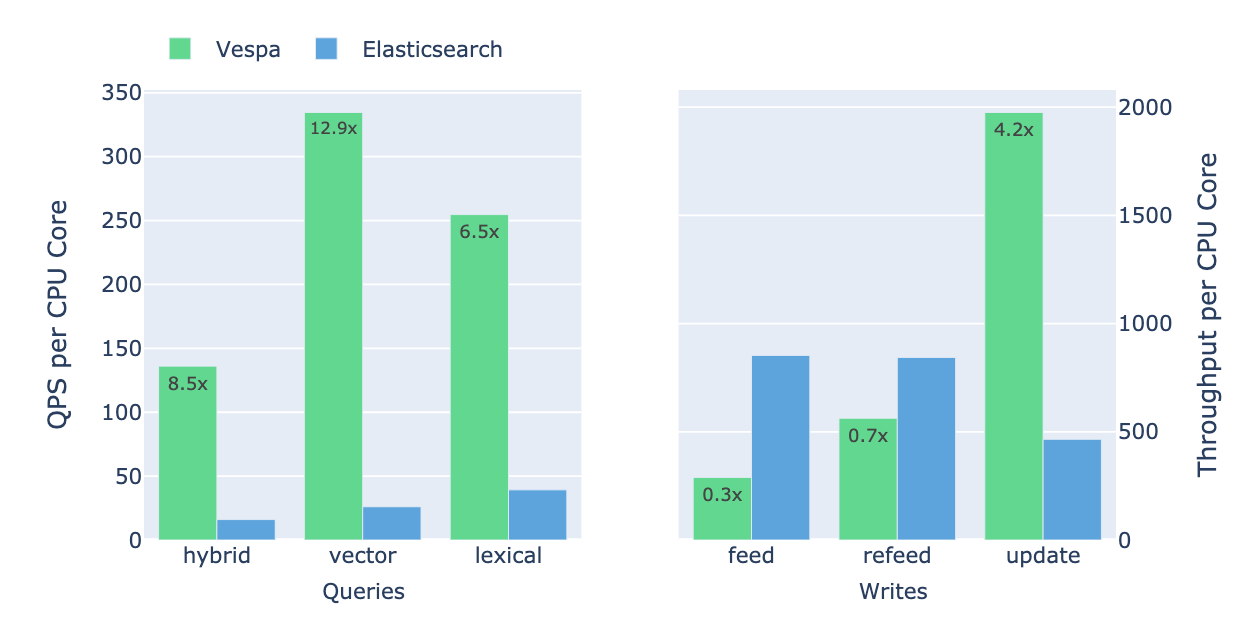
Elasticsearch vs Vespa Performance Comparison
Detailed report of a comprehensive performance comparison between Vespa and Elasticsearch for an e-commerce search application.
How Generative AI Is Changing E-commerce
According to ESG, 41% of retail respondents in a 2024 survey are either already pursuing or planning to pursue AI-powered product recommendations.
Photo by
Catherine Kay Greenup
on
Unsplash
Vector search beyond the database
The purpose of using vectors is to improve quality, but that takes much more than a similarity lookup. Search engines are built for that, databases are not.
Vespa Newsletter, October 2024
Advances in Vespa features and performance include Global significance models and Nearest Neighbor Search with multiple sparse tensor dimensions.
Vespa.ai: The “Sleeping Giant” Powering Next-Gen Search and Recommendations
Vespa has quietly led the way in search and recommendation systems, providing the backbone for some of today’s most advanced applications.
Deploying RAG at Scale: Key Questions for Vendors
Retrieval-augmented generation (RAG) has emerged as a vital technology for organizations embracing generative AI.
Announcing support for global significance models
A global significance model improves ranking for streaming search and ensures deterministic search results in multi-node deployments.
Vinted moves from Elasticsearch to Vespa
With Vespa, Vinted managed to halve the number of servers, slash query latency by 2.5x, indexing latency by 3x, and increase ranking depth by more than 3x.
Vespa Newsletter, September 2024
Advances in Vespa features and performance include Optimized MaxSim with Hamming distance, IDE Support, Pyvespa features, and new notebooks with ColPali examples.
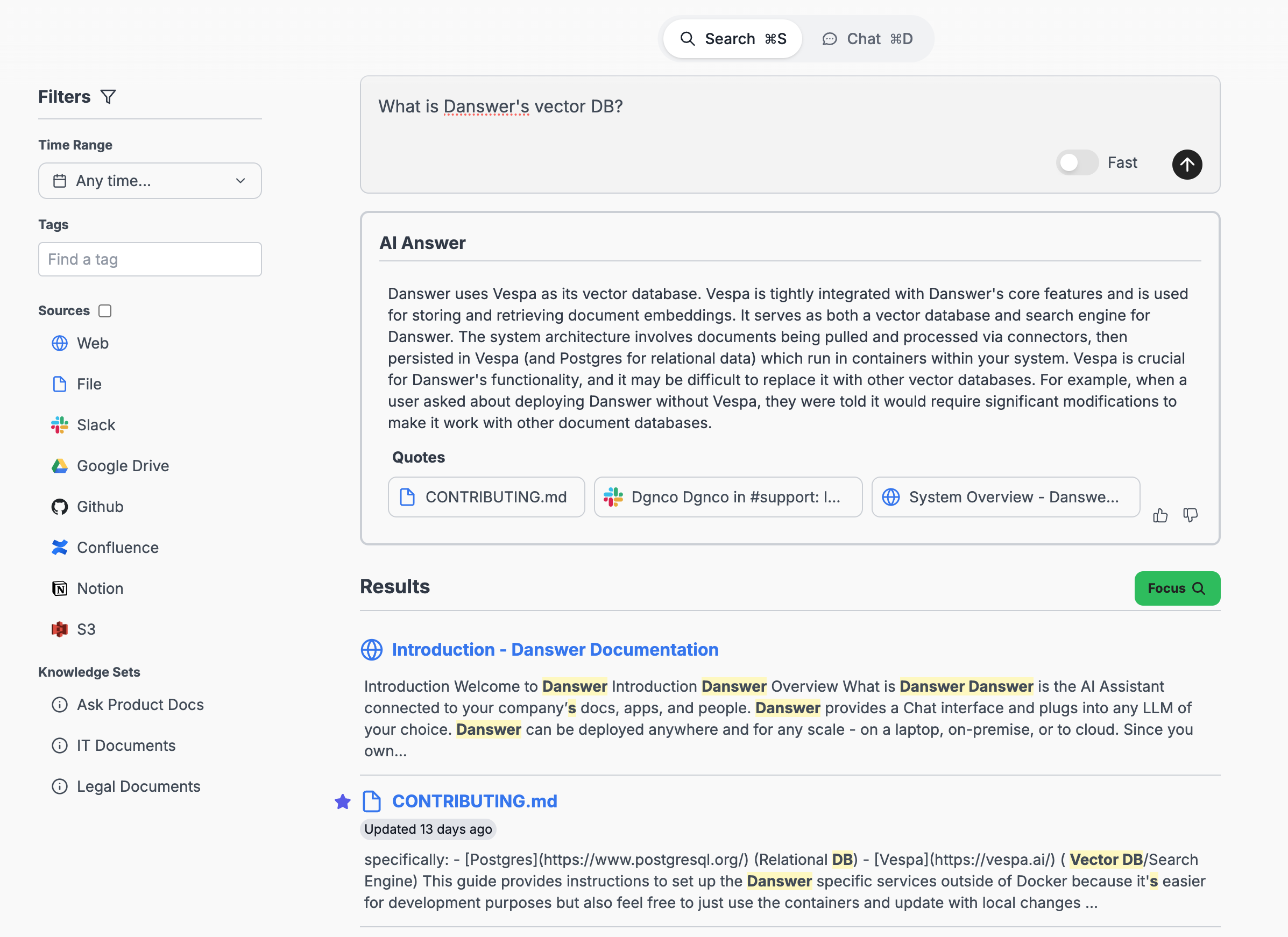
Why Danswer - the biggest open source project in Enterprise Search - uses Vespa
Why we as a team decided to migrate to Vespa and why it was worth it even when it meant ripping out the core of our previous stack.
AI Needs More Than a Vector Database
An AI database is a multipurpose platform that manages both structured and unstructured data and applies AI models to various data formats.
« Prev
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Next »
Never miss a
story
from us, subscribe to our newsletter
Subscribe