{ }
Blog
Vespa.ai
Docs
Subscribe
Vespa Blog
We Make AI Work
All Stories
Photo by
Rafael Drück
on
Unsplash
Representing BGE embedding models in Vespa using bfloat16
This post demonstrates how to use recently announced BGE embedding models in Vespa. We evaluate the effectiveness of two BGE variants on the BEIR trec-covid dataset. Finally, we demonstrate how...
Photo by
Appic
on
Unsplash
Accelerating Transformer-based Embedding Retrieval with Vespa
In this post, we’ll see how to accelerate embedding inference and retrieval with little impact on quality. We’ll take a holistic approach and deep-dive into both aspects of an embedding...
Photo by
Bruno Martins
on
Unsplash
Simplify Search with Multilingual Embedding Models
This blog post presents and shows how to represent a robust multilingual embedding model of the E5 family in Vespa.
Photo by
Ilya Pavlov
on
Unsplash
Vespa Newsletter, July 2023
Advances in Vespa features and performance include Vector Streaming Search, GPU accelerated embeddings, Huggingface models and a solution to MIPS using a nearest neighbor search.
Leveraging frozen embeddings in Vespa with SentenceTransformers
How to implement frozen embeddings approach in Vespa using SentenceTransformers library and optimize your search application at the same time.
Photo by
Nicole Avagliano
on
Unsplash
Announcing Maximum Inner Product Search
Vespa can now solve Maximum Inner Product Search problems using an internal transformation to a Nearest Neighbor search. This is enabled by the new dotproduct distance metric.
Photo by
Marc Sendra Martorell
on
Unsplash
Announcing vector streaming search: AI assistants at scale without breaking the bank
With personal data, you need complete results at low cost, something vector databases cannot provide. Vespa's new vector streaming search delivers complete results at a fraction of the cost.
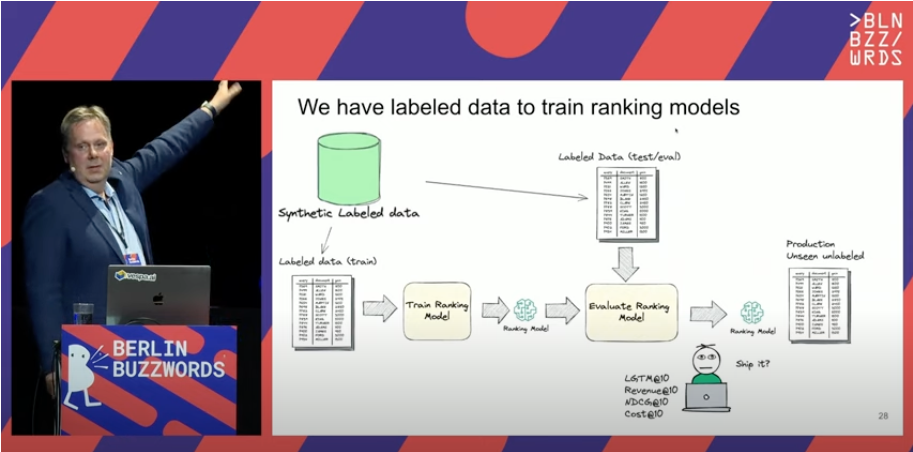
Vespa at Berlin Buzzwords 2023
Summarizing Berlin Buzzwords 2023, Germany’s most exciting conference on storing, processing, streaming and searching large amounts of digital data.
Photo by
vnwayne fan
on
Unsplash
Enhancing Vespa’s Embedding Management Capabilities
We are thrilled to announce significant updates to Vespa’s support for inference with text embedding models that maps texts into vector representations.
Photo by
Scott Graham
on
Unsplash
Vespa Newsletter, May 2023
Advances in Vespa features and performance include multi-vector HNSW Indexing, global-phase re-ranking, LangChain support, improved bfloat16 throughput, and new document feed/export features in the Vespa CLI.
Photo by
Shiro hatori
on
Unsplash
High performance feeding with Vespa CLI
Vespa CLI can now feed large sets of documents to Vespa efficiently.
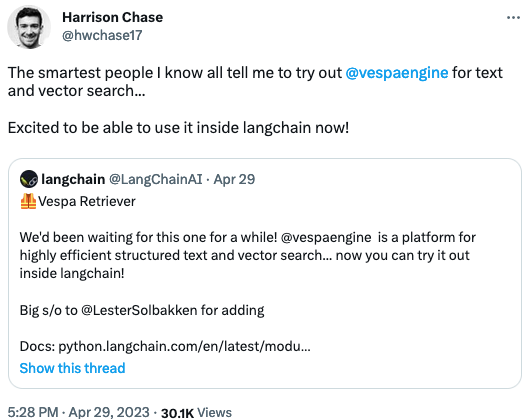
Vespa support in langchain
Langchain now comes with a Vespa retriever.
« Prev
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Next »
Never miss a
story
from us, subscribe to our newsletter
Subscribe