{ }
Blog
Vespa.ai
Docs
Subscribe
Vespa Blog
We Make AI Work
All Stories
AI in Insurance with Vespa.ai
The evolution of language models combined with state-of-the-art information retrieval is reshaping the insurance landscape.
Vespa Newsletter, January 2025
Advances in Vespa features and performance include Pyvespa Querybuilder, Vespa input/output plugins for Logstash, ModernBERT models, and Vespa CLI multi-get.
Vespa with Logstash Recipes
Tutorials on feeding data to Vespa from CSV files, PostgreSQL, Kafka, Elasticsearch and another Vespa.
Photo by
Samson
on
Unsplash
Architecture Inversion: Scale By Moving Computation Not Data
Have you ever wondered how the world’s largest internet and social media companies can deliver algorithmic content to so many users so fast?
Photo by
Simon Hurry
on
Unsplash
Shrinking Embeddings for Speed and Accuracy in AI Models
How MRL and BQL Make AI-Powered Representations Efficient
Photo by
Firmbee.com
on
Unsplash
Transforming the Future of Information Retrieval with ColPali
ColPali simplifies and enhances information retrieval from complex, visually rich documents, transforming retrieval-augmented generation
Vespa Newsletter, December 2024
Advances in Vespa features and performance include Elasticsearch vs Vespa Performance Comparison, Vision RAG and Binarizing Vectors
Securely Storing Secrets on Vespa Cloud
Learn how to securely store and manage sensitive secrets in your Vespa Cloud applications using Vespa's built-in secret store.
Why Norway’s Environmental Commitment Reflects in Vespa.ai’s Values
Exploring how Vespa.ai exemplifies Norway's commitment to sustainability through efficient technology.
Vespa for Dummies
A beginner's guide to Vespa, exploring its role in information retrieval and its advantages for enterprise AI applications.
A Benchmark for Modernizing Elasticsearch with Vespa
Discover how Vespa outperforms Elasticsearch in query efficiency, scalability, and operational costs, making it a robust choice for modern eCommerce search solutions.
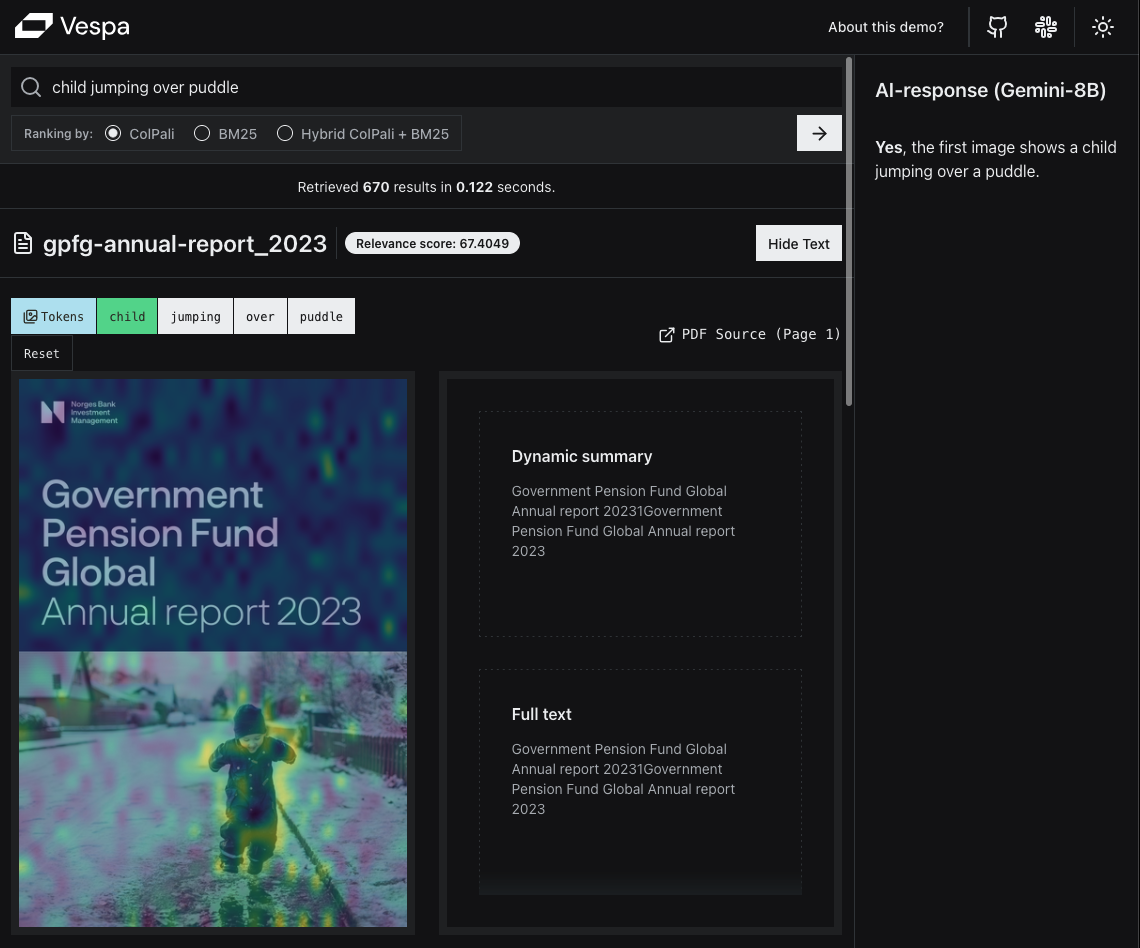
Visual RAG over PDFs with Vespa - A demo application in Python
This is a technical blog post on developing an end-to-end Visual RAG application powered by Vespa. It has link to a live demo application, and will walk you through why...
« Prev
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Next »
Never miss a
story
from us, subscribe to our newsletter
Subscribe