

Photo by Polina Kuzovkova on Unsplash
We announce a long-context ColBERT implementation in Vespa, enabling explainable semantic search using token-level vector representations for long documents. By extending ColBERT’s late interactions to late-context-window interactions, we give ColBERT a larger context for long-document scoring.
This post:
- Overview of single-vector embedding models and their limitations in long-context retrieval and why ColBERT excels in overcoming these limitations
- Extending ColBERT’s late-interaction scoring for long-context retrieval
- Evaluation of Long-ColBERT’s performance on the recently introduced MLDR long-document retrieval dataset
- Executive summary and an extensive FAQ
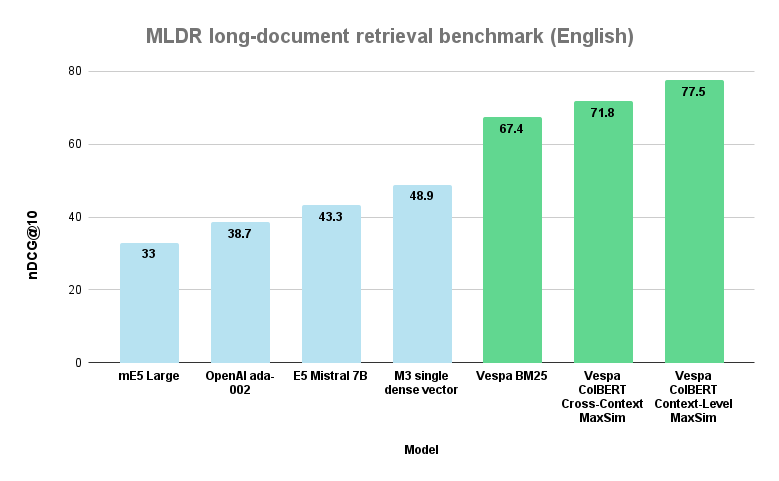
Vespa methods evaluated in this blog post versus popular long-context single-vector embedding models.
Single-vector text embedding models
Typical text embedding models use a pooling method, like averaging, on the output token vectors from the final layer of the Transformer-based embedder model. The pooling generates a lone vector that stands for all the tokens in the input context window of the embedder model.
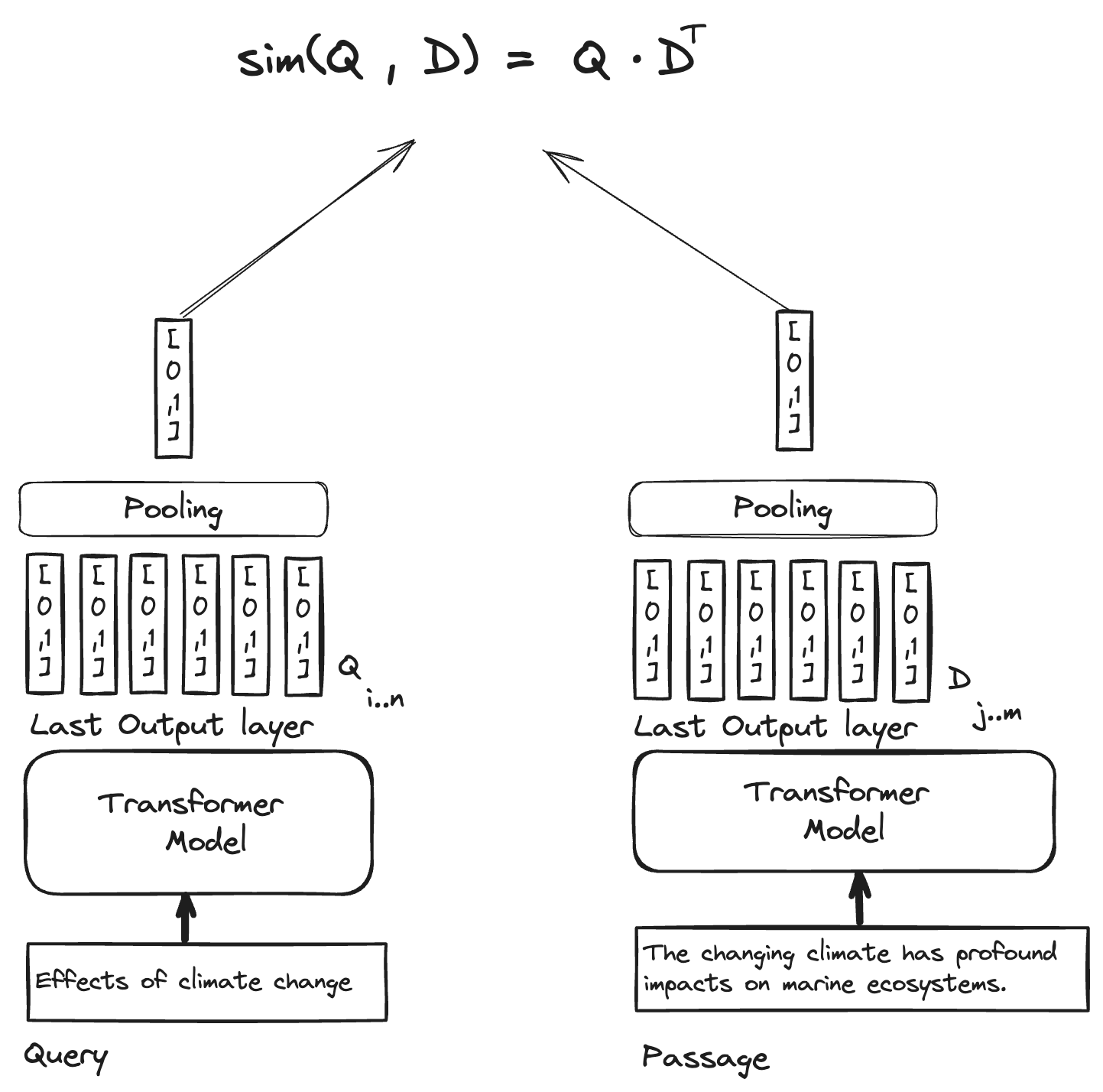
The similarity scoring between a query and a document text only uses this lone vector representation. Intuitively, this representation gets more diluted the longer the text is. In simpler terms, as the text gets longer, the representation becomes less precise—think of it like trying to sum up a whole passage (or a book) with just one word. A significant focus has been addressing longer input text contexts for embedding models because many retrieval tasks require searching longer texts. Traditional embedding models, such as those based on the vanilla BERT architecture, are usually constrained to 512 tokens, which creates challenges for practitioners who need to build search applications that need to search much longer documents than that. Recent enhancements related to the attention mechanisms of Transformer models have made it possible to scale the maximum number of input tokens to over 8,000. By reducing the FLOPs required during embedder inference, obtaining long text embeddings is now more practical for the GPU-poor.
A critical question is whether text embedding models that accept many tokens will provide a good text representation for information retrieval. For example, in the early days of neural search representations, practitioners could use Word2vec and obtain a single vector representation of a long text by averaging all the word vectors. This simple approach would give you an inference-wise extremely cheap text embedding model with infinite context length. Still, anyone who tried that would report that simple traditional baselines like BM25 would easily outperform it for most search tasks.
There are two reasons long-context embedding models fail short of simple baselines:
Lack of long context retrieval training data
Few datasets are available to pre-train the embedding model for long context retrieval. Most embedding models are pre-trained using contrastive loss using mined sentence pair datasets with fewer than 100 tokens and then fine-tuned on labeled data with similar length characteristics. When using such an embedding model in a zero-shot (without fine-tuning) on your data, with considerably more tokens, it will fail to perform well for search. Even for short texts, simple baselines in zero-shot settings easily outperform single-vector embedding models even for the same short-length characteristics.
The pooling operation into a single vector
The pooling operation condenses the original last layer token vectors. These output vectors are contextualized via the Transformer encoder’s bidirectional token attention. However, when these vector representations are pooled into a single vector, the resulting representation of the text becomes blurred. While this representation may serve various purposes (clustering, classification), it may not be suitable for high-precision search retrieval where we normally want to optimize the precision of the first k-retrieved results.
ColBERT versus regular text embedding models
ColBERT represents the query and document by the contextualized token vectors without the pooling operation of regular embedding models. This per-token vector representation enables a more detailed similarity comparison between the query and the passage representation, allowing each query token to interact with all document tokens.
Each query token vector representation is contextualized by the other query token vectors, the same for the document token vector representations. By separating the query and document representations, we can pre-process the documents in the corpus that we want to search and then at query time perform the late interaction scoring.
Extending ColBERT for long-context search in Vespa
The official CoLBERT model checkpoint uses vanilla BERT as the base model, with a maximum context window size of 512 tokens. Furthermore, the model checkpoint is fine-tuned using a single dataset with short passage-length texts of up to 100 tokens.
To adapt CoLBERT for longer contexts, we must consider these constraints and perform a context window sliding operation over longer text to obtain contextualized token vectors for the entire document. We can implement this sliding window by splitting the longer text into sizes similar in length to what ColBERT checkpoint was trained on. We can index these text splits into Vespa using Vespa’s array field type. The collection type support in Vespa avoids splitting the longer text context across multiple different retrievable units like with naive single-vector databases that only can handle one vector and a single string chunk per retrievable unit. This unique Vespa functionality is handy in RAG pipelines as it provides easy access to the full context of the retrievable document, including potential metadata.
schema doc {
document doc {
field text type array<string> {
indexing: summary | index
index: enable-bm25
}
}
field colbert type tensor<int8>(context{}, token{}, v[16]) {
indexing: input text | embed colbert context | attribute
attribute: paged
}
}
Notice the Vespa tensor
definition for the colbert document representation; we use the
compressed token vector version (details in the Colbert embedder
blog post)
to represent each token of the entire document as a 16-dimensional
int8 vector v (Vespa tensor
types)
The mapped dimension context represents the context window, while
the mapped token dimension represents the token position in the
sliding context window. Note that token is the position, not the
encoded token id, as that would reduce the representation to a bag
of unique tokens, which is not the case. The same token
occurring multiple times in a context window is encoded differently.
Using mixed Vespa tensors, combining mapped dimensions with dense (indexed) dimensions allows for storing variable length context windows per document and a variable number of tokens per context window. The paged attribute option allows the operative system to page data in and out from disk-based storage (at the price of higher random access latency).
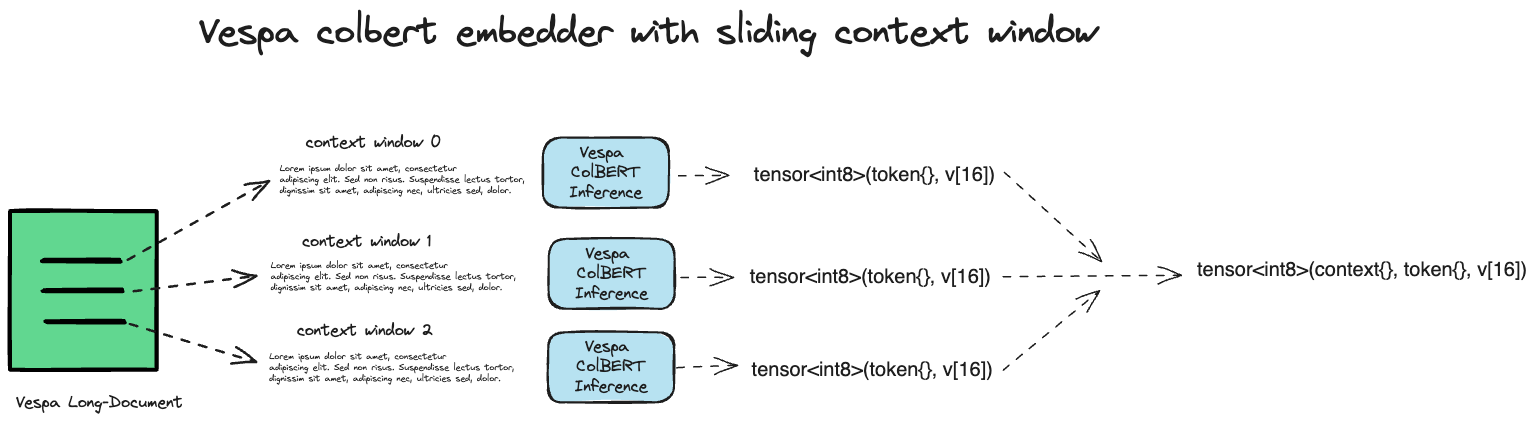 Vespa embedder illustration for collection type inputs, invoking the embedder and producing the multi-dimensional colbert tensor.
Vespa embedder illustration for collection type inputs, invoking the embedder and producing the multi-dimensional colbert tensor.
For example, with a sliding context window without overlap (stride), we will retain 2K token-level vectors for a 2K text. Note that the token-level vectors across different context windows are not contextualized by encoder attention. However, they are still usable for the late-interaction ColBERT scoring function (MaxSim), which we can extend to work across long-document context windows.
Scoring with long-context ColBERT representations
We have two promising options for performing the MaxSim computation of ColBERT for long-document context windows.
Both methods can be expressed using Vespa tensor computation expressions in Vespa ranking without having to change the colbert document embedding representation, and for both methods, the query input tensor is the same.
- A local context scoring model which scores each unique context window independently without considering the global context (all token-level vectors). This is logically equivalent to splitting context windows into separate retrievable units and performing the original late-interaction MaxSim scoring function.
- A global context scoring model that scores across the unique context windows (illustrated below).
Both long-context late-interaction scoring methods have similar FLOPS requirements.
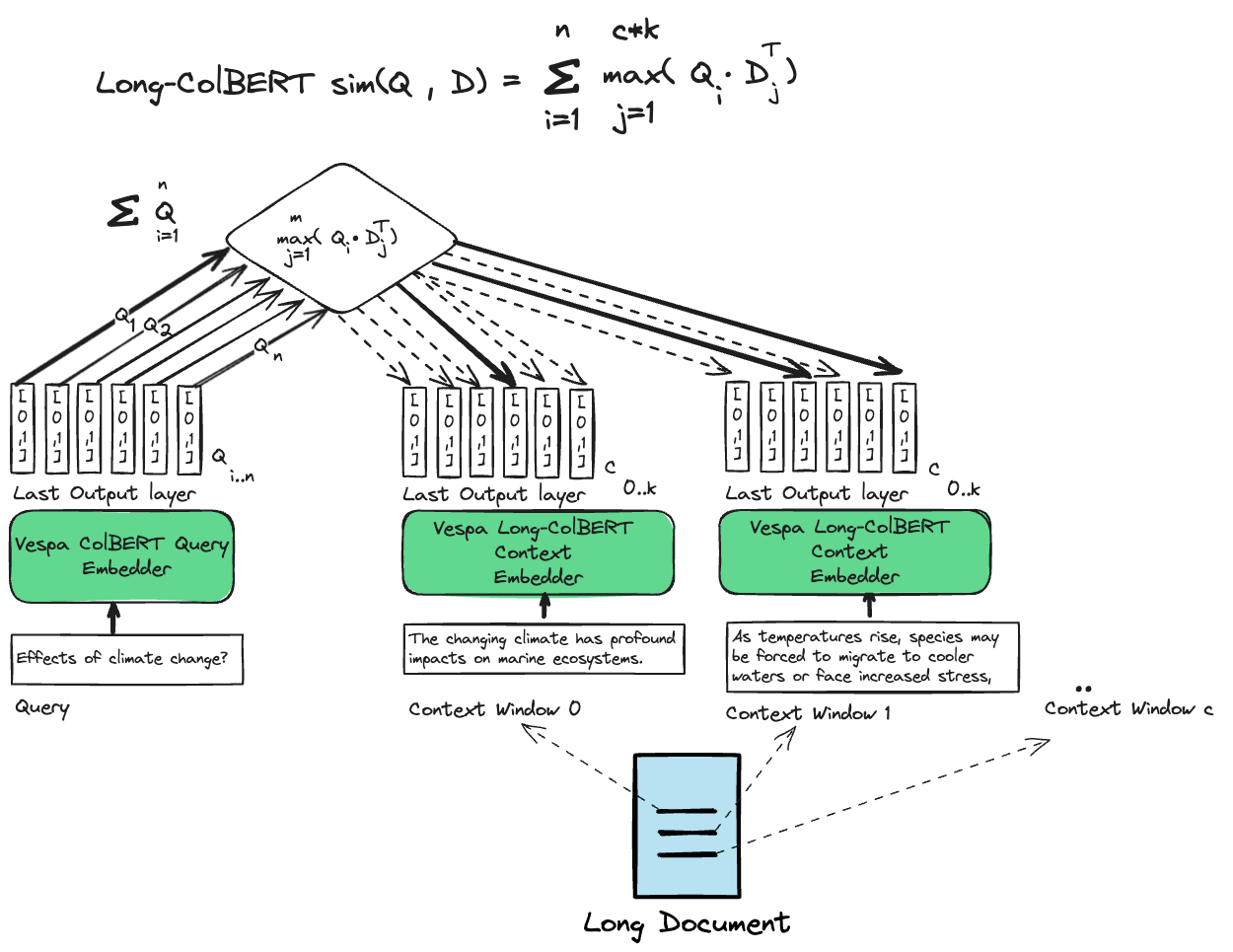
Illustration of the ColBERT model representation and extending the late-interaction similarity expression (MaxSim) to global cross-context late-interaction.
To understand the following sections, we touch base on Vespa tensors. We have two Vespa tensors produced by the Vespa colbert embedder at either query or indexing time.
query(qt) tensor<float>(querytoken{}, v[128])
attribute(colbert) tensor<int8>(context{}, token{}, v[16])
The following uses the unpack_bits
function to unpack the compressed tensor into tensor<float>(context{},
token{), v[128]) :
unpack_bits(attribute(colbert))
After this uncompressing step, we have two tensors with one shared
axis name v with 128 dimensions. With these two representations,
we can express the proposed late-interaction scoring methods.
tensor<float>(querytoken{}, v[128])
tensor<float>(context{}, token{}, v[128])
Context-level MaxSim
We can compute the MaxSim over all the context representations and aggregate the scores using max aggregation to represent the document score. We express this context-level MaxSim scoring with the following Vespa rank-profile using Vespa tensor computation expressions.
rank-profile colbert-max-sim-context-level inherits bm25 {
inputs {
query(qt) tensor<float>(querytoken{}, v[128])
}
function max_sim_per_context() {
expression {
sum(
reduce(
sum(query(qt) * unpack_bits(attribute(colbert)) , v),
max, token
),
querytoken
)
}
}
second-phase {
expression { reduce(max_sim_per_context, max, context) }
}
}
This computes the MaxSim per context window and reduces all the context window MaxSim scores using max aggregation to represent the document score. This approach also allows us to return not only all the original text chunks, but also all the context-level scores using match-features to the rank-profile:
match-features: max_sim_per_context
This will then return a tensor of the type tensor<float>(context{})
with each hit. This allows RAG pipelines to extract, for example, the
K best scoring windows from the document - K depending on the
context length limitations of the last generative step in an
RAG pipeline.
Cross-Context MaxSim
Since we have token vectors for all tokens across all context windows, we can also perform the MaxSim operation across these context windows. This scoring is expressed by finding the maximum token vector score independent of the context for each query vector. We can express this cross-context MaxSim scoring with the following Vespa rank-profile.
rank-profile colbert-max-sim-cross-context inherits bm25 {
inputs {
query(qt) tensor<float>(querytoken{}, v[128])
}
function unpack() {
expression: unpack_bits(attribute(colbert))
}
function cross_max_sim() {
expression {
sum(
reduce(
sum(
query(qt) * unpack_bits(attribute(colbert)) , v),
max, token, context
),
querytoken
)
}
}
second-phase {
expression { cross_max_sim }
}
}
In this case, we change the inner reduce to aggregate using maximum,
first on the token level and then on the context level. This
expression allows high-scoring token
vectors across the document context windows to contribute to the
overall document score.
The cross-context scoring could be helpful when the relevant information is spread across multiple context segments in the document, compared to the localized context version focusing purely on a single context segment.
Experiments & Evaluation
We deploy the long-context-colbert Vespa sample application on Vespa Cloud using two nodes with the following clusters and resources
One Vespa Stateless container cluster with GPU for accelerated ColBERT embedder inference:
<resources vcpu="4" memory="16Gb" disk="125Gb">
<gpu count="1" memory="16Gb"/>
</resources>
One Vespa stateful content cluster with one node:
<resources vcpu="16.0"
memory="32Gb" architecture="arm64"
storage-type="local" disk="950Gb">
</resources>
For long-contexts, where we run multiple inferences with the ColBERT model per document, we highly recommend using instances with GPU acceleration available. Vespa Cloud also supports autoscaling with GPU instances for stateless Vespa container clusters.
For candidate retrieval (shortlisting), we use Vespa’s support for efficient retrieval using BM25 scoring, this shortlists the number of documents that we score using the advanced ColBERT late-interaction scoring functions. We chose BM25 because it is a strong zero-shot baseline for long-context retrieval; it’s designed to handle variable-length texts.
We use the following bm25 Vespa rank profile definition as our baseline.
When used on an array collection of context strings like this, Vespa
uses all the array elements as if they were a bag of text (single
field).
rank-profile bm25 {
rank-properties {
bm25(text).k1: 0.9
bm25(text).b: 0.4
}
first-phase {
expression: bm25(text)
}
}
We evaluate the proposed extended-context late-interaction scoring using the newly released MLDR dataset, using the English split, which contains 200K long texts sampled from Wikipedia with associated 800 test queries.
We use the precision-oriented nDCG@10 metric to
measure effectiveness. For all experiments, we use a re-ranking
count of 400. The shortlist retrieval phase uses Vespa’s weakAnd
implementation. The top-k scoring documents
by this phase are then re-ranked with the ColBERT representations.
MLDR English split Dataset characteristics
| Queries | 800 |
| Query relevance judgment pairs | 800 (binary relevance) |
| Documents | 200K |
| Document length (wordpiece tokens) | 2950 |
| Query length (wordpiece tokens) | 17 |
For the sliding context window functionality, in our experiment, we use a LangChain text splitter implementation with 0 overlap and 1536 characters. This gives us on average 11.7 context windows per document with on average 251 wordpiece tokens. We did not experiment further with different window sizes or overlap.
Evaluation results
Summarizing the results, nDCG@10 metrics for non-Vespa
implementations are from BGE M3-Embedding: Multi-Lingual,
Multi-Functionality, Multi-Granularity Text Embeddings Through
Self-Knowledge Distillation.
First, we can see that the simple Vespa BM25 method outperforms all other methods reported in the M3-Embedding paper for long-document retrieval. This observation is essential, as all the text embedding models have a high computational cost related to embedding inference and building vector search indexes for efficient retrieval. For example, the E5-Mistral model with 7B parameters and an embedding dimensionality of 4096 is one of the best performing embedding models on the MTEB, but significantly underperforms the BM25 baseline on this long context benchmark. Similarly, the popular OpenAI text-embedding-ada-002 with 1536 dimensions performs even worse on this long-document dataset. Two important observations:
- Strong performance on the MTEB leaderboard does not necessarily generalize to long context retrieval.
- Models might overfit the datasets included in the MTEB benchmark. MLDR is a recently announced benchmark collection, making this zero-shot evaluation more realistic.
Both ColBERT scoring methods perform better than the baseline and outperform single-vector models by a large margin. On this dataset, the context-level MaxSim is by a large margin the most effective scoring function, with the cross-context MaxSim a solid second place.
This is a single dataset, and the result might be impacted by how the dataset was constructed; which of the two proposed methods that will work best on your data will depend on the search task. For example, if a single context window can answer the query perfectly, there is no need to consider the cross-context information. On the other hand, relevant information to answer the question might be in multiple context windows.
Ablation study on re-ranking depths and serving performance
In the following section, we evaluate the impact of changing the
re-ranking depth for the most effective method using the context-level
MaxSim. The query latency is measured end-to-end, including
embedding inference, retrieval, and re-ranking. We report the
average latency of all 800 queries without any concurrency. Note
that this experiment uses all available CPU threads for ranking
(16). Interestingly, we can improve nDCG@10 significantly
over BM25 by re-ordering just the top ten documents below 50ms.
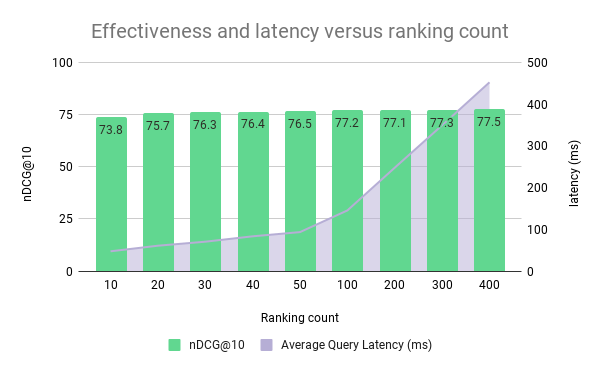
Impact of re-ranking count on latency and nDCG@10. The change in re-ranking window increments makes the latency line look like a hockey stick pattern but is a linear scaling relationship.
Changing the re-ranking count allows us to trade effectiveness versus efficiency; reducing the number of shortlisted candidates from the BM25 scoring decreases the FLOPS involved in the ColBERT late-interaction scoring.
Summary
Our assessment of Long-ColBERT’s performance on the MLDR dataset underscores its effectiveness in retrieving long documents, with both context-level MaxSim and cross-context-level MaxSim scoring methods surpassing other methods, including the baseline BM25 approach.
The Long-ColBERT effectiveness is promising, as this hybrid approach, where initial candidate retrieval uses the entire document text followed by a re-ranking refinement using neural ColBERT representations.
It reduces complexity and avoids splitting texts into many retrievable units, as with single-vector databases like Pinecone, Weaviate, or Qdrant. In RAG pipelines with larger generative LLMs with ever-increasing context limits, having easy access to the entire page/document content in a single retrievable unit can increase the quality of the generative step.
Furthermore, we highlight the absence of the need to construct index structures for efficient vector-based retrieval. Instead, we utilize pre-computed vector representations during ranking phases, enhancing storage-tiering economics by enabling offloading vectors to disk using Vespa’s paged attribute support.
Offloading the neural representations to disk, in conjunction with the efficient keyword retrieval method, makes this hybrid retrieval approach cost-efficient for large collections of documents.
Looking ahead, we anticipate experimenting with ColBERT models based on encoder models featuring larger context windows. The recent release of Jina’s open-source 8K context length ColBERT model presents an exciting opportunity to expand the context window for both late-interaction scoring methods evaluated in this blog post.
FAQ
Does Long-ColBERT eliminate the need for text chunking? No, because the encoder-based model has a context length limitation. What we avoid with Long-ColBERT in Vespa is splitting long documents into separate retrievable units like with single-vector databases. In addition, since we represent all the token vectors across context windows, we can choose how we compute the late-interaction similarity function.
Why is BM25 still a strong baseline? Because BM25 builds a statistical model of your data, and lets face it, the exact words that the user types are still vital for high-precision search.
Vespa supports multiple retrieval and ranking methods, so unlike other vendors with fewer capabilities, we want to help you build search applications that perform well using the best possible method.
We will not hide simpler baselines to sell storage and compute units without significant benefits for the application.
What are the tradeoffs here? It must be more expensive than single-vector models? From a compute FLOPS perspective, yes, the late-interaction similarity calculations have a much higher FLOPS footprint than models that compress everything into a single vector representation. It boils down to an effectiveness versus efficiency tradeoff.
I have many structured text fields like product title and brand description, can I use ColBERT in Vespa? Yes, you can either embed the concatenation of the fields, or have several colbert tensors, one per structured field. The latter allows you to control weighting in your Vespa ranking expressions with multiple Max Sim calculations (per field) for the same query input tensor.
But, it is a vector per token, you will need lots of memory?
The Vespa ColBERT compression reduces the footprint to 16 bytes per
token vector, multiplied by the total number of tokens in the
document. The paged option allows Vespa to use the OS virtual
memory management to page data in and out on demand.
How do these scoring methods scale with the number of documents ranked, tokens, and context windows? FLOPS scale with the number of documents ranked times the number of token vectors in the document.
How does Long-ColBERT compare to RankGPT, cross-encoders, or re-ranking services? It is a tradeoff between effectiveness and performance factors like cost and latency.
Can I combine ColBERT with reranking with cross-encoder models in Vespa? Yes, an example phased ranking pipeline could use hybrid retrieval, re-rank with ColBERT, and perform a final global phase re-ranking with a cross-encoder.
Using ColBERT as an intermediate step can help reduce the ranking depth of the cross-encoder. The Vespa msmarco ranking sample application demonstrates an effective ranking pipeline.
How does ColBERT relate to Vespa’s support for nearestNeighbor search? It does not directly relate to Vespa’s nearestNeighbor support. The nearestNeighbor search operator could be used to retrieve hits in the first stage of a ranking pipeline, and where ColBERT is used in a second-phase expression. Vespa’s native embedders map text to a tensor representation, which can be used in ranking; independent of the query retrieval formulation.
What are the tradeoffs related to Vespa paged attributes?
The paged option allows the Linux virtual memory system
to manage the tensor data, paging data in and out on demand.
Using paged usually works well if you limit the number of potential
random accesses by only accessing paged attributes in
second phase ranking. Read more in
documentation.
Using paged attributes on HW with high-latency network-attached storage disks (e.g EBS), might not be the best option.
Also, if there is free available memory, everything works as if not using the paged option. Benchmarking with a realistic document volume/memory overcommit is vital when using the paged attribute option to avoid latency surprises in production.
How does Long-ColBERT impact processing or indexing time? Storing the tensor is a simple append operation to the Vespa storage engine, and does not impact indexing time negatively. Inferencing with embedder models scales as regular transformer model inference. See scaling inference with embedders.
Since Vespa inferences with the ColBERT model multiple times (once per window), allowing a higher per-document operation timeout can be beneficial.
I have PDFs with 10K pages, should I use one PDF ⇔ one Vespa document? In this case, it would be better to split the PDF into retrievable units like a PDF page instead of attempting to represent the entire PDF as a single document.
Is Long-ColBERT supported with Vespa streaming mode for efficient personal (multi-tenancy with millions of users)? Yes, you can use Long-ColBERT with Vespa streaming mode.
Can Vespa take care of the text windowing for me?
You can write a custom Vespa document processor
that implements
your chunking strategy. Alternatively, use the split indexing expression
support
for simple regular expression splitting of string into an array of
string.
Can I fine-tune my own ColBERT model, maybe in a different language than English? Yes you can, https://github.com/bclavie/RAGatouille is a great way to get started with training ColBERT models and the base-model can also be a multilingual model. We can also recommend UDAPDR: Unsupervised Domain Adaptation via LLM Prompting and Distillation of Rerankers that fine-tunes a ColBERT model using synthetic data. See also related work for in-domain adaption of ranking models.
How do I get started with Long-ColBERT for my data? We got you covered with a Vespa sample application that you can deploy to Vespa Cloud.
We run Vespa on-premise using the open-source Vespa image; how to use long-context ColBERT? You need to upgrade your Vespa installation to at least 8.311.28. Vespa Cloud deployments are already upgraded to a version that supports long-context ColBERT.
Can I use Long-ColBERT without using the native Vespa embedder? I have already paid for GPU instances for a year, so I want to put them to use. Yes, you can, you can compute the tensor representations outside of Vespa and use the feed and query API to pass the tensors.
Is Long-ColBERT in Vespa ready for production? Yes.
Where can I learn more about Vespa tensors? Some resources that might help you get started:
- Tensor introduction guide
- Tensor primitive functions
- Tensor non-primitive functions
- Blog: Computing with tensors in Vespa
Also the Advent of Vespa tensors has many fun practical examples of what you can do with Vespa tensors.
Are you using torch tensor engine as the backend? No, Vespa implements a tensor evaluation engine in C++ and Java. The tensor expressions in rank profiles are compiled into optimized code.
I have more questions; I want to learn more! For those interested in learning more about Vespa or ColBERT, join the Vespa community on Slack to exchange ideas, seek assistance from the community, or stay in the loop on the latest Vespa developments.
