

Photo by Maxime VALCARCE on Unsplash
This blog post explores using large language models (LLMs) to generate labeled data for training ranking models. Distilling the knowledge and power of generative models with billions of parameters to ranking models with a few million parameters. The approach uses a handful of human-annotated labeled examples (few-shot) and prompts the LLM to generate synthetic queries for documents in the corpus.
The ability to create high-quality synthetic training data might be a turning point with the potential to revolutionize information retrieval. With a handful of human annotations, the LLMs can generate infinite amounts of high-quality labeled data at a low cost. Training data which is used to train much smaller and compute efficient ranking models.
Introduction
Language models built on the Transformer architecture have revolutionized text ranking overnight, advancing the state-of-the-art by more than 30% on the MS MARCO relevance dataset. However, Transformer-based ranking models need significant amounts of labeled data and supervision to realize their potential. Obtaining high-quality annotated data for training deep ranking models is labor-intensive and costly. Therefore, many organizations try to overcome the labeling cost problem by using pseudo-labels derived from click models. Click models use query-document user interaction from previously seen queries to label documents. Unfortunately, ranking models trained on click-data suffer from multiple bias issues, such as presentation bias and survivorship bias towards the existing ranking model.
In addition, what if you want to build a great search experience in a new domain without any interaction data (cold-start) or resources to obtain sufficient amounts of labeled data to train neural ranking models? The answer might be generative large language models (LLMs), which can generate training data to train a ranking model adapted to the domain and use case.
Generative large language models (LLMs)
The public interest in generative language models (LLMs) has skyrocketed since OpenAI released ChatGPT in November 2022. The GPT-3 model is trained on a massive amount of text data using unsupervised learning and can generate human-like text given a text prompt input.
Google is another leader in the language model space, except they have not exposed any of them in a public chat-like interface like OpenAI. In Scaling Instruction-Finetuned Language Models, researchers from Google describe a few of their generative language models and instruction fine-tuning. In contrast to OpenAI and many other language model providers, Google has open-sourced their generative FLAN-T5 models in various model sizes, up to 11B parameters, using a permissive Apache 2.0 License.
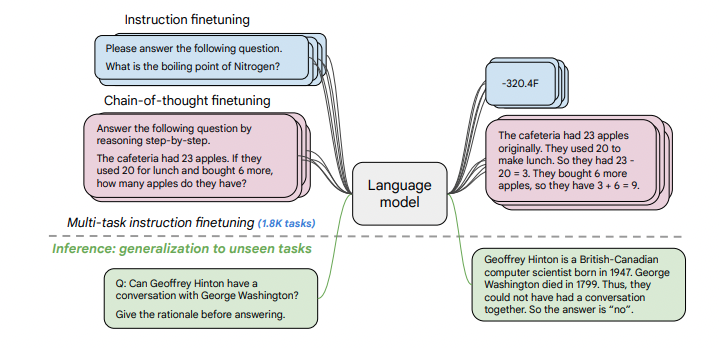 Figure from Scaling Instruction-Finetuned Language
Models
Figure from Scaling Instruction-Finetuned Language
Models
A critical difference between large generative language models and a vanilla BERT ranking model is that they necessarily don’t require task-specific fine-tuning of the model weights. Massive self-supervised training on piles of text, coupled with later fine-tuning on a broad, diverse set of tasks, is one of the reasons they are called foundation models (FM).
The foundation model weights are frozen, but we can adapt the model to our task by mixing natural language instructions with data in the prompt input. The art of mixing instructions and data in an LLM instruction prompt has created a new artistic engineering field; prompt engineering. We can improve the model’s generated output using prompt engineering by changing the instructions written in natural language.
Generating labeled data via instruction-prompting Large Language Models
Instruction-prompting large language models (LLMs) have also entered the information retrieval research (IR). A recent trend in IR research is to use generative LLMs, such as GPT-3, to generate synthetic data to train ranking models 1 2 3 4 5.
The general idea is to design an instruction prompt with a few labeled relevance examples fed to the LLM (large language model) to generate synthetic queries or documents. The instruction prompts that generate artificial questions are the most promising direction since all you need is a few labeled queries, document examples, and samples from the document corpus. In addition, with synthetic query generators, you avoid running inference with computationally expensive LLMs at user time, which can be unrealistic for most organizations. Instead, the synthetic generation process is performed offline with LLM-powered query generators. Offline inference with LLMs is considerably less engineering-intensive than online usage, as inference latency is not a concern.
LLMs will hallucinate and sometimes produce fake queries that are too generic or irrelevant. To overcome this, researchers 1 2 3 4 use a ranking model (RM) to test the query quality. One can, for example, rank documents from the corpus for each generated synthetic query using the RM. The synthetic query is only retained for model training if the source document ranks highly. This query consistency check grounds the LLM output and improves the training data. Once the synthetic queries and positive (relevant) document pairs are filtered, one can sample negative (potentially irrelevant) examples and train a ranking model adapted to the domain, the characteristics of the document corpus, and the few-show query examples.
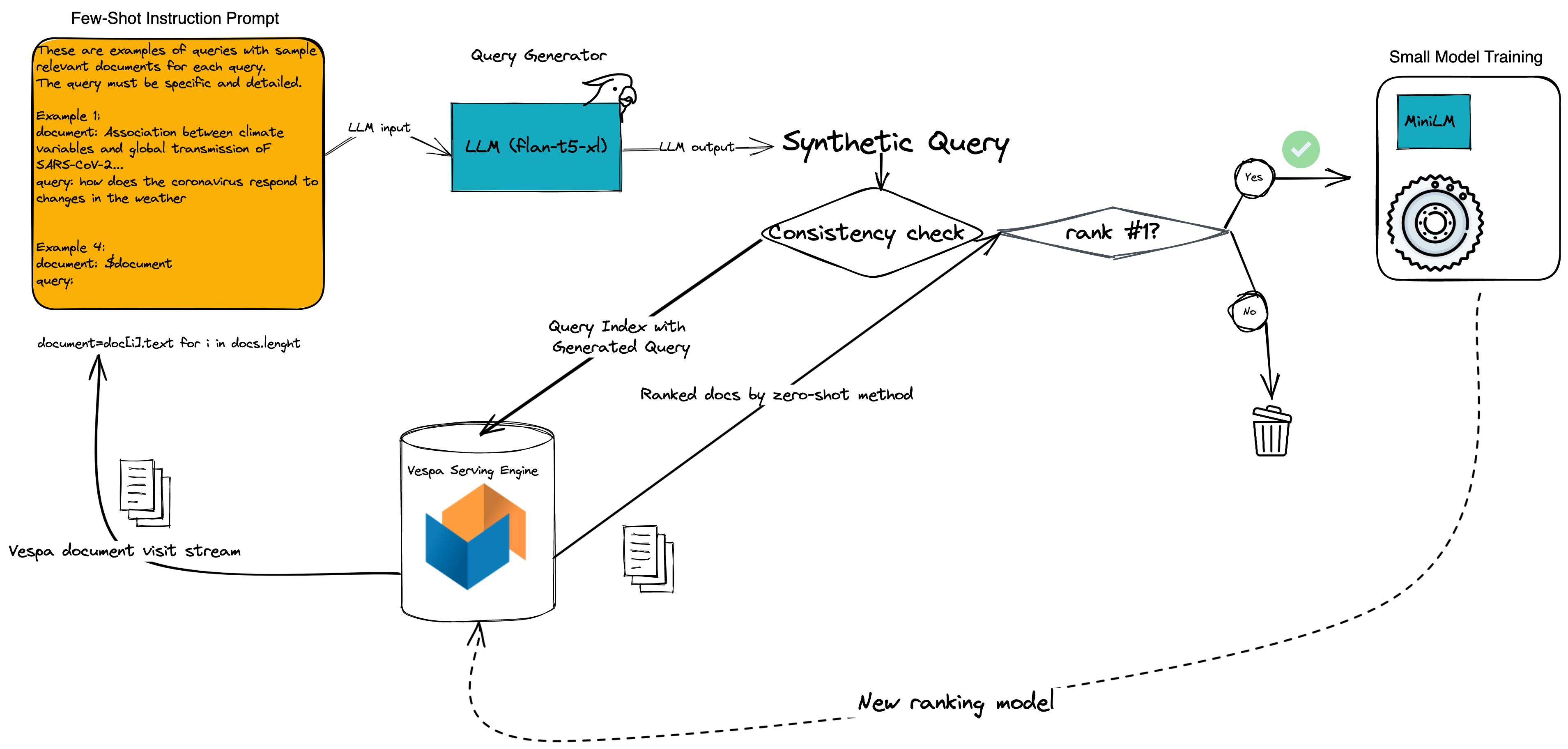 Illustration of distilling the knowledge and power of generative Large Language Models (LLMs) with billions of parameters to ranking models with a few million parameters.
Illustration of distilling the knowledge and power of generative Large Language Models (LLMs) with billions of parameters to ranking models with a few million parameters.
Experiments
In the previous posts on zero-shot ranking experiments, we evaluated zero-shot ranking models on 13 BEIR benchmark datasets. We reported large gains in ranking effectiveness by a hybrid ranking model that combines unsupervised BM25 ranking with a neural ranking model trained on a large relevance dataset. This hybrid model is an example of a zero-shot ranking model without any fine-tuning or adaption to the new domain.
In this work, we want to see if we can improve the effectiveness by using a large language model to create synthetic training data for the new domain. We focus on one of the BEIR datasets, the bio-medical trec-covid IR dataset. We chose this dataset because we have previously built a simple demo search UI and Vespa app, indexing the final CORD-19 dataset. With this demo, we can deploy the ranking models to a production app in Vespa cloud. The following subsections describe the experimental setup. We also publish three notebooks demonstrating the 3-stage process.
Synthetic query generation
We chose the open-source 3 Billion flan-t5-xl generative model as our artificial query generator. The model is genuine open-source, licensed with a permissive Apache 2.0 license. We devise the following few-shot instruction prompt template.
These are examples of queries with sample relevant documents for
each query. The query must be specific and detailed.
Example 1:
document: $document_example_1
query: $query_example_1
Example 2:
document: #document_example_2
query: $query_example_2
Example 3:
document: $document_example_3
query: $query_example
Example 4:
document: $input_document
query:
Our first prompt attempt did not include “the query must be specific and detailed” phrase. Without it, many eyeballed queries were too generic. Changing the prompt made the model produce more specific queries. The change in output quality is an example of the magic of prompt engineering.
We use the three first trec-covid test queries (originally from https://ir.nist.gov/trec-covid/data/topics-rnd5.xml, which is not available anymore) as our in-domain examples for few-shot instruction examples. We pick the first document annotated as highly relevant to form the complete query-document example.
Finally, we iterate over the document collection, replace the
$input_document variable with a concatenation of the title and
abstract, then run an inference with the flan-t5-xl model and store the generated
query. We use a single A100 40GB GPU, which costs about 1$/hour and can
generate about 3600 synthetic queries per hour (depending on prompt size).
At completion, we ended up with synthetic queries for 33,099 documents out of 171K docs. Notice that the three query-document examples are the same for all document-to-query creations and that the model’s max input sequence length limits the number of examples we can fit into the prompt.
Query consistency checking
We use a robust zero-shot hybrid ranking
model
for query consistency checking. The generated query is retained for
training only if the source document is ranked #1 by the zero-shot
model. If the question passes this test, we also sample two negative
query-document pairs from the top 100 documents ranked by the
zero-shot model. After the consistency filter, the number of positive
query, document pairs drops to 14,156 (43% retention). The high retention
percentage demonstrates that the flan-t5-xl and prompt combination is creating
specific and detailed queries.
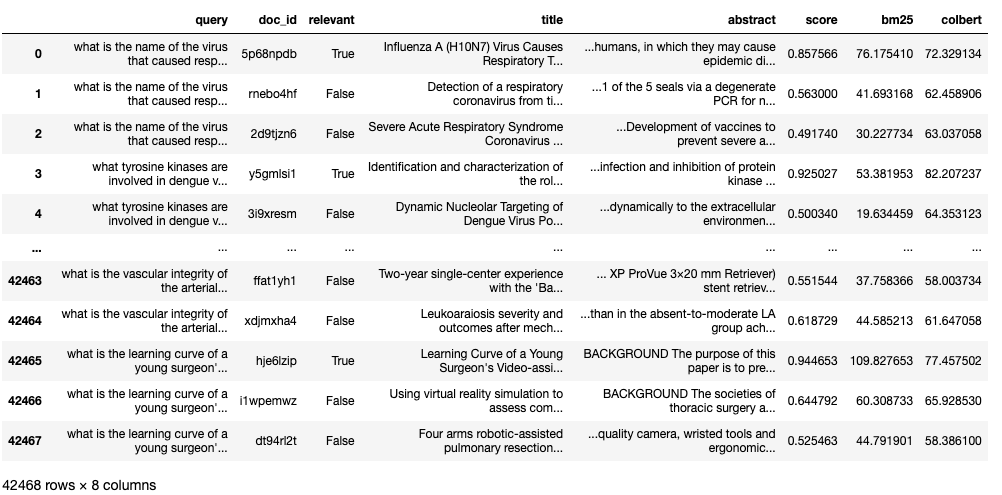 Dataframe with the generated synthetic queries and the document
metadata. The document abstract is summarized by the query contextual
Vespa dynamic
summary
feature. There are three rows in the data frame for each unique
generated question, one positive (relevant) document and two
irrelevant. This is the input to the next step, which is to train
a ranking model on this purely synthetic data.
Dataframe with the generated synthetic queries and the document
metadata. The document abstract is summarized by the query contextual
Vespa dynamic
summary
feature. There are three rows in the data frame for each unique
generated question, one positive (relevant) document and two
irrelevant. This is the input to the next step, which is to train
a ranking model on this purely synthetic data.
Rank model training
After query generation and consistency checking, we use the synthetic query and document pairs to train a ranking model. As in previous work, we use a cross-encoder based on a 6-layer MiniLM model with just 22M trainable parameters. We train the model for two epochs on the synthetic data and export the model to ONNX for inference in Vespa.
Finally, we deploy the fine-tuned model as a re-ranking phase on top of the top 30 results from the hybrid model.
Evaluation & Results
We contrast the model tuned by synthetic queries with ranking models evaluated in the zero-shot ranking blog post on the trec-covid dataset.
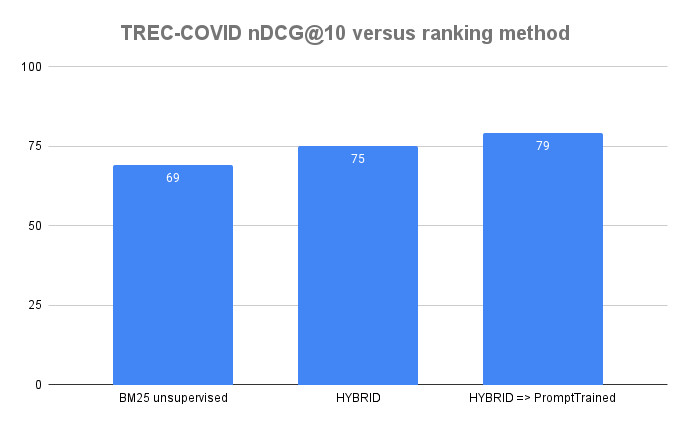
We gain four nDCG@10 points over the strong hybrid zero-shot model and 10 nDCG@10 points over unsupervised BM25. These are significant gains, especially given the low training and inference costs. We also note that the Vespa BM25 baseline is strong, beating other BM25 implementations on the same dataset. The model trained on synthetic data outperforms the PROMPTAGTOR model, which uses a proprietary 137B FLAN checkpoint to generate synthetic queries. In the paper they report a nDCG@10 of 76.2 on trec-covid. Finally, we contrast with OpenAI’s GPT embedding paper, where OpenAI reporst a nDCG@10 score of 64.9 for their GPT XL embeddings on trec-covid.
Deploying to production
There are two reasons for choosing a cross-encoder model over a bi-encoder for our synthetic fueled ranking model.
- Cross-encoders are generally more effective than bi-encoders.
- Updating the cross-encoder model weight does not require re-processing the document corpus. With bi-encoders using single vector representations, developers would have to re-process the document-side embeddings every time a new prompt-trained ranking model is available. With a cross-encoder, model versioning and A/B testing are easier to operationalize.
Cross-encoder’s downside is the computational complexity at query time, which is quadratic with model sequence input length. We deploy a trick to reduce the model input sequence; we input the query, title, and a query contextual Vespa dynamic summary of the abstract. The dynamic abstract summarization reduces the sequence length while retaining segments of the abstract that matches the query. Furthermore, we limit the complexity by reducing the re-ranking depth to 30. Finally, we deploy the trained model to our https://cord19.vespa.ai/ demo site, where users can choose between the prompt-generated model or the previously described zero-shot ranking models.
Conclusion
Synthetic query generation via instruction-prompted LLMs is a promising approach for overcoming the label shortage problem. With just three human labeled examples, the query generator, built on an open-source flan-t5 model, could generate high-quality training data.
As part of this work, we open-source three notebooks:
- Flan-t5 query generator with instruction prompt
- Consistency query checking and negative sampling
- Training the cross-encoder ranking model using the consistency-checked data
In addition to these resources; we open-source the generated synthetic queries and the consistency-checked training data (trec_covid_train_data_k1.parquet). The training data includes the zero-shot scores, the consistenty checked query, the document title, and the query contextual summarization of the abstract. The end-to-end Vespa application is also open-sourced.
In future work, we’ll look at how generative models can be used for re-ranking, summarization, and generative question answering with Vespa.
Regardless, improving retrieval quality is step one in improving the overall effectiveness of any retrieval-augmented system.
References
-
InPars: Data Augmentation for Information Retrieval using Large Language Models, Bonifacio et al. ↩ ↩2
-
InPars-v2: Large Language Models as Efficient Dataset Generators for Information Retrieval, Jeronymo et al. ↩ ↩2
-
InPars-Light: Cost-Effective Unsupervised Training of Efficient Rankers, Boytsov et al. ↩ ↩2
-
Promptagator: Few-shot Dense Retrieval From 8 Examples, Dai et al. ↩ ↩2
-
Improving Passage Retrieval with Zero-Shot Question Generation, Sachan et al. ↩