

By Lester Solbakken from Verizon Media and Pranav Sharma from Microsoft.
There’s a difference between stateless and stateful model serving.
Stateless model serving is what one usually thinks about when using a machine-learned model in production. For instance, a web application handling live traffic can call out to a model server from somewhere in the serving stack. The output of this model service depends purely on the input. This is fine for many tasks, such as classification, text generation, object detection, and translation, where the model is evaluated once per query.
There are, however, some applications where the input is combined with stored or persisted data to generate a result. We call this stateful model evaluation. Applications such as search and recommendation need to evaluate models with a potentially large number of items for each query. A model server can quickly become a scalability bottleneck in these cases, regardless of how efficient the model inference is.
In other words, stateless model serving requires sending all necessary input data to the model. In stateful model serving, the model should be computed where the data is stored.
At Vespa.ai, we are concerned with efficient stateful model evaluation. Vespa.ai is an open-source platform for building applications that do real-time data processing over large data sets. Designed to be highly performant and web-scalable, it is used for such diverse tasks as search, personalization, recommendation, ads, auto-complete, image and similarity search, comment ranking, and even for finding love.
It has become increasingly important for us to be able to evaluate complex machine-learned models efficiently. Delivering low latency, fast inference and low serving cost is challenging while at the same time providing support for the various model training frameworks.
We eventually chose to leverage ONNX Runtime (ORT) for this task. ONNX Runtime is an accelerator for model inference. It has vastly increased Vespa.ai’s capacity for evaluating large models, both in performance and model types we support. ONNX Runtime’s capabilities within hardware acceleration and model optimizations, such as quantization, has enabled efficient evaluation of large NLP models like BERT and other Transformer models in Vespa.ai.
In this post, we’ll share our journey on why and how we eventually chose ONNX Runtime and share some of our experiences with it.
About Vespa.ai
Vespa.ai has a rich history. Its lineage comes from a search engine born in 1997. Initially powering the web search at alltheweb.com, it was flexible enough to be used in various more specialized products, or verticals, such as document search, mobile search, yellow pages, and banking. This flexibility in being a vertical search platform eventually gave rise to its name, Vespa.
The technology was acquired by Yahoo in 2003. There, Vespa cemented itself as a core piece of technology that powers hundreds of applications, including many of Yahoo’s most essential services. We open-sourced Vespa in 2017 and today it serves hundreds of thousands of queries per second worldwide at any given time, with billions of content items for hundreds of millions of users.
Although Yahoo was eventually acquired by Verizon, it is interesting to note that our team has stayed remarkably stable over the years. Indeed, a few of the engineers that started working on that initial engine over 20 years ago are still here. Our team counts about 30 developers, and we are situated in Trondheim in Norway.
Building upon experience gained over many years, Vespa.ai has evolved substantially to become what it is today. It now stands as a battle-proven general engine for real-time computation over large data sets. It has many features that make it suitable for web-scale applications. It stores and indexes data with instant writes so that queries, selection, and processing over the data can be performed efficiently at serving time. It’s elastic and fault-tolerant, so nodes can be added, removed, or replaced live without losing data. It’s easy to configure, operate, and add custom logic. Importantly, it contains built-in capabilities for advanced computation, including machine learned models.
Vespa.ai applications
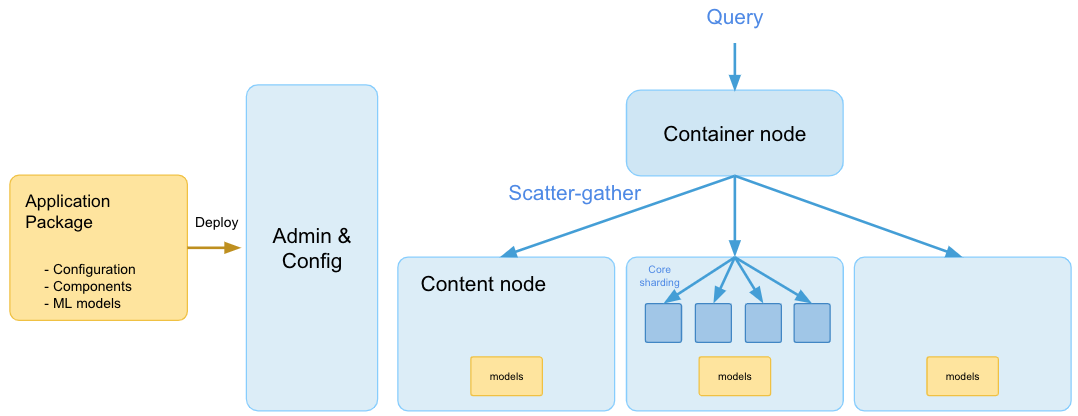
Vespa.ai is a distributed application consisting of stateless nodes and a set of stateful content nodes containing the data. A Vespa.ai application is fully defined in an application package. This is a single unit containing everything needed to set up an application, including all configuration, custom components, schemas, and machine-learned models. When the application package is deployed, the admin layer takes care of configuring all the services across all the system’s nodes. This includes distributing all models to all content nodes.
Application packages contain one or more document schemas. The schema primarily consists of:
- The data fields for each document and how they should be stored and indexed.
- The ranking profiles which define how each document should be scored during query handling.
The ranking profiles contain ranking expressions, which are mathematical expressions combining ranking features. Some features retrieve data from sources such as the query, stored data, or constants. Others compute or aggregate data in various ways. Ranking profiles support multi-phased evaluation, so a cheap model can be evaluated in the first phase and a more expensive model for the second. Both sparse and dense tensors are supported for more advanced computation.
After the application is deployed, it is ready to handle data writes and queries. Data feeds are first processed on the stateless layer before content is distributed (with redundancy) to the content nodes. Similarly, queries go through the stateless layer before being fanned out to the content nodes where data-dependent computation is handled. They return their results back to the stateless layer, where the globally best results are determined, and a response is ultimately returned.
A guiding principle in Vespa.ai is to move computation to the data rather than the other way around. Machine-learned models are automatically deployed to all content nodes and evaluated there for each query. This alleviates the cost of query-time data transportation. Also, as Vespa.ai takes care of distributing data to the content nodes and redistributing elastically, one can scale up computationally by adding more content nodes, thus distributing computation as well.
In summary, Vespa.ai offers ease of deployment, flexibility in combining many types of models and computations out of the box without any plugins or extensions, efficient evaluation without moving data around and a less complex system to maintain. This makes Vespa.ai an attractive platform.
ONNX in Vespa.ai
In the last few years, it has become increasingly important for Vespa.ai to support various types of machine learned models from different frameworks. This led to us introducing initial support for ONNX models in 2018.
The Open Neural Network Exchange (ONNX) is an open standard for distributing machine learned models between different systems. The goal of ONNX is interoperability between model training frameworks and inference engines, avoiding any vendor lock-in. For instance, HuggingFace’s Transformer library includes export to ONNX, PyTorch has native ONNX export, and TensorFlow models can be converted to ONNX. From our perspective, supporting ONNX is obviously interesting as it would maximize the range of models we could support.
To support ONNX in Vespa.ai, we introduced a special onnx ranking feature. When used in a ranking expression this would instruct the framework to evaluate the ONNX model. This is one of the unique features of Vespa.ai, as one has the flexibility to combine results from various features and string models together. For instance, one could use a small, fast model in an early phase, and a more complex and computationally expensive model that only runs on the most promising candidates. For instance:
document my_document {
field text_embedding type tensor(x[769]) {
indexing: attribute | index
attribute {
distance-metric: euclidean
}
}
field text_tokens type tensor(d0[256]) {
indexing: summary | attribute
}
}
onnx-model my_model {
file: files/my_model.onnx
input input_0: ...
input input_1: ...
output output_0: ...
}
rank-profile my_profile {
first-phase {
expression: closeness(field, text_embedding)
}
second-phase {
rerank-count: 10
expression: onnx(my_model)
}
}
This is an example of configuring Vespa.ai to calculate the euclidean distance
between a query vector and the stored text_embedding vector in the first stage.
This is usually used together with an approximate nearest neighbor search. The
top 10 candidates are sent to the ONNX model in the second stage. Note that
this is per content node, so with 10 content nodes, the model is running
effectively on 100 candidates.
The model is set up in the onnx-model section. The file refers to an ONNX model
somewhere in the application package. Inputs to the model, while not actually
shown here for brevity, can come from various sources such as constants, the
query, a document, or some combination expressed through a user-defined
function. While the output of models are tensors, the resulting value of a
first or second phase expression needs to be a single scalar, as documents are
sorted according to this score before being returned.
Our initial implementation of the onnx ranking feature was to import the ONNX
model and convert the entire graph into native Vespa.ai expressions. This was
feasible because of the flexibility of the various tensor
operations
Vespa.ai supports. For instance, a single neural network layer could be
converted like this:
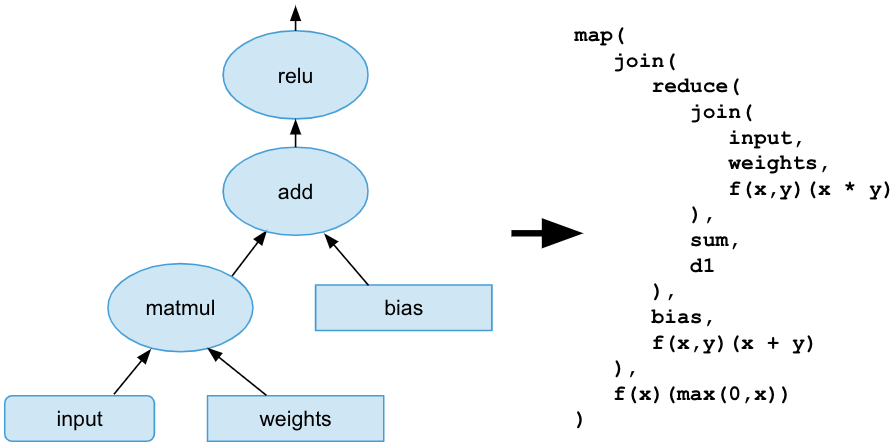
Here, weights and bias would be stored as constant tensors, whereas the input tensor could be retrieved either from the query, a document field, or some combination of both.
Initially, this worked fine. We implemented the various ONNX operators using the available tensor operations. However, we only supported a subset of the 150+ ONNX operators at first, as we considered that only certain types of models were viable for use in Vespa.ai due to its low-latency requirement. For instance, the ranking expression language does not support iterations, making it more challenging to implement operators used in convolutional or recurrent neural networks. Instead, we opted to continuously add operator support as new model types were used in Vespa.ai.
The advantage of this was that the various optimizations we introduced to our tensor evaluation engine to efficiently evaluate the models benefitted all other applications using tensors as well.
ONNX Runtime
Unfortunately, we ran into problems as we started developing support for Transformer models. Our first attempt at supporting a 12-layer BERT-base model failed. This was a model converted from TensorFlow to ONNX. The evaluation result was incorrect, with relatively poor performance.
We spent significant efforts on this. Quite a few operators had to be rewritten due to, sometimes subtle, edge cases. We introduced a dozen or so performance optimizations, to avoid doing silly stuff such as calculating the same expressions multiple times and allocating memory unnecessarily. Ultimately, we were able to increase performance by more than two orders of magnitude.
During this development we turned to ONNX Runtime for reference. ONNX Runtime is easy to use:
import onnxruntime as ort
session = ort.InferenceSession(“model.onnx”)
session.run( output_names=[...], input_feed={...} )
This was invaluable, providing us with a reference for correctness and a performance target.
At one point, we started toying with the idea of actually using ONNX Runtime directly for the model inference instead of converting it to Vespa.ai expressions. The Vespa.ai content node is written in C++, so this entailed integrating with the C++ interface of ONNX Runtime. It should be mentioned that adding dependencies to Vespa.ai is not something we often do, as we prefer to avoid dependencies and thus own the entire stack.
Within a couple of weeks, we had a proof of concept up and running which showed a lot of promise. So we decided to go ahead and start using ONNX Runtime to evaluate all ONNX models in Vespa.ai.
This proved to be a game-changer for us. It vastly increases the capabilities of evaluating large deep-learning models in Vespa.ai in terms of model types we support and evaluation performance. We can leverage ONNX Runtime’s use of MLAS, a compute library containing processor-optimized kernels. ONNX Runtime also contains model-specific optimizations for BERT models (such as multi-head attention node fusion) and makes it easy to evaluate precision-reduced models by quantization for even more efficient inference.
ONNX Runtime in Vespa.ai
Consider the following:
onnx-model my_model {
file: files/my_model.onnx
input input_0: query(my_query_input)
input input_1: attribute(my_doc_field)
}
rank-profile my_profile {
first-phase {
expression: sum( onnx(my_model) )
}
}
Here we have a single ONNX model that has two inputs. During application deployment, Vespa.ai distributes this ONNX model to all content nodes. There, the ranking expressions are parsed, and the feature executors that implement the ranking features are set up in preparation for handling traffic. Here we have 4 features:
query(...)which retrieves a tensor from the query.attribute(...)which retrieves a tensor from a field stored in the document.onnx(...)which evaluates the ONNX model.sum(...)which reduces and sums the argument tensor to a single scalar value.
These features are wired together during initialization, so the outputs of
query and attribute are used as inputs to onnx, and the output of the
onnx feature is the input to the sum feature. The onnx feature basically sets
up ONNX Runtime to evaluate the model.
Vespa.ai’s scoring framework is written in C++, so we use the C/C++ API provided by ONNX Runtime. While the integration with ONNX Runtime worked smoothly out of the box, there are two areas worth mentioning here: multi-threading and input/output tensor allocations.
Multi-threading
During setup, we initialize an ONNX Runtime session for each onnx feature and thread:
#include <onnxruntime/onnxruntime_cxx_api.h> Ort::Env shared_env; Ort::SessionOptions options; options.SetIntraOpNumThreads(1); options.SetInterOpNumThreads(1); options.SetGraphOptimizationLevel(ORT_ENABLE_ALL); Ort::Session session = Ort::Session(shared_env, “local_file_path”, options);
The session includes options for thread management. ONNX Runtime supports 2 modes of execution: sequential and parallel. This controls whether the operators in a graph run sequentially or in parallel. Parallel execution of operators is scheduled on an inter-op thread pool. The execution of an individual operator is parallelized using an intra-op thread pool. A heavily home-optimized variant of an Eigen thread pool is used for inter-op parallelism, while OpenMP is used for intra-op.
Vespa.ai handles several queries in parallel. In addition, Vespa.ai can be configured to use several threads per query. Because of this Vespa.ai needs to tightly manage thread usage. Using additional threads inside an ONNX Runtime session causes system-level throughput to become unpredictable, with large deviations in performance. Since Vespa.ai has thread control outside of ONNX Runtime, we need to instruct ONNX Runtime to only use a single thread. By ensuring that the total number of threads do not exceed the number of physical cores in a machine, we can improve cache utilization. Vespa also supports processor pinning.
As we instruct ONNX Runtime to in effect run sequentially, inference times
increase but total throughput also increases. For instance, we measured a 50%
improvement in throughput on a BERT ranking application. We have not yet
exposed ONNX Runtime’s thread management settings for cases where users would
like to tune this themselves. This is an option we might consider in the
future. In that case, each session having their own set of thread pools would
be inefficient. However, ONNX Runtime provides an option to share thread pools
between sessions. This is achieved using the CreateEnvWithGlobalThreadPools C
API to set up the shared_env object, which in Vespa.ai is shared between all
feature executors.
When we started using ONNX Runtime, its C++ distribution was bundled with OpenMP. This was problematic for us as the intra-operation thread setting was overridden by OpenMP, so we ended up compiling our own ONNX Runtime without OpenMP enabled. However, starting from version 1.6, ONNX Runtime ships a version without OpenMP.
Input and output tensors
As much as possible, memory allocation and ownership of input and output tensors happen within Vespa.ai. Consider the following types:
std::vector<const char *> input_names; std::vector<const char *> output_names; std::vector<Ort::Value> input_values; std::vector<Ort::Value> output_values;
The input values come from other ranking features using Vespa.ai’s tensor framework. The values in the input vector are wrappers for Vespa.ai tensors. So ONNX Runtime accepts the memory layout from Vespa.ai without copying to internal buffers. The values in the output vector are pre-allocated ONNX Runtime vectors which are wrapped when used subsequently in other ranking features.
We use these directly when evaluating the model:
Ort::RunOptions run_opts(nullptr);
session.Run(run_opts,
input_names.data(), input_values.data(), input_values.size(),
output_names.data(), output_values.data(), output_values.size());
This zero-copying of tensors is obviously desirable from a performance perspective. This works for outputs as tensors in Vespa.ai currently are fixed size, meaning that the dimensions are known during application deployment. So even though models accept inputs with dynamic sizes, from a Vespa.ai perspective, they must currently be fixed. Supporting dynamic sizes is future work.
One limitation here is that Vespa.ai currently only supports double and float value types in tensors. If possible, Vespa.ai takes care of converting to the type that ONNX Runtime expects. For instance, inputs to Transformer models are token sequences usually of type int64. Since Vespa.ai does not currently support int types, they must be represented as for instance float32. Converting from float32 to int64 can be lossy, but we haven’t met any inaccuracies yet. Models that accept strings as input are not yet supported in Vespa.ai.
Summary
Integrating with ONNX Runtime was relatively painless. Even though we initially had to compile our own ONNX Runtime distribution due to OpenMP, we had no significant issues with dependencies. We are looking forward to the next release so we don’t have to have to do this.
While ONNX Runtime’s C/C++ API documentation is currently relatively scarce we found it to be sufficient. The ONNX Runtime API is concrete, clean and works as one would expect. We didn’t have any issues here at all, really.
All in all, our experience with ONNX Runtime has been great. It has shown itself to be a fantastic fit for Vespa.ai, delivering superior performance and easy to work with. One example here is the BERT model optimizations in ONNX Runtime. Also of particular note is the evaluation of quantized models, which would have been laborious to implement in Vespa.ai given the current tensor types we support.
Going forward, there are other features of ONNX Runtime we would like to experiment with. One of these is GPU support. While we are currently unsure if this is beneficial from a ranking point of view, there are other cases where this is interesting. One example is calculating vector representations of documents during data writing from a Transformer model.
Vespa.ai’s use case so far has mostly been focused on natural language understanding using Transformers such as BERT. Exporting a HuggingFace model to ONNX is easy and using it in Vespa is straightforward. ONNX Runtime was essential for us when implementing an open-domain question-answering application. Also, quantization had the effect of drastically increasing performance of this application, where a key takeaway there was that a larger model with weights with reduced precision outperformed smaller models with normal precision.
We’re excited to see what our users will use this for in the future.