

Open-domain question-answering has emerged as a benchmark for measuring a system’s capability to read, represent, and retrieve general knowledge. Retrieval-based question-answering systems require connecting various systems and services, such as BM25 text search, vector similarity search, NLP model serving, tokenizers, and middleware to glue all this together. Most of these are core features of Vespa.ai. In this post, we reproduce the state-of-the-art baseline for retrieval-based question-answering systems within a single, scalable production ready application on Vespa.ai.
Introduction
Some of the most effective drivers of scientific progress are benchmarks. Benchmarks provide a common goal, a purpose, for improving the state-of-the-art on datasets that are available to everyone. Leaderboards additionally add a competitive motivation, offering the opportunity to excel among peers. And rather than just endlessly tinkering to improve relevant metrics, competitions add deadlines that spur researchers to actually get things done.
Within the field of machine learning, benchmarks have been particularly important to stimulate innovation and progress. A new competition, the Efficient Open-Domain Question Answering challenge for NeurIPS 2020, seeks to advance the state-of-the-art in question answering systems. The goal here is to develop a system capable of answering questions without any topic restriction. With all the recent progress in natural language processing, this area has emerged as a benchmark for measuring a system’s capability to read, represent, and retrieve general knowledge.
The current retrieval-based state-of-the-art is the Dense Passage Retrieval system, as described in the Dense Passage Retrieval for Open-Domain Question Answering paper. It consists of a set of python scripts, tools, and models developed primarily for research. There are a lot of parts in such a system. These include two BERT-based models for encoding text to embedding vectors, another BERT-based model for extracting answers, approximate nearest-neighbor similarity search and text-based BM25 methods for retrieving candidates, tokenizers, and so on. It’s not trivial to bring such a system to production. We thought it would be interesting to consolidate these different parts and demonstrate how to build an open-domain question-answering serving system with Vespa.ai that achieves state-of-the-art accuracy.
Most of these components are core features in Vespa. A while ago, we improved Vespa’s text search support for term-based retrieval and ranking. We recently added efficient approximate nearest neighbors for semantic, dense vector recall. For hybrid retrieval, Vespa supports many types of machine-learned models, for instance neural networks and decision forests. We have also improved our support for TensorFlow and PyTorch models to run larger NLP and Transformer models.
This is interesting because while this has obvious benefits in a research setting, such systems’ real value lies in their end-use in applications. Vespa is designed as a highly performant and scalable production-ready system. Thus, it offers a simplified path to deployment in production without coping with the complexity of maintaining many different subsystems. That makes Vespa an attractive package.
During this blog post, we’ll touch upon
- Fast approximate-nearest neighbors for semantic, dense vector retrieval.
- Term-based (BM25) retrieval for sparse vector retrieval.
- Importing of multiple pre-trained BERT-based models in Vespa for encoding embedding vectors and extracting answers.
- Custom logic for tokenization and other things.
This post’s goal is to recreate the Dense Passage Retrieval (DPR) paper results for the Natural Questions benchmark. We’ll first go through a high-level overview of how a retrieval-based question-answering system works in the context of this paper. Then we’ll show how this can all be implemented on Vespa without any external services or plugins, and recreate the paper’s state-of-the-art results as measured by the exact match of answers given a set of questions. We’ll wrap up with a look to the future and the next post in this series.
Background: the anatomy of a retrieval-based QA system
The Natural Questions benchmark consists of natural language questions and answers. How to retrieve and represent the knowledge required to answer the questions is up to each system. There are two main approaches to this: retrieval and parametric. A retrieval-based system uses search terms or semantic representation vectors to recall a set of sentences or paragraphs subsequently evaluated with a machine-learned model to extract the exact answer. A parametric system stores the answers more or less directly in the weights of a large neural network model. There has also been research into hybrid retrieval and parametric systems such as the Retrieval-Augmented Generation system, which recently improved the state-of-the-art for the natural question benchmark as a whole. In this blog post, we’ll focus on a retrieval-based system, but will explore parametric and hybrid approaches in later blog posts.
A retrieval-based question answering system typically stores its “knowledge” in an information retrieval system. This can be sentences, paragraphs, or entire documents. Here we’ll use the Wikipedia dataset where each page is split into passages of 100 words each. The dataset contains 21 million such passages. When answering a question, we first retrieve the passages that most likely include the answer. They are then analyzed with a machine-learned model to extract the spans that most likely results in the correct response. These stages are called the “retriever” and “reader”, respectively.
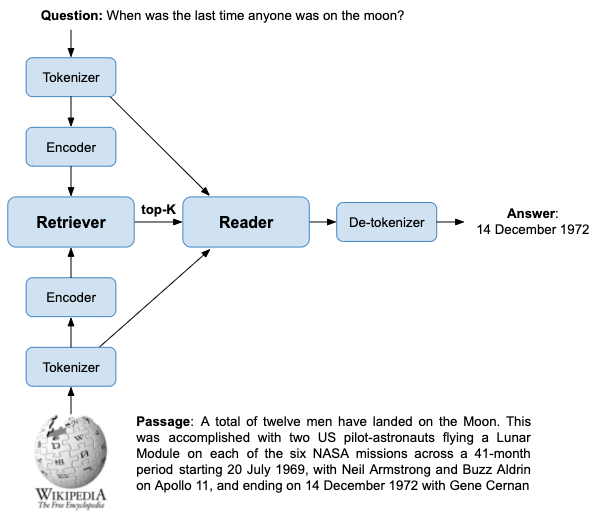
The retriever
The retriever is responsible for generating a set of candidate passages. Since the subsequent reader component is expensive to evaluate, it is crucial to have an effective retrieval mechanism. There are two main approaches to passage retrieval: term-based (sparse) such as for BM25, and embedding (dense) vectors, which each have their strengths and weaknesses.
Term-based (sparse) retrieval
Term-based retrieval is the classic information retrieval method and covers algorithms such as TF-IDF and BM25. Conceptually, the text is represented by a vector where each dimension represents a term in a vocabulary. A non-zero value signifies its presence. As each text only contains a subset of possible terms in the vocabulary, these vectors are large and sparse. The similarity between two texts, for instance, a document and a query, can be computed by a dot product between the sparse vectors with slight modifications (e.g., term importance) for TF-IDF or BM25. Term-based methods rely on inverted index structures for efficient retrieval. This can in some cases be further accelerated by algorithms such as WAND.
Except for any pre-processing such as lemmatization, stemming, and possibly stop-word removal, terms are matched exactly as found in the text. This can be a strength as well as a weakness. For salient terms, e.g. names and places, this cuts down the search space significantly. However, potentially relevant documents that don’t contain the exact term will not be retrieved unless one uses query expansion or related techniques. The Dense Passage Retrieval (DPR) paper uses ElasticSearch as the providing system for BM25.
Embedding-based (dense) retrieval
The number of potential terms in a vocabulary can be vast indeed. The basic idea behind embedding vectors is to compress this high dimensional sparse vector to a much smaller dense vector where most dimensions contain a non-zero value. This has the effect of projecting a query or document vector into a lower-dimensional space. This can be done so that vectors that are close geometrically are also close semantically. The DPR paper uses two BERT models to encode text: one for encoding queries and one for encoding documents. The two models are trained simultaneously in a two-tower configuration to maximize the dot product for passages likely to answer the question.
In contrast to the sparse representation, there are no exact methods for finding the nearest neighbors efficiently. So we trade accuracy for efficiency in what is called approximate nearest neighbors (ANN). Many different methods for ANN search have been proposed. Some are compatible with inverted index structures so they can be readily implemented in existing information retrieval systems. Examples are k-means clustering, product quantization (and it’s relatives), and locality sensitive hashing, where the centroids or buckets can be indexed. A method that is not compatible with inverted indexes is HNSW (hierarchical navigable small world). HNSW is based on graph structures, is efficient, and has an attractive property where the graph can be incrementally built at runtime. This is in contrast to most other methods that require offline, batch oriented index building.
Retrieval based on semantic embeddings complements term-based retrieval well. Semantically similar documents can be recalled even though they don’t contain the exact same terms. Unlike the bag-of-words approach for term-based retrieval, word order can provide additional context. Historically, however, term-based retrieval has outperformed semantic embeddings on question answering problems, but the DPR paper shows that dense retrieval can be vastly improved if the encoding has specifically been trained to the task. The DPR paper uses FAISS with an HNSW index for similarity search.
The reader
While the retriever component’s job is to produce a set of candidate passages that hopefully contain the answer to the question, the reader extracts the passages’ actual answer. This requires some form of natural language understanding model, and BERT (or other Transformer) models are used. These models are typically huge and expensive to evaluate, so only a small number of candidate passages are run through them.
Transformer models take sequences of tokens as input. The tokenization of text can be done in quite a few different ways to balance vocabulary size and sequence length. Due to BERT models’ full attention mechanism, evaluation time increases quadratically with sequence length. So a reasonable balance must be struck, and BERT-based models use a WordPiece or similar algorithm to split less common words into subwords.
The reader model’s input is the concatenation of the tokens representing the question, the document’s title, and the passage itself. The model looks up the embedding representation for each token, and through a series of layers, produces a new representation for each token. These representations can then be used for different tasks. For question-answering, an additional layer is added to compute the three necessary outputs: the relevance of the passage to the question, and the start and end indexes of the answer.
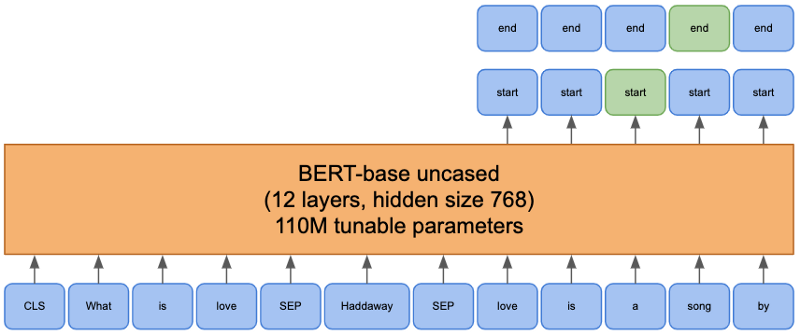
To extract the final answer, the passage that produced the largest relevance score is used. The two other outputs of the model are probabilities for each token of being a start token and an end token. The final answer is chosen by finding the span with the largest sum of start probability and end probability. This results in a sequence of tokens, which must be converted to words by the tokenizer before returning. The DPR paper uses a BERT-based model to output span predictions.
Putting all this together
The retrieval-based question-answering system as described above, capable of both term- and embedding-based retrieval, requires at least the following components:
- A BM25 information retrieval system storing the 21 million Wikipedia text passages.
- An efficient vector similarity search system storing the passage embedding vectors.
- A model serving system for the three different BERT-based models: query encoder, document encoder, and reader model.
- A BERT-based tokenizer.
- Middleware to glue this all together.
The tokenizer generates the token sequence for the text. These tokens are stored for usage in the reader model. They are also used in a document BERT-base encoder model to create the embedding vector for dense retrieval. The text and embedding vectors need to be indexed for fast retrieval.
A similar process is followed for each query. The tokenizer produces a token sequence used to generate an embedding vector in the query BERT-based encoder. The first stage, retrieval, is done using either term-based retrieval or embedding based retrieval. The top-N passages are passed to the Reader model and ranked accordingly. The best passage is analyzed to extract the best span containing the answer.
This is a non-trivial list of services that need to be set up to implement a question-answering system. In the next section we show how to implement all this as a single Vespa application.
Reproducing the baseline on Vespa
Most of the components mentioned above have become core features in Vespa. In the following we’ll present an overview of setting this up in Vespa.
Schema
When creating an application with Vespa, one typically starts with a document schema. The schema contains, among other things, the definition of which data should be stored with each document. In our case, each document is a passage from the Wikipedia dataset. So we set up a schema that allows for the different retrieval methods we have discussed:
- Sparse retrieval using traditional BM25 term-based retrieval.
- Dense retrieval using vector representations encoded by a trained model.
- Hybrid retrieval using a combination of the above.
We set up all of this in a single document schema:
schema wiki {
document wiki {
field title type string {
indexing: summary | index
}
field text type string {
indexing: summary | index
}
field title_token_ids type tensor(d0[256]) {
indexing: summary | attribute
}
field text_token_ids type tensor(d0[256]) {
indexing: summary | attribute
}
field text_embedding type tensor(x[769]) {
indexing: attribute | index
attribute {
distance-metric: euclidean
}
}
}
}
Here, each passage’s title and text content is represented both by a string and a token sequence field. The string fields are indexed to support BM25 and support WAND for accelerated retrieval. The token sequences are represented as tensors and are used as inputs to the reader model.
The embedding vector of the title and text is precomputed and stored as a tensor. This vector is used for dense retrieval, so we enable the HNSW index on this field for approximate nearest neighbor matching. A nice feature of Vespa is that the HNSW index is not pre-built offline; it is constructed online as data is indexed. This allows for applications that are much more responsive to new data being fed into the system.
Retrieval and ranking
A query in Vespa defines, among other things, how Vespa should recall documents (called the matching phase) and how Vespa should score the documents (called the ranking phase). Vespa provides a rich query API, where queries are specified with the Vespa YQL language. As the different retrieval strategies (term-based and embedding-based) have different query syntax, we have built a custom searcher component that allows us to build a unified search interface and only pass the actual question and retrieval strategy as parameters. This simplifies comparisons between the methods.
The retrieval strategies differ both on what is recalled and how they are scored. In Vespa, scoring is expressed using ranking expressions that are configured in the document schema. Vespa supports multi-phased ranking, and we exploit that here so that the first phase represents the retriever, and the second phase the reader. We set up the first phase ranking profile like this:
rank-profile sparse inherits openqa {
first-phase {
expression: bm25(text) + bm25(title)
}
}
rank-profile dense inherits openqa {
first-phase {
expression: closeness(field, text_embedding)
}
}
rank-profile hybrid inherits openqa {
first-phase {
expression: 1000*closeness(field, text_embedding) + bm25(text) + bm25(title)
}
}
Here, we set up three ranking profiles, one for sparse retrieval, one for dense
retrieval, and one for hybrid retrieval. The sparse ranking profile uses the
BM25 score of the title and text fields against the query as the scoring
function. The dense profile uses the closeness, e.g., the euclidean distance
between the query and document embedding field. The hybrid profile is an
example that combines both for hybrid retrieval. This first phase represents
the retriever.
For the reader model we set up the base profile openqa which introduces a
second phase, common between the retrieval strategies:
onnx-model reader {
file: files/reader.onnx
input input_ids: input_ids
input attention_mask: attention_mask
output output_0: start_logits
output output_1: end_logits
output output_2: relevance_logits
}
rank-profile openqa {
second-phase {
rerank-count: 10
expression: onnxModel(reader).relevance_logits
}
summary-features {
onnxModel(reader).start_logits
onnxModel(reader).end_logits
}
}
Here, the top 10 documents are re-ranked by the reader model, defined be the onnxModel rank feature. The actual model we use is a pre-trained model the DPR team has published on HuggingFace’s model repository. HuggingFace has released an excellent transformer model export, which makes it easy to export Transformer models (from either PyTorch or TensorFlow) to ONNX format. After the model is exported to ONNX, we can put the model file in the application package and configure its use in the document schema as seen above. To make this scale, Vespa distributes this model to all content nodes in the cluster. Thus the model is evaluated on the content node during ranking, avoiding transferring data to an external model service.
The reader model has three outputs, where the relevance_logits output is used
for scoring. The other two represent the probabilities of each token being a
start or end token, respectively, for the ultimate answer to the question.
These are picked up by a custom searcher, and the actual span these fields
represent is extracted there.
The application contains one additional model, the question encoder model used to generate the embedding vector for the query at run time. The pre-computed document embeddings from the Wikipedia dataset are published by Facebook Research. We use these embeddings directly.
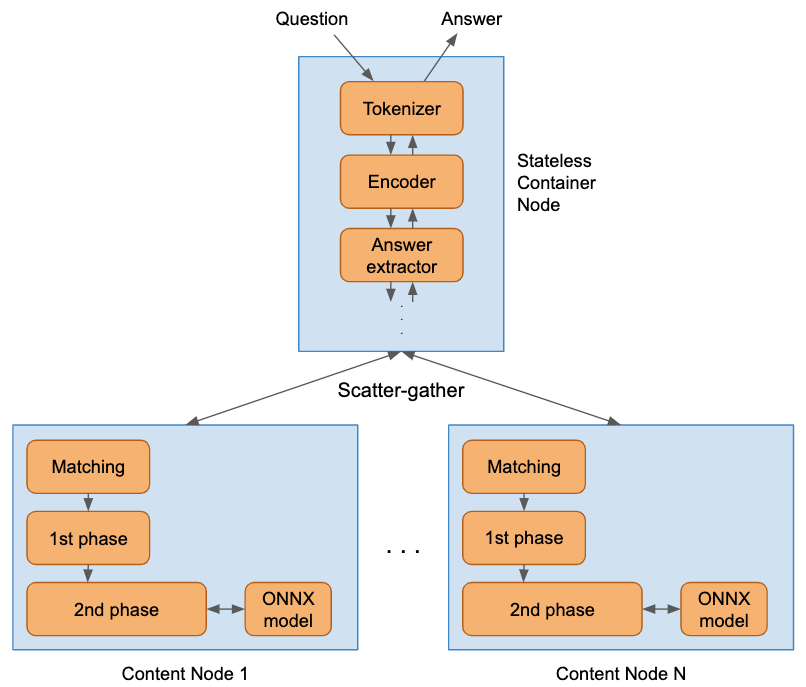
Vespa container middleware - putting it all together
The application has the following custom plugins implemented as Java in Vespa containers:
- A BERT tokenizer component that is responsible for generating the sequence of BERT tokens from a text.
- A custom document processor which uses the BERT tokenization during indexing.
- A custom searcher that retrieves the embedding representation for the query invoking the BERT question encoder model.
- A custom searcher that controls the retrieval logic (e.g., sparse, dense, or hybrid).
- A custom searcher that reads the output of the reader model and extracts the best matching answer span and converts that token sequence to the actual text which is returned to the user.
The result is a service which takes a textual question and returns the predicted answer, all within one Vespa application.
Results
The benchmark we use for this application is the Natural Questions data set. All experiments in this section are run by querying the Vespa instance and checking the predicted answer to the golden reference answer.
Retriever Accuracy Summary
We use Recall@position as the main evaluation metric for the retriever. The obvious goal of the retriever is to have the highest recall possible at the lowest possible position. Since the final top position passages are re-ranked using the BERT-based reader, the fewer passages we need to evaluate the better the run time complexity and performance.
The following table summarizes the retriever accuracy using the original 3,610 dev questions in the Natural Questions for Open Domain Question Answering tasks (NQ-open.dev.jsonl).
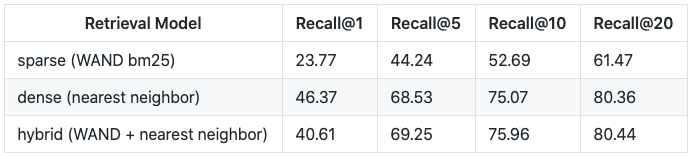
The DPR paper reports recall@20 of 79.4, so our results are inline with their reported results for the dense retrieval method. We attribute the slight difference in our favor here for a different set of settings for the HNSW index.
Reader Accuracy Summary
We evaluate the reader accuracy using the Exact Match (EM) metric. The Exact Match metric measures the percentage of predictions that match any one of the ground truth answers exactly. To get an EM score of 1 for a query the answer prediction must match the golden answer exactly as given in the dataset. This is challenging. For instance, the question “When was the last moon landing?” has golden answers “14 December 1972 UTC” or “December 1972”, and the predicted answer “14 December 1972” will be scored 0.
The results are for the same data set above, with a re-rank of the top 10 results from the retriever:
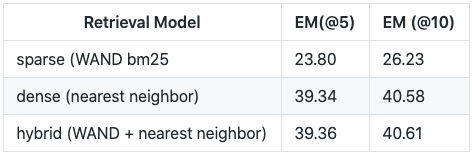
The above results reproduce the results of the DPR paper which at the writing of this post is the current state of the art for retrieval-based systems.
Further work
In this blog post we’ve been focused on reproducing the results of the DPR paper within a single instance of Vespa. In the next part of this series we will introduce a more sophisticated hybrid model and show how we can use other model types to hopefully improve accuracy. We will follow up with another post on lowering total system latency down to more reasonable levels while measuring any impact this has on accuracy.
Stay tuned!