

Photo by Norbert Braun on Unsplash
If you are planning to implement search functionality but have not yet collected data from user interactions to train ranking models, where should you begin? In this series of blog posts, we will examine the concept of zero-shot text ranking. We implement a hybrid ranking method using Vespa and evaluate it on a large set of text relevancy datasets in a zero-shot setting.
In the first post, we will discuss the distinction between in-domain and out-of-domain (zero-shot) ranking and present the BEIR benchmark. Furthermore, we highlight situations where in-domain embedding ranking effectiveness does not carry over to a different domain in a zero-shot setting.
Introduction
Pre-trained neural language models, such as BERT, fine-tuned for text ranking, have demonstrated remarkable effectiveness compared to baseline text ranking methods when evaluating the models in-domain. For example, in the Pretrained Transformer Language Models for Search blog post series, we described three methods for using pre-trained language models for text ranking, which all outperformed the traditional lexical matching baseline (BM25).
- Single-dense vector representations
- Late interaction using multiple vector representations
- Cross-encoders with full interaction between query and document
In the transformer ranking blog series, we used in-domain data for training and production (test), and the documents and the queries were drawn from the same in-domain data distribution.
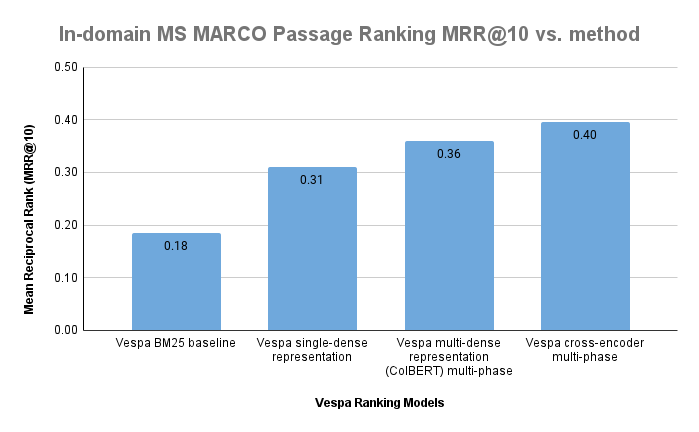
In-domain trained and evaluated ranking methods. All models are end-to-end represented using Vespa, open-sourced in the msmarco-ranking sample app. The Mean Reciprocal Rank (MRR@10) is reported for the dev query split of the MS MARCO passage ranking dataset.
This blog post looks at zero-shot text ranking, taking a ranking model and applying it to new domains without adapting or fine-tuning the model.
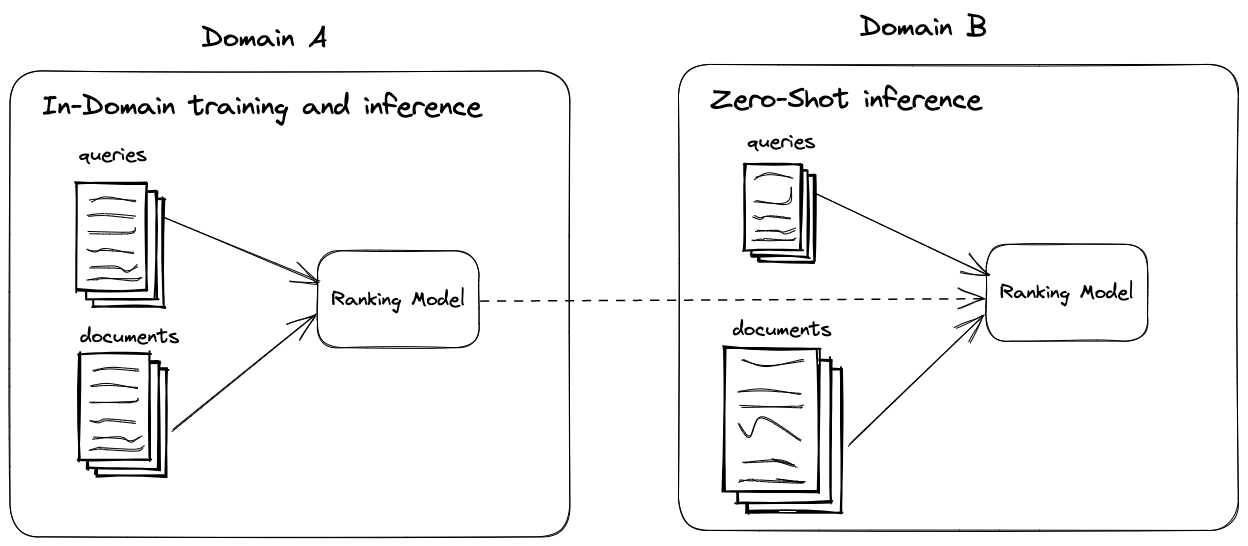 In-domain training and inference (ranking) versus zero-shot inference
(ranking) with a model trained in a different domain.
In-domain training and inference (ranking) versus zero-shot inference
(ranking) with a model trained in a different domain.
Information Retrieval Evaluation
Information retrieval (IR) evaluation is the process of measuring the effectiveness of an information retrieval system. Measuring effectiveness is important because it allows us to compare different ranking strategies and identify the most effective at retrieving relevant information.
We need a corpus of documents and a set of queries with relevance judgments to perform an IR evaluation. We can start experimenting and evaluating different ranking methods using standard IR metrics such as nDCG@10, Precision@10, and Recall@100. These IR metrics allow us to reason about the strengths and weaknesses of proposed ranking models, especially if we can evaluate the model in multiple domains or relevance datasets. Evaluation like this contrasts the industry’s most commonly used IR evaluation metric, LGTM (Looks Good To Me)@10, for a small number of queries.
Evaluating ranking models in a zero-shot setting
In BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models, Thakur et al. introduce a benchmark for assessing text ranking models in a zero-shot setting.
The benchmark includes 18 diverse datasets sampled from different domains and task definitions. All BEIR datasets have relevance judgments with varying relevance grading resolutions. For example, TREC-COVID, a dataset of the BEIR benchmark, consists of 50 test queries, with many graded relevance labels, on average 493,5 document judgments per query. On the other hand, the BEIR Natural Questions (NQ) dataset uses binary relevance labels, with 4352 test queries, with, on average, 1.2 judgments per query.
The datasets included in BEIR also have a varying number of documents, queries, and document lengths, but all the datasets are monolingual (English).
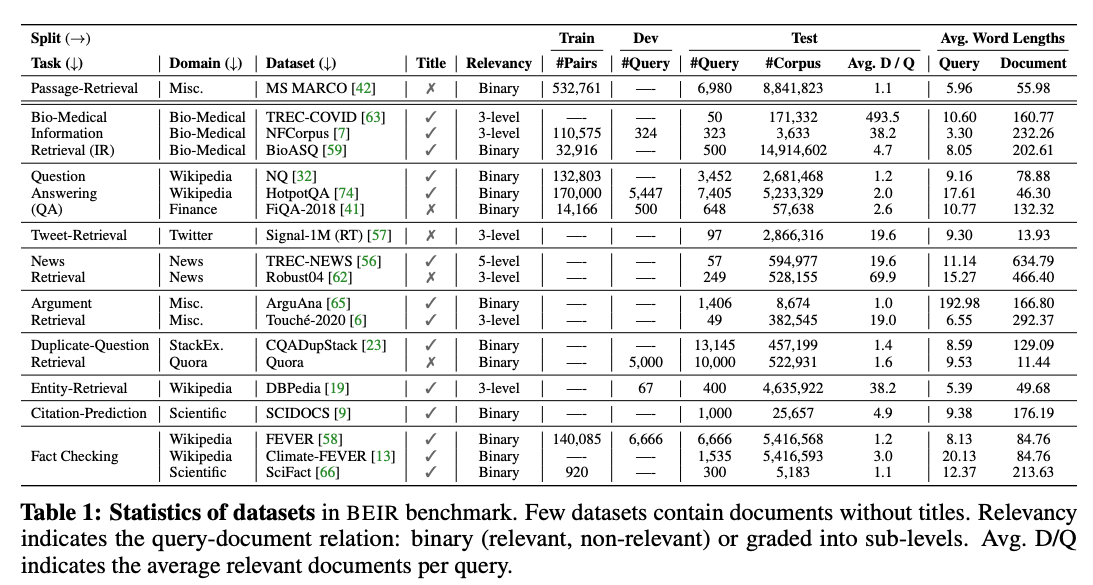 Statistics of the BEIR datasets. Table from BEIR: A Heterogeneous
Benchmark for Zero-shot Evaluation of Information Retrieval
Models; see also
BEIR Benchmark
datasets.
Statistics of the BEIR datasets. Table from BEIR: A Heterogeneous
Benchmark for Zero-shot Evaluation of Information Retrieval
Models; see also
BEIR Benchmark
datasets.
The BEIR benchmark uses the Normalised Cumulative Discount Gain (nDCG@10) ranking metric. The nDCG@10 metric handles both datasets with binary (relevant/not-relevant) and graded relevance judgments. Since not all the datasets are available in the public domain (E.g., Robust04), it’s common to report nDCG@10 on the 13 datasets that can be downloaded from the BEIR GitHub repository or using the wonderful ir_datasets library. It’s also possible to aggregate the reported nDCG@10 metrics per dataset to obtain an overall nDCG@10 score, for example, using the average across the selected BEIR datasets. It’s important to note which datasets are included in the average overall score, as they differ significantly in retrieval difficulty.
Zero-Shot evaluation of models trained on Natural Questions
The most common BEIR experimental setup uses the MS MARCO labels to train models and apply the models in a zero-shot setting on the BEIR datasets. The simple reason for this setup is that MS MARCO is the largest relevance dataset in the public domain, with more than ½ million training queries. As with NQ, there are few, an average of 1.1, relevant passages per query. Another setup variant we highlight in detail in this section is to use a ranking model trained on Natural Questions(NQ) labels with about 100K training queries and evaluate it in an out-of-domain setting on MS MARCO labels.
MS MARCO and Natural Questions datasets have fixed document corpora, and queries are split into train and test. We can train a ranking model using the train queries and evaluate the ranking method on the test set. Both datasets are monolingual (English) and have user queries formulated as natural questions.
MS MARCO sample queries
how many years did william bradford serve as governor of plymouth colony?
define preventive
color overlay photoshop
Natural Questions (NQ) sample queries
what is non controlling interest on balance sheet
how many episodes are in chicago fire season 4
who sings love will keep us alive by the eagles
On the surface, these two datasets are similar. Still, NQ has longer queries and documents compared to MS MARCO. There are also subtle differences in how these datasets were created. For example, NQ uses passages from Wikipedia only, while MS MARCO is sampled from web search results.
| Statistics/Dataset | MS MARCO | Natural Questions (NQ) |
|---|---|---|
| query length | 5.9 | 9.2 |
| document length | 56.6 | 76.0 |
| documents | 8.84M | 2.68M |
The above table summarizes basic statistics of the two datasets. Words are counted after simple space tokenization. Query lengths are calculated using the dev/test splits. Both datasets have train splits with many queries to train the ranking model.
In open-domain question answering with Vespa, we described the Dense Passage Retriever (DPR) model, which uses the Natural Questions dataset to train a dense 768-dimensional vector representation of both queries and Wikipedia paragraphs. The Wikipedia passages are encoded using the DPR model, representing each passage as a dense vector. The Wikipedia passage vector representations can be indexed and efficiently searched using an approximate nearest neighbor search.
At query time, the text query is encoded with the DPR model into a dense vector representation used to search the vector index. This ranking model is an example of dense retrieval over vector text representationns from BERT. DPR was one of the first dense retrieval methods that outperformed the BM25 baseline significantly on NQ. Since then, much water has flown down the river, and dense vector models are closing in on more computationally expensive cross-encoders in an in-domain setting on MS MARCO.
In-domain effectiveness versus out-of-domain in a zero-shot setting
The DPR model trained on NQ labels outperforms the BM25 baseline when evaluated on NQ. This is an example where the in-domain application of the trained model improves the ranking accuracy over baseline BM25.
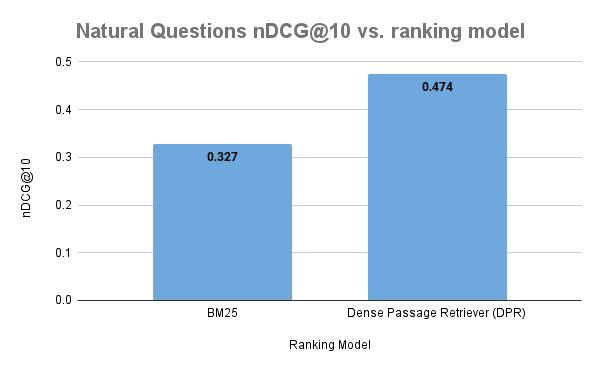
In-domain evaluation of the Dense Passage Retriever (DPR). DPR is an example of Embedding Based Retrieval (EMB).
Suppose we use the DPR model trained on NQ (and other question-answering datasets) and apply the model on MS MARCO. Then we can say something about generalization in a zero-shot setting on MS MARCO.
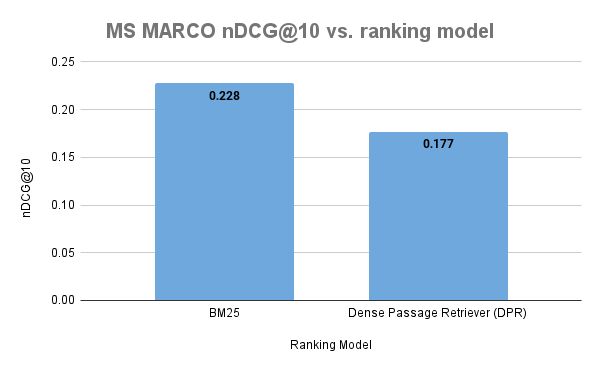
Out-of-domain evaluation of the Dense Passage Retriever (DPR). DPR is an example of Embedding Based Retrieval (EMB). In this zero-shot setting, the DPR model underperforms the BM25 baseline.
This case illustrates that in-domain effectiveness does not necessarily transfer to an out-of-domain zero-shot application of the model. Generally, as observed on the BEIR dense leaderboard, dense embeddings models trained on NQ labels underperform the BM25 baseline across almost all BEIR datasets.
Summary
In this blog post, we introduced zero-shot and out-of-domain IR evaluation. We also introduced the important BEIR benchmark. Furthermore, we highlighted a case study of the DPR model and its generalization when applied out-of-domain in a zero-shot setting.
We summarize this blog post with the following quote from the BEIR paper:
In-domain performance is not a good indicator for out-of-domain generalization. We observe that BM25 heavily underperforms neural approaches by 7-18 points on in-domain MS MARCO. However, BEIR reveals it to be a strong baseline for generalization and generally outperforming many other, more complex approaches. This stresses the point that retrieval methods must be evaluated on a broad range of datasets.
Next blog post in this series
In the next post in this series on zero-shot ranking, we introduce a hybrid ranking model, a model which combines multi-vector representations with BM25. This hybrid model overcomes the limitations of single-vector embedding models, and we prove its effectiveness in a zero-shot setting on the BEIR benchmark.