{ }
Blog
Vespa.ai
Docs
Subscribe
Vespa Blog
We Make AI Work
All Stories
Image from limpreom on Shutterstock
Beyond Vector Search: The Move to Tensor-Based Retrieval
Tensors preserve critical context, making them far better suited for advanced retrieval tasks where precision and explainability matter.
Image from Khanthachai C on Shutterstock.
Vector Search Is Reaching Its Limit. Here’s What Comes Next
As RAG applications evolve, they require richer data representations that capture relationships within and across modalities, like text, images and video.
🎄 Advent of Tensors 2025 🎅
We’re excited to announce Advent of Tensors 2025 — a 24-day coding challenge for anyone curious about tensors.
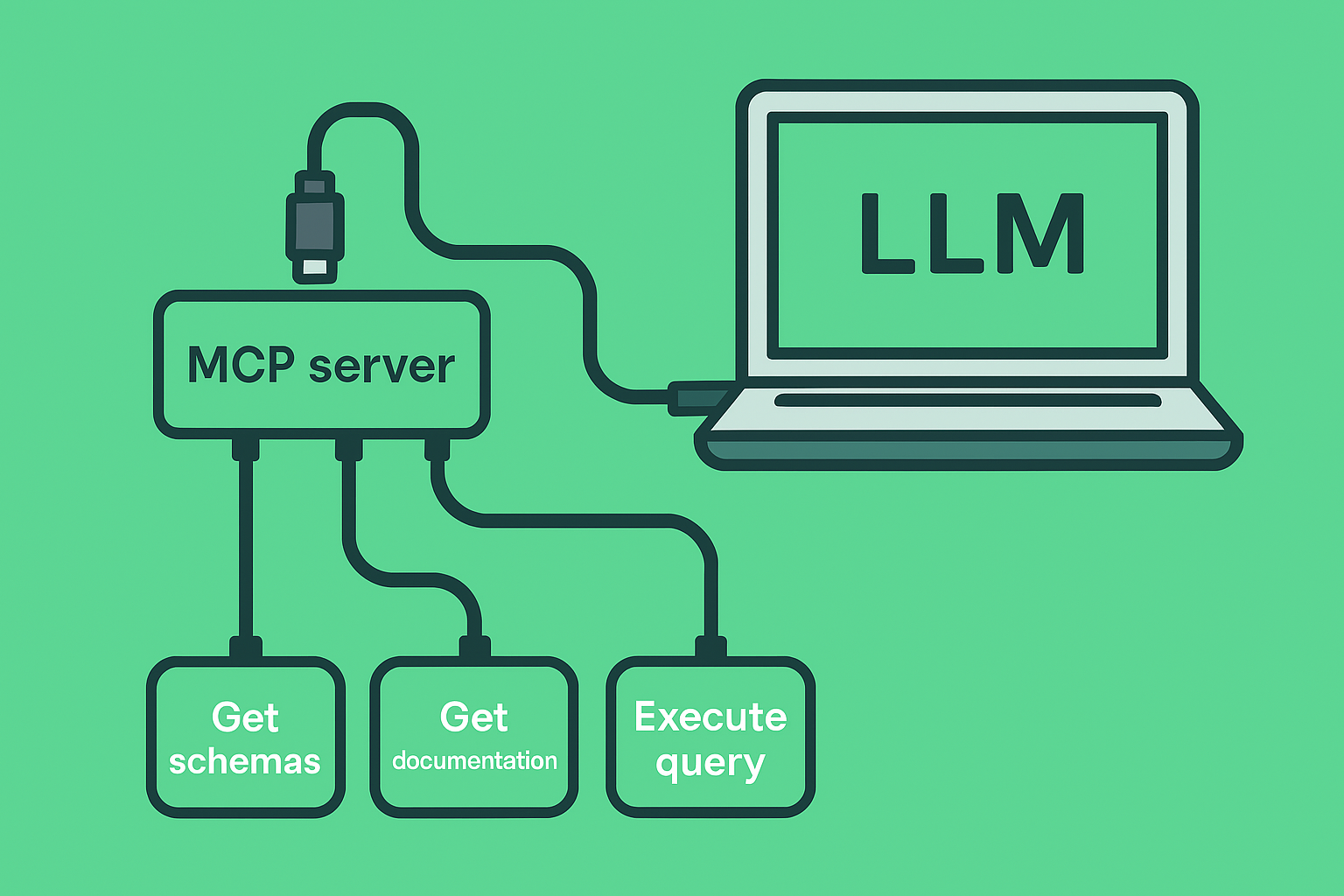
LLMs, Vespa, and a side of Summer Debugging
We built a standalone MCP server in Python, then rewrote it in Java for full Vespa integration — and lived to tell the tale.
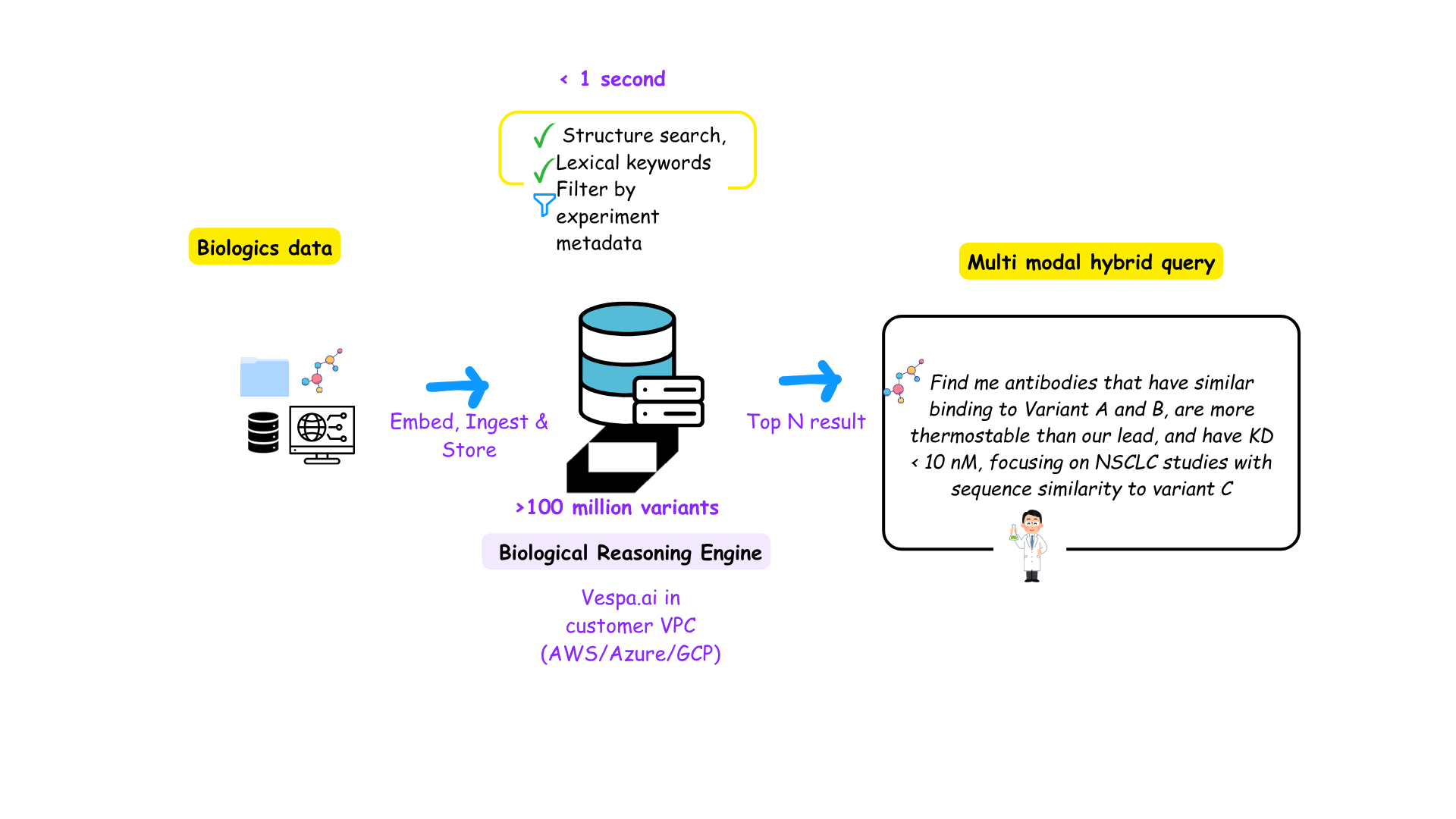
Protein models Need a PLM Store: Turning Model Outputs into Searchable Biological Intelligence- beyond LLM's
A story about bridging AI models, LIMS data, and real-world biologics discovery.
Perplexity.ai
How Perplexity beat Google on AI Search with Vespa.ai
Perplexity demonstrates the quality of their search solution and show what it takes to achieve it
Photo by
Shutter Speed
on
Unsplash
Powering the Next Era of Personalised Commerce
E-commerce has entered a new age. Shoppers expect personalized, dynamic, and trustworthy experiences tailored to their unique needs. How do you balance personalisation, business objectives, system costs, and innovation speed—while...
Photo by
Steve Johnson
on
Unsplash
RAG at Scale: Why Tensors Outperform Vectors in Real-World AI
This a companion post to the previous technical blog post, explaining how to tweak Vespa's ANN parameters.
Vespa Newsletter, September 2025
Advances in Vespa features and performance include new ANN tuning parameters, improvements to Geo filtering, filtering in grouping, and relevance score carry-over to global ranking.
Photo by
Nina Mercado
on
Unsplash
A Short Guide to Tweaking Vespa's ANN Parameters
This a companion post to the previous technical blog post, explaining how to tweak Vespa's ANN parameters.
Photo by
Alina Grubnyak
on
Unsplash
Additions to HNSW in Vespa: ACORN-1 and Adaptive Beam Search
This blog post highlights the latest additions to HNSW in Vespa, how to use them, and what's to come in the future.
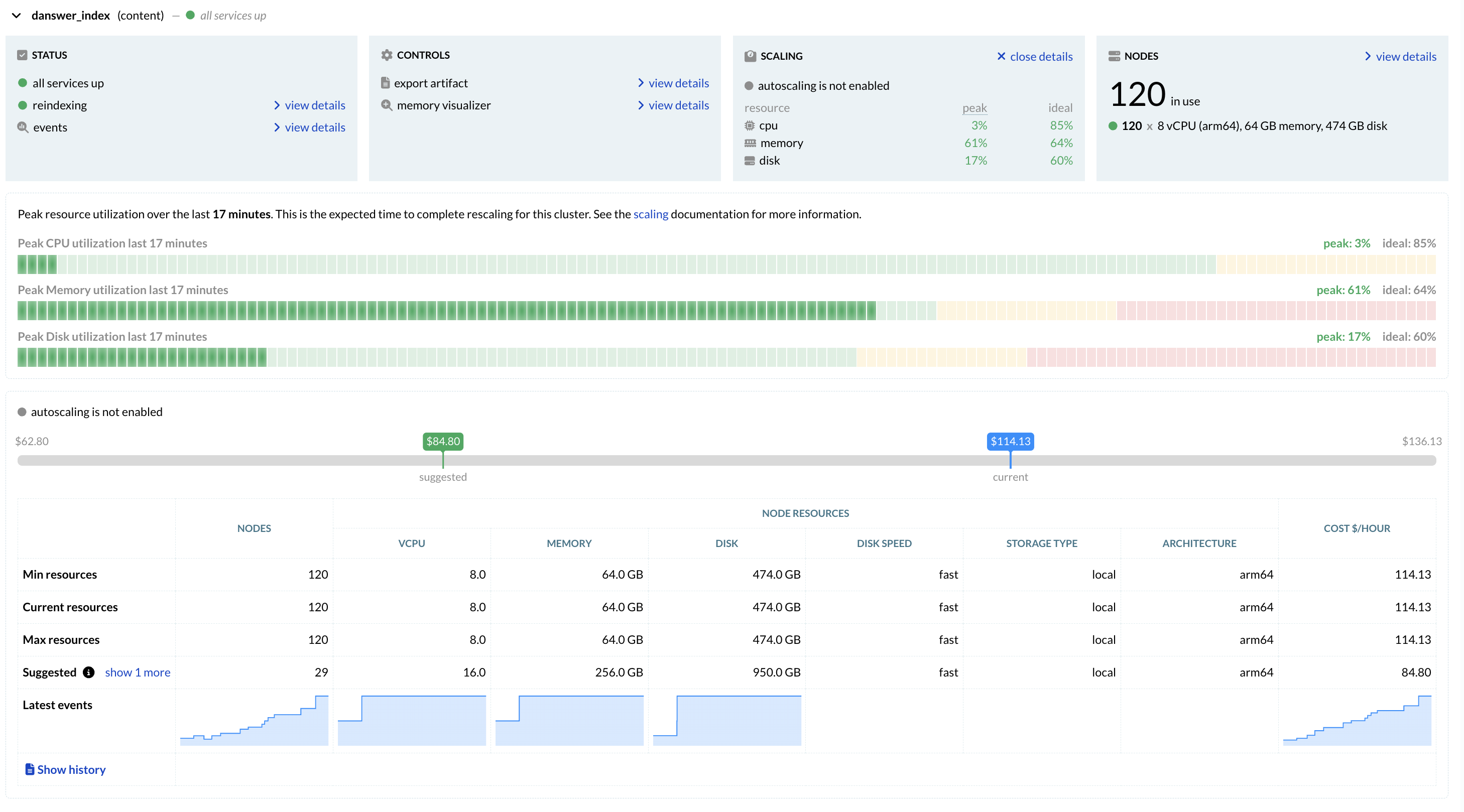
Case study: Using Vespa Cloud Resource Suggestions to optimize costs
How Onyx.app saved 25% with a safe and straightforward automated configuration change, with zero work to optimize spending and performance
« Prev
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Next »
Never miss a
story
from us, subscribe to our newsletter
Subscribe