
From text search and recommendation to ads and online dating, ANN search rarely works in isolation
Anything can be represented by a list of numbers.
For instance, text can be represented by a list of numbers describing the text’s meaning. Images can be represented by the objects it contains. Users of a system can be represented by their interests and preferences. Even time-based entities such as video, sound, or user interactions can be represented by a single list of numbers.
These vector representations describe content or meaning: the original, containing thousands of characters or pixels, is compressed to a much smaller representation of a few hundred numbers.
Most often, we are interested in finding the most similar vectors. This is called k-nearest neighbor (KNN) search or similarity search and has all kinds of useful applications. Examples here are model-free classification, pattern recognition, collaborative filtering for recommendation, and data compression, to name but a few. We’ll see some more examples later in this post.
However, a nearest neighbor search is only a part of the process for many applications. For applications doing search and recommendation, the potential candidates from the KNN search are often combined with other facets of the query or request, such as some form of filtering, to refine the results.
This can severely limit the quality of the end result, as post-filtering can prevent otherwise relevant results from surfacing. The solution is to integrate the nearest neighbor search with filtering, however most libraries for nearest neighbor search work in isolation and do not support this. To my knowledge, the only open-source platform that does is Vespa.ai.
In this post, we’ll take a closer look at approximate neighbor search, explore some real cases combining this with filtering, and delve into how Vespa.ai solves this problem.
Finding the (approximate) nearest neighbors
The representations can be visualized as points in a high-dimension space, even though it’s kind of difficult to envision a space with hundreds of dimensions. This allows us to think of these points as vectors, sometimes called thought vectors, and we can use various distance metrics to measure the likeness or similarity between them. Examples are the dot (or inner) product, cosine angle, or euclidean distance.
Finding the nearest neighbors of a point is reasonably straight-forward: just compute the similarity using the distance metric between the point and all other points. Unfortunately, this brute-force approach doesn’t scale well, particularly in time-critical settings such as online serving, where you have a large number of points to consider.
There are no known exact methods for finding nearest neighbors efficiently. As both the number of points increases and the number of dimensions increase, we fall victim to the curse of dimensionality. In high dimensions, all points are almost equally distant from each other. A good enough solution for many applications is to trade accuracy for efficiency. In approximately nearest neighbors (ANN), we build index structures that narrow down the search space. The implicit neighborhoods in such indexes also help reduce the problem of high dimensions.
You can roughly divide the approaches used for ANNs into whether or not they can be implemented using an inverse index. The inverse index originates from information retrieval and is comparable to the index often found at many books’ back. This index points from a word (or term) to the documents containing it. This can be used for ANNs as well. Using k-means clustering, one can cluster all points and index them by which cluster they belong to. A related approach is product quantization (and its relatives), which splits the vectors into products of lower-dimensional spaces. Yet another is locality-sensitive hashing, which uses hash functions to group similar vectors together. These approaches index the centroids or buckets.
A method that is not compatible with inverted indexes is HNSW (hierarchical navigable small world). HNSW is based on graph structures, is efficient, and lets the graph be incrementally built at runtime. This is in contrast to most other methods that require offline, batch-oriented index building.
As approximate nearest neighbor search has many applications, quite a few tools and libraries exist. A few examples are:
A good overview of tradeoffs for these can be found at https://ann-benchmarks.com/.
Nearest neighbors in search and recommendation
In many applications, such as search and recommendation, the results of the nearest neighbor search is combined with additional facets of the request. In this section, we’ll provide some examples of when this becomes problematic.
Text search
Modern text search increasingly uses representation vectors, often called text embeddings or embedding vectors. Word2vec was an early example. More recently, sophisticated language understanding models such as BERT and other Transformer-based models are increasingly used. These are capable of assigning different representations for a word depending upon the context. For text search, the current state-of-the-art uses different models to encode query vectors and document vectors. These representations are trained so that the inner product of these vectors is maximized for relevant results.
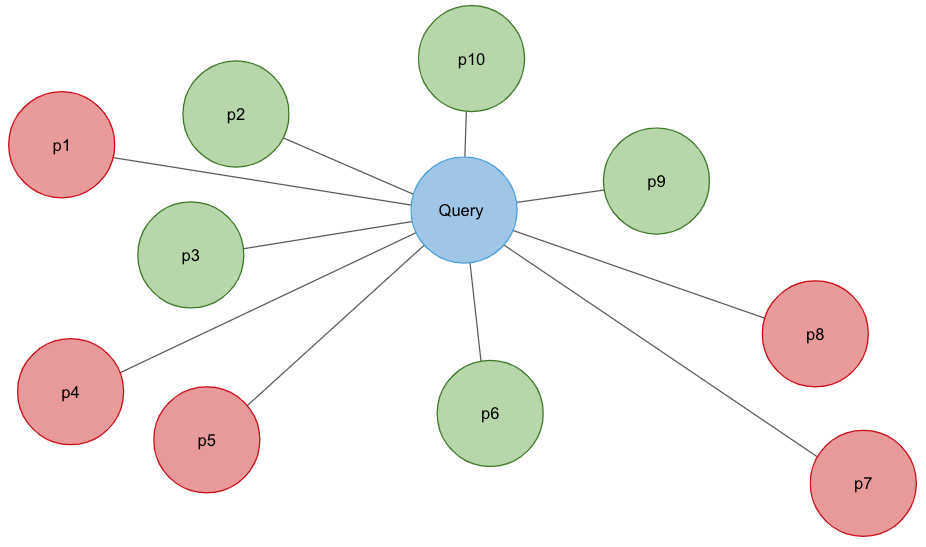
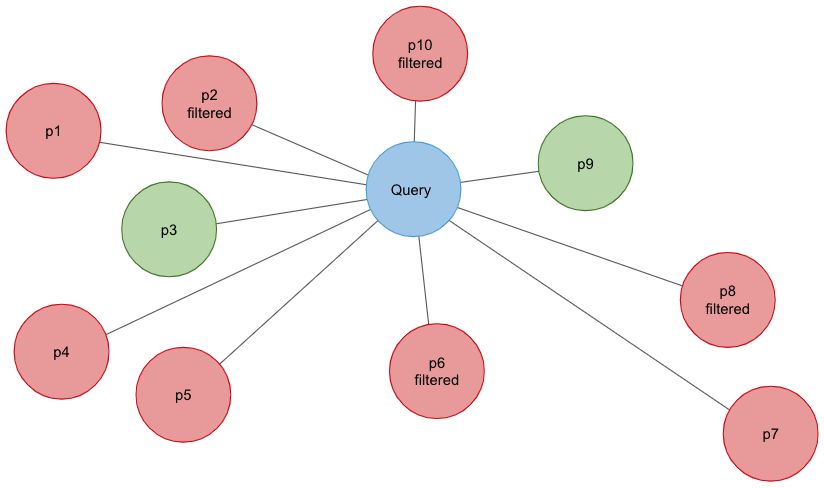
Using embedding vectors in text search is often called semantic search. For many text search applications, we would like to combine this semantic search with other filters. For instance, we can combine a query for “approximate nearest neighbor” with a date filter such as “2020”. The naive approach here is to use one of the ANN libraries mentioned above to perform a nearest neighbor search and then filter out the results.
However, this is problematic. Imagine that 1000 documents are relevant to the query “approximate nearest neighbor”, with 100 added each year over the past 10 years. Assume they all are approximately equally likely to be retrieved from the ANN. So, retrieving the top 100 will result in about 10 documents from each year. Applying the filter “2020” will result in only 10 documents. That means the other 90 relevant documents from 2020 are missed.
Recommendation
Recommender systems, such as YouTube and TikTok, are built to provide continually interesting content to all users. As such, it’s essential to learn the interests or preferences of the user. Such user profiles are represented by one or more vectors, as are the items that should be recommended.
These vectors are often generated by using some form of collaborative filtering. One method is matrix factorization, where the maximum inner product is used as a distance function. Deep learning approaches have recently shown great promise, trained explicitly for the distance function between the user and item vector.
Recommendation systems employ filters to a great degree. Examples are filters for age-appropriate content, NSFW labels, availability of content in various regions due to distribution rights, and user-specified filters blocking certain content. These are examples of direct filters. More indirect filters come in the form of business rules such as diversity and de-duplication, which filters out content that has already been recommended.
The problem of filtering is more evident for recommendation systems than for text search. These filters’ quantity and strength lead to a greater probability that items retrieved from the ANN search are filtered away. So, only a few of the relevant items are actually recommended.
Serving ads
Ad serving systems work much like recommender systems. Given a user profile and a context such as a search query or page content, the system should provide an advertisement relevant to the user. The advertisements are stored with advertiser-specific rules, for instance, who the ad or campaign should target. One such rule is to not exceed the budget of the campaign.
These rules function as filters. Like with text search and recommendation, if these filters are applied after the user-profile based retrieval, there is a probability that an appropriate advertisement is not retrieved. This is particularly important regarding the budget. Income is lost if there are no results retrieved with an available spending budget.
Online dating
In the world of online dating, people have a set of preferences. These can be binary such as gender, age range, location, height, and so on. Interests might be less absolute, such as hiking, loves pets, traveling, and exercise. These interests and preferences can be represented by a vector, and at least parts can be compressed to a representation vector as well.
Suppose retrieval is based on an ANN over interests, and the preferences are applied as a filter afterward. In that case, it’s clear why online dating is hard. As we retrieve the best matches from the ANN, there is a significant probability that all or most of these are filtered out, for instance, by location or by profiles already seen.
Local search
Local search and recommendation is based on geographical location. Given longitude and latitude coordinates, we can find places or businesses within certain distances from a point: finding restaurants near a user is a typical case. Imagine that we have the dining preferences of a user represented as a vector. Likewise, all restaurants are represented by vectors. Then, by performing an ANN search followed by a location filter, we could retrieve the restaurants preferred by the user in their local area.
However, this would not work. Of all the restaurants in the world, only a small fraction are close to the user. The location filter is much stronger than the ANN retrieval. So with a high probability, no results would be produced at all.
Solution
The naive approach to the problems above is simply to request more candidates from the ANN search. This obviously hurts performance, as the workload of both the ANN and post-filtering increases. Besides, this is not guaranteed to work. If you have a strong filter independent of the ANN, there is a real chance of not producing any results at all. The local restaurant case is an example of this, where the location is a strong filter independent of the user profile.
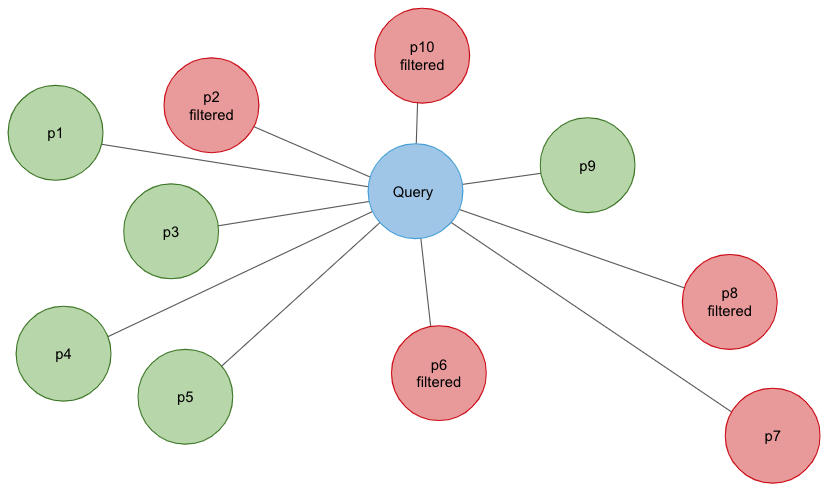
The real solution here is to integrate the filters into the ANN search. Such an algorithm would be able to reject candidates early that don’t pass the filters. This effectively increases the search area from the query point dynamically until enough candidates are found. This guarantees that the requested number of candidates are produced.
Unfortunately, for most ANN libraries, this is not an option as they work in isolation.
Vespa.ai is to my knowledge the only implementation of ANN that supports integrated filtering. The implementation is based on a modified HNSW graph algorithm, and Vespa.ai innovates in 3 main areas:
- Dynamic modification of the graph. Most ANN algorithms require the index to be built offline, but HNSW supports incremental building of the index. Vespa takes advantage of this and supports both adding and removing items in real-time while serving.
- Multi-threaded indexing using lock-free data structures and copy-on-write semantics drastically increase the performance of building the index.
- Metadata filtering modifies the algorithm to skip non-eligible candidates.
To support filtering, Vespa.ai first evaluates the filters to create a list of eligible candidates. During the ANN search, a point close to the query point is selected and the graph is explored by following each node’s edge to its neighbors. Candidates not in the eligibility list are skipped, and the search continues until we have produced enough candidates.
There is a small problem here however. If the eligibility list is small in relation to the number of items in the graph, skipping occurs with a high probability. This means that the algorithm needs to consider an exponentially increasing number of candidates, slowing down the search significantly. To solve this, Vespa.ai switches over to a brute-force search when this occurs. The result is a efficient ANN search when combined with filters.
About Vespa.ai
Vespa.ai is an open-source platform for building applications that do real-time data processing over large data sets. Designed to be highly performant and web-scalable, it is used for such diverse tasks as search, personalization, recommendation, ads, auto-complete, image and similarity search, comment ranking, and more.
One of Vespa.ai’s strengths is that it includes all the necessary features to realize such applications. This means one does not need additional plugins or external services. Thus, it offers a simplified path to deployment in production without coping with the complexity of maintaining many different subsystems.
For more information, please check out approximate nearest neighbor search using HNSW index at vespa.ai.