
A real-world application of parent-child joins and tensor functions to model topic popularity for content recommendation.
Every time a user visits Yahoo.com, we build the best news stream for that user from tens of thousands of candidate articles on a variety of topics such as sports, finance, and entertainment.
To rank these articles, a key feature is the topic’s click-through rate (CTR), a real-time popularity metric aggregated over all articles of that topic. There are two reasons why topic CTR is an important feature for machine-learned ranking:
- It helps the cold-start problem by allowing the model to use the popularity of other articles of that topic as a prior for new articles.
- It reduces a high-dimensional categorical feature like a topic to a single numerical feature (its mean CTR)—this mean encoding is needed for a model to incorporate topics.
In this blog post, we describe how we model topic CTRs using two modern features of Vespa: parent-child joins and tensor functions. Vespa, the open source big data serving engine created by Yahoo, powers all of our content recommendations in real-time for millions of users at scale.
Parent-Child Joins
To model ranking features in Vespa, most features like an article’s length or age are simple properties of the document which are stored within the Vespa document. In contrast, a topic CTR is shared by all documents of that topic.
A simple approach would be to feed the topic CTR to every document about that topic. But this denormalized approach both duplicates data and complicates CTR updates—the updater must first query for all documents of that topic in order to feed the updated CTR to all of them.
The standard solution for this from relational databases is joins through foreign keys, and such joins are supported in Vespa as parent-child relationships.
We model our relationships by storing all topic CTRs in a single “global” document, and each of our articles has a foreign key that points to that global document, as shown in the Figure. This way, when updating CTRs we only need to update the global document and not each individual article, avoiding data duplication.
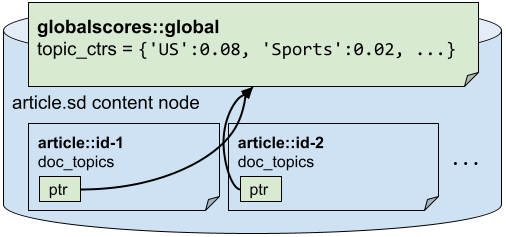
When ranking articles, Vespa uses the foreign key to do a real-time join between each article and the global document to retrieve the topic CTRs. Vespa co-locates the global document on the article content node to reduce the latency of this real-time join, also represented in the Figure.
Vespa seamlessly allows us to write updated CTRs to the global document in real-time while concurrently reading the CTRs for use in article ranking.
The schema definition uses reference for this parent-child relationship:
document globalscores {
field topic_ctrs type tensor<float>(topic{}) {
indexing: attribute
attribute: fast-search
}
}
document article {
field doc_topics type tensor<float>(topic{}) {
indexing: attribute | summary
}
field ptr type reference<globalscores> {
indexing: attribute
}
}
Tensor Ranking
Now that our data is modeled in Vespa, we want to use the CTRs as features in our ranking model.
One challenge is that some articles have 1 topic (so just 1 topic CTR) while some articles have 5 topics (with 5 CTRs). Since machine learning generally requires each article to have the same number of features, we take the average topic CTR and the maximum topic CTR, aggregating a differing number of CTRs into a fixed number of summary statistics.
We compute the average and maximum using Vespa’s Tensor API. A tensor is a vector with labeled dimensions, and Vespa provides API functions like sum, argmax, and * (elementwise multiplication) that operate on input tensors to compute features.
The rank profile code that computes these ranking features is:
import field ptr.topic_ctrs as global_topic_ctrs {}
rank-profile yahoo inherits default {
# helper functions
function AVG_CTR(weights, ctrs) {
# weighted average CTR
expression: sum(weights * ctrs) / sum(weights)
}
function MAX_CTR(weights, ctrs) {
# weighted max, then use unweighted CTR
expression: sum( argmax(weights * ctrs) * ctrs )
}
# ranking features
function TOPIC_AVG_CTR() {
expression: AVG_CTR(attribute(doc_topics), attribute(global_topic_ctrs))
}
function TOPIC_MAX_CTR() {
expression: MAX_CTR(attribute(doc_topics), attribute(global_topic_ctrs))
}
}
Rank Profile Walkthrough
Suppose an article is about two topics each with an associated weight:
attribute(doc_topics) = <'US': 0.7, 'Sports': 0.9>
And in the global document, the real-time CTR values for all topics are:
topic_ctrs = <'US': 0.08, 'Sports': 0.02, 'Finance': 0.05, ...>
The first import line does a real-time join between the article’s foreign key and the global document, so that the article ranking functions can reference the global CTRs as if they were stored with each article:
global_topic_ctrs = ptr.topic_ctrs = <'US': 0.08, 'Sports': 0.02, 'Finance': 0.05, ...>
For both of our features TOPIC_AVG_CTR and TOPIC_MAX_CTR, the first step uses the * elementwise multiplication operator in Vespa’s Tensor API, which effectively does a lookup of the article’s topics in the global tensor:
weights * ctrs
= attribute(doc_pub) * attribute(global_pub_ctrs)
= <'US': 0.7, 'Sports': 0.9> * <'US': 0.08, 'Sports': 0.02, 'Finance': 0.05, ...>
= <'US': 0.056, 'Sports': 0.018>
Then TOPIC_AVG_CTR computes a weighted average CTR by summing and normalizing by the weights:
TOPIC_AVG_CTR
= sum(weights * ctrs) / sum(weights)
= sum(<'US': 0.056, 'Sports': 0.018>) / sum(<'US': 0.7, 'Sports': 0.9>)
= 0.074 / 1.6
= 0.046
(Note this weighted average of 0.046 is closer to the Sports CTR=0.02 than the US CTR=0.08 because Sports had a higher topic weight.)
And TOPIC_MAX_CTR finds the CTR of the entity with the maximum weighted CTR:
argmax(weights * ctrs)
= argmax(<'US': 0.056, 'Sports': 0.018>)
= <'US': 1>
argmax(weights * ctrs) * ctrs
= <'US': 1> * <'US': 0.08, 'Sports': 0.02, 'Finance': 0.05, ...>
= <'US': 0.08>
(With a final sum to convert the mapped tensor to the scalar 0.08.)
These two examples demonstrate the expressiveness of Vespa’s Tensor API to compute useful features.
Ultimately TOPIC_AVG_CTR and TOPIC_MAX_CTR are two features computed in real-time for every article during ranking. These features can then be added to any machine-learned ranking model—Vespa supports gradient-boosted trees from XGBoost and LightGBM, and neural networks in TensorFlow and ONNX formats.
Final Thoughts
While we could have stored these topic CTRs in some external store, we would have essentially needed to fetch all of them when ranking as every topic is represented in our pool of articles. Instead, Vespa moves the computation to the data by co-locating the global feature store on the article content node, avoiding network load and reducing system complexity.
We also keep the global CTRs in-memory for even faster performance with the aptly named attribute: fast-search. Ultimately, the Vespa team optimized our use case of parent-child joins and tensors to rank 10,000 articles in just 17.5 milliseconds!
This blog post described just two of the many ranking features used for real-time content recommendation at Verizon Media, all powered by Vespa.