

Photo by israel palacio on Unsplash
There is a growing interest in AI-powered vector representations of unstructured multimodal data and searching efficiently over these representations. This blog post describes how your organization can unlock the full potential of multimodal AI-powered vector representations using Vespa – the industry-leading open-source big data serving engine.
Introduction
Deep Learning has revolutionized information extraction from unstructured data like text, audio, image, and videos. Furthermore, self-supervised learning algorithms like data2vec accelerate learning representations of speech, vision, text, and multimodal representations combining these modalities. Pre-training deep neural network models using self-supervised learning without expensive curated labeled data helps scale machine learning as adoption and fine-tuning for a specific task requires fewer labeled examples.
Representing unstructured multimodal data as vectors or tensors unlocks new and exciting use cases it wasn’t easy to foresee just a few years ago. Even a well-established AI-powered use case like search ranking, which has been using AI to improve the search results for decades, is going through a neural paradigm shift driven by language models like BERT.
These emerging multimodal data-to-vector models increase the insight and knowledge organizations can extract from their unstructured data. As a result, organizations leveraging this new data paradigm will have a significant competitive advantage over organizations not participating in this paradigm shift. Learning from structured and unstructured data has historically primarily been performed offline. However, advanced organizations with access to modern infrastructure and competence have started transferring the learning process to onstage, using real-time, in-session contextual features to improve AI predictions.
One example of real-time online inference or prediction is within-cart
recommendation systems,
where grocery and e-commerce sites recommend or predict
related items to supplement the user’s current cart contents.
An AI-powered recommendation model for this use case could use item-to-item similarity
or past sparse user-to-item interactions.
Still, without a doubt, using the real-time context, in this case, the cart’s contents,
can improve the model’s accuracy. Furthermore,
creating add-to-cart suggestions for all possible combinations offline is impossible
due to the combinatoric explosion of likely cart items.
This use case also has the challenging property that the number of things to choose from is extensive,
hundreds of millions in the case of Amazon. In addition, business constraints like in-stock status limit the candidate selection.
Building technology and infrastructure to perform computationally complex distributed AI inference over billions of data items with low user-time serving latency constraints is one of the most challenging problems in computing.
Vespa - Serving Engine
Vespa, the open-source big data serving engine, specializes in making it easy for an any-sized organization to move AI inference computations online at scale without investing a significant amount of resources in building infrastructure and technology. Vespa is a distributed computation engine that can scale in any dimension.
- Scale elastically with data volume - handling billion scale datasets efficiently without pre-provisioning resources up-front.
- Scale update and ingestion rates to handle evolving real-time data.
- Scale with query volume using state-of-the-art retrieval and index structures and fully use modern hardware stacks.
In Vespa, AI is a first-class citizen and not an after-thought. The following Vespa primitives are the foundational building blocks for building an online AI serving engine:
- CRUD operations at scale. Dataset sizes vary across organizations and use cases. Handling fast-paced evolving datasets is one of Vespa’s core strengths. Returning to our in-cart recommendation system for a moment, handling in-stock status updates, price changes, or real-time click feedback can dramatically improve the experience - imagine recommending an item out of stock? A lost revenue opportunity and a negative user experience.
- Document Model. Vespa’s document model supports structured and unstructured field types, including tensor fields representing single-order dense vectors. Vespa’s tensor storage and compute engine is built from the ground up. The document model with tensor also enables feature-store functionality, accessing real-time features close to the data. Features stored as Vespa attributes support in place real-time updates at scale (50K updates/s per tensor field per compute node).
- A feature-rich query language. Vespa’s SQL-like query language enables efficient online selection over potentially billions of rows, combining structured and unstructured data in the same query.
- Machine Learning frameworks and accelerator integrations. Vespa integrates with the most popular machine learning frameworks like Tensorflow, PyTorch, XGboost, and LightGBM. In addition, Vespa integrates with ONNX-Runtime for accelerated inference with large deep neural network models that accelerate powerful data-to-vector models. Vespa handles model versioning, distribution, and auto-scaling of online inference computations. These framework integrations complement Vespa’s native support for tensor storage and calculations over tensors.
- Efficient Vector Search. AI-powered vector representations are at the core of the unstructured data revolution. Vespa implements a real-time version of the HNSW algorithm for efficient Vector search, an implementation that is vetted and verified with multiple vector datasets on ann-benchmarks.com. Vespa supports combining vector search with structured query filters at scale.
Get Started Today with Vector Search using Vespa Cloud.
We have created a getting started with Vector Search sample application which, in a few steps, shows you how to deploy your Vector search use case to Vespa Cloud. Check it out at github.com/vespa-cloud/vector-search.
The sample application features:
- Deployment to Vespa Cloud environments (dev, perf, and production) and how to perform safe deployments to production using CI/CD
- Vespa Cloud’s security model
- Vespa Cloud Auto-Scaling and pricing, optimizing the deployment cost by auto-scaling by resource usage
- Interacting with Vespa Cloud - indexing your vector data and searching it at scale.
For only $3,36 per hour, your organization can store and search 5M 768 dimensional vectors, deployed in Vespa Cloud production zones with high availability, supporting thousands of inserts and queries per second.
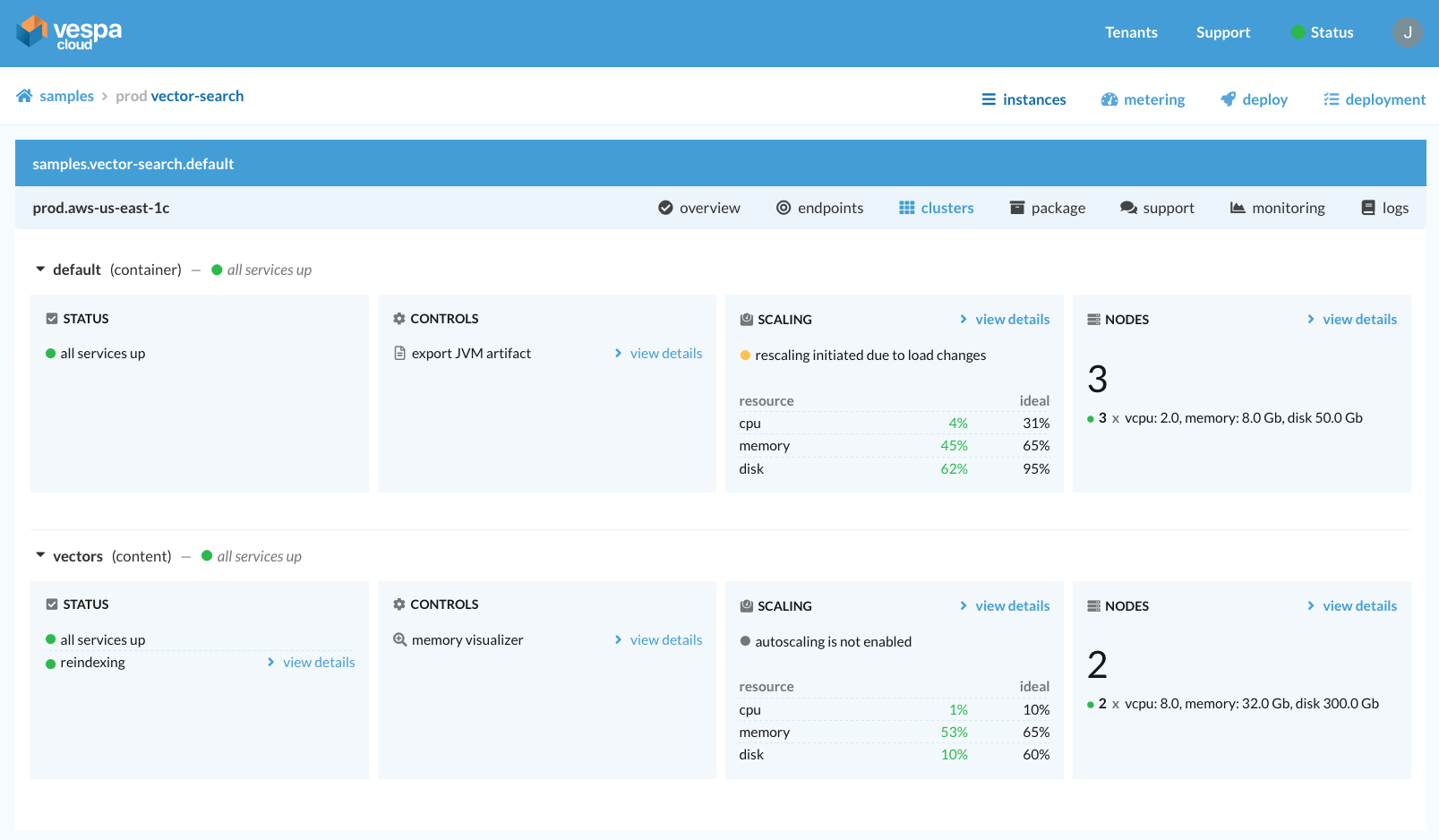
Vespa Cloud Console. Snapshot while auto-scaling of stateless container cluster in progress.
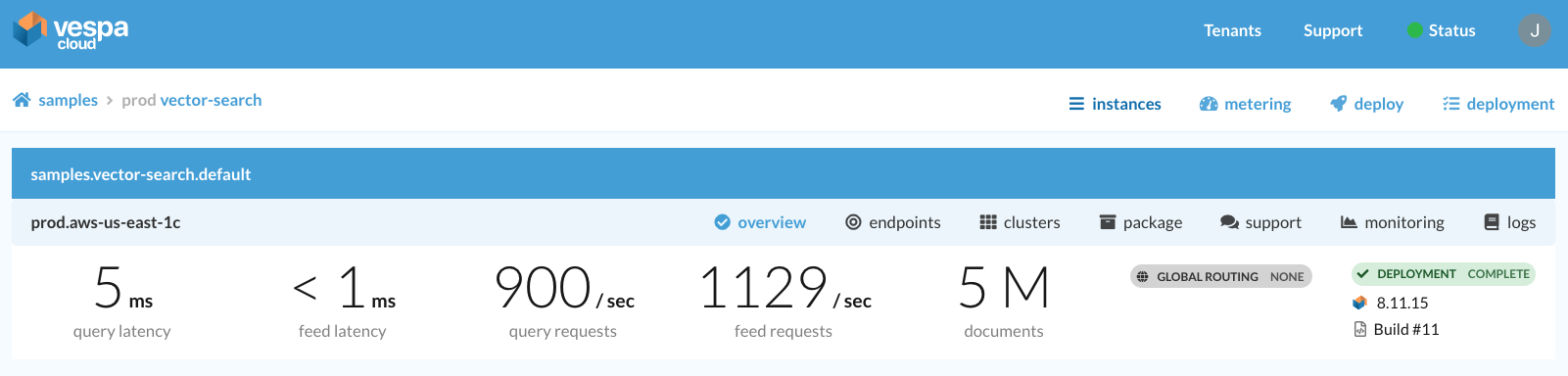
Vespa Cloud Console. Concurrent real-time indexing of vectors while searching. Scale as needed to meet any low latency serving use case.
With this vector search sample application, you have a great starting point for implementing your vector search use case, without worrying about managing complex infrastructure. See also other Vespa sample applications using vector search:
-
State-of-the-art text ranking: Vector search with AI-powered representations built on NLP Transformer models for candidate retrieval. The application has multi-vector representations for re-ranking, using Vespa’s phased retrieval and ranking pipelines. Furthermore, the application shows how embedding models, which map the text data to vector representation, can be deployed to Vespa for run-time inference during document and query processing.
-
State-of-the-art image search: AI-powered multi-modal vector representations to retrieve images for a text query.
These are examples of applications built using AI-powered vector representations.
Vespa is available as a cloud service; see Vespa Cloud - getting started, or self-serve Vespa - getting started.