


Photo by Christopher Burns on Unsplash
This blog post describes Vespa’s support for combining approximate nearest neighbor search, or vector search, with query-time filters or constraints to tackle real-world search and recommendation use cases at scale. The first section covers the data structures Vespa builds to support fast search in vector fields and other field types. It then goes through the two primary strategies for combining vector search with filters; pre- or post-filtering. Finally, an intro to two Vespa parameters for controlling vector search filtering behavior to achieve optimal functionality with the lowest possible resource usage.
Introduction
Many real-world applications require query-time constrained vector search. For example, real-time recommender systems using vector search for candidate retrieval need to filter recommendations by hard constraints like regional availability or age group suitability. Likewise, search systems using vector search need to support filtering. For example, typical e-commerce search interfaces allow users to navigate and filter search results using result facets.
Vespa’s document model supports representing multiple field and collection types in the same
document schema.
Supported Vespa schema field types
include string, long, int, float, double, geo position, bool, byte, and tensor fields.
Vespa’s first-order dense tensor fields represent vector fields.
Vespa’s tensor fields support different tensor cell precision types,
ranging from int8 for binary vectors to bfloat16, float, and double for real-valued vectors.
Allowing vectors and other field types in the same document schema enables searching the vector field(s) in
combination with filters expressed over other fields.
This blog post uses the following Vespa document schema to exemplify combining vector search with filters:
schema track {
document track {
field title type string {
indexing: index | summary
index: enable-bm25
match: text
}
field tags type array<string> {
indexing: attribute | summary
attribute: fast-search
rank: filter
match: exact
}
field embedding type tensor<float>(x[384]) {
indexing: attribute | index
attribute {
distance-metric: euclidean
}
}
}
rank-profile closeness {
inputs {
query(query_embedding) tensor<float>(x[384])
}
first-phase {
expression: closeness(field, embedding)
}
}
}
The practical nearest neighbor search guide uses a similar schema, indexing a subset of the last.fm track dataset. The simplified track document type used in this post contains three fields: track title, track tags, and track embedding:
titleis configured for regular text indexing and matching using the default matching mode for indexedstringfields, match:text.tagsis an array of strings, configured for exact database-style matching using Vespa’s match:exact.embeddingis a first-order tensor (vector) using float tensor cell precision.x[384]denotes the named dimension (x) with dimensionality (384). A vector field searched using Vespa’s nearestNeighbor query operator must define a distance-metric. Also see the Vespa tensor user guide.
The embedding vector field can be produced by, for example, a dense embedding model like sentence-transformers/all-MiniLM-L6-v2.
Vespa builds data structures for efficient query evaluation for fields with indexing: index or attribute fields defined with the attribute: fast-search property. The data structures used for non-tensor fields are variants of the classic inverted index data structure. The inverted index data structure enables fast query evaluation of boolean queries, expressed using Vespa’s query language:
select * from track where tags contains "90s" and tags contains "pop"
Vespa builds Hierarchical Navigable Small World (HNSW) graphs for first-order dense tensor fields or vector fields to support a fast, approximate nearest neighbor search. Read more in the introducing HNSW support in Vespa blog post.
Vespa’s implementation of the HNSW graph data structure allows for fast approximate nearest neighbor searches like:
select * from track where {targetHits:3, approximate:true}nearestNeighbor(embedding, query_embedding)
This example searches for the three (approximate) nearest neighbors of the input query embedding vector using the configured distance-metric.
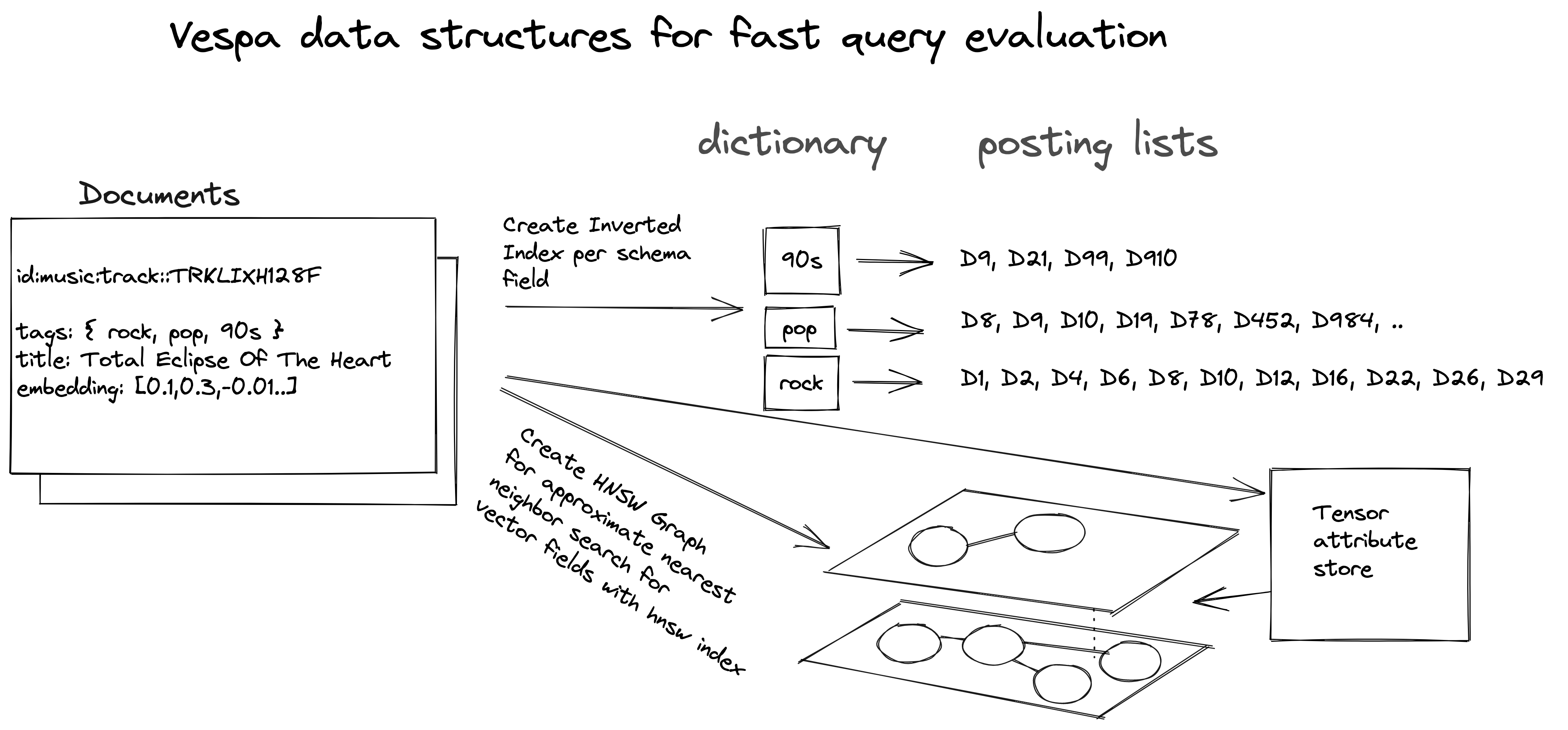 Figure 1 illustrates, on a high level, Vespa’s data structures for all types of fields,
including vector fields with HNSW enabled.
Figure 1 illustrates, on a high level, Vespa’s data structures for all types of fields,
including vector fields with HNSW enabled.
Search query planning and estimation
Vespa builds a query plan that tries to optimize the query execution. A significant part of the execution planning is estimating how many documents each branch of the query tree will match. The estimation process uses information present in per-field inverted index data structures.
Query terms searching fields with inverted index structures enabled, use the size of posting lists as the hit count estimate. Other terms in the query might use the number of searchable documents as an estimate, as it’s not known how many hits they will produce. Furthermore, subtrees of ANDed terms use the minimum estimate of their children, and OR-terms use the saturated sum of their children. Finally, the complete query hit estimate is scaled with the number of searchable documents to get an estimated-hit-ratio [0, 1].
Using the high-level illustration in Figure 1, a query for tags contains “90s” or tags contains “pop” is estimated to match the sum of the length of the posting lists of the two terms (4+7=11). A query for tags contains “90s” and tags contains “pop” is estimated to match at most four documents (min(4,7) = 4). The hit estimates determine the query execution plan. An optimal query evaluation for 90s and pop would start with the shortest posting list (90s) and intersect with the postings of the longest (pop). The query execution with the intersection of these two posting lists will only match one document (D9), which is less than the estimated hit count. Estimation is a best-effort process, overestimating the number of documents the query will match.
The posting lists of the inverted index can be of different granularity, which can help optimize the query execution.
For example, using rank: filter for attribute fields
with fast-search, enables compact posting list representation for frequent terms.
Combining exact nearest neighbor search with filters
Given a query vector, Vespa’s nearestNeighbor
query operator finds the (targetHits) nearest neighbors using the configured
distance-metric.
The retrieved hits are exposed to first-phase ranking, where the retrieved neighbors can be re-ranked using more sophisticated ranking models beyond the pure vector similarity.
The query examples in this blog post use the closeness rank feature
directly as the first-phase rank expression:
rank-profile closeness {
first-phase {
expression: closeness(field, embedding)
}
}
Developers might switch between using approximate:true, which searches the HNSW
graph data structure, and using exact search, setting approximate:false.
The ability to switch between approximate and exact enables quantifying accuracy
loss when turning to the faster, but approximate search. Read more about HNSW parameters and accuracy versus performance
tradeoffs in the Billion-scale vector search with Vespa - part two blog post.
It’s trivial to combine the exact nearest neighbor search with query-time filters, and the computational
complexity of the search is easy to understand. For example, the following query searches for the exact
nearest neighbors of the query embedding using the euclidean distance-metric,
restricting the search for neighbors to only consider tracks tagged with rock:
select * from track where {targetHits:5, approximate:false}nearestNeighbor(embedding, query_embedding) and tags contains "rock"
The query execution planner estimates that the exact nearestNeighbor query operator
will match all searchable documents,
while the tags term will match a restricted subset.
The most optimal way to evaluate this query is to first find the documents matching the filter,
and then perform an exact nearest neighbor search. During the exact search, Vespa reads the vector data
from the tensor attribute store and does not touch the HNSW graph.
 Figure 2 illustrates the computational cost (driven mainly by distance calculations)
versus an increasing number of filter matches (% hit count rate) using exact search filters.
A more restrictive filter uses less resources as it involves fewer distance calculations.
Figure 2 illustrates the computational cost (driven mainly by distance calculations)
versus an increasing number of filter matches (% hit count rate) using exact search filters.
A more restrictive filter uses less resources as it involves fewer distance calculations.
Note that the figure uses computational cost and not latency. It is possible to reduce search latency by using more threads to parallelize the exact search, but the number of distance calculations involved in the query execution stays the same.
Combining approximate nearest neighbor search with filters
Using exact nearest neighbor search for web-scale search and recommendation problems quickly becomes prohibitively expensive. As a result, many turn to the less resource-intensive approximate nearest neighbor search, accepting an accuracy loss to reduce serving cost. There are two high-level strategies for combining boolean query evaluation over inverted indexes with approximate nearest neighbor search: post-filtering and pre-filtering.
Post-filtering strategy
This strategy evaluates the approximate nearest neighbors first and runs the constrained filter
over the retrieved targetHits hits. This strategy is characterized as post-filtering as the
filter constraints are considered only over the retrieved targetHits closest neighbors.
The disadvantage of this approach is that restrictive filters (for example, the tag 90s from Figure 1)
will cause the search to expose fewer hits to ranking than the wanted targetHits.
In the worst case, the post-filters eliminate all retrieved neighbors and expose zero documents to ranking.
The advantage of this strategy is that the serving performance impact of constrained search is negligible
compared to unconstrained approximate nearest neighbor search.
Another aspect is that the hits which survive the post-filter are within the original targetHits.
In other words, the neighbors exposed to ranking are not distant compared to the nearest.
Pre-filtering strategy
This strategy evaluates the filter part of the query over the inverted index structures first.
Then, it uses the resulting document IDs from the filter execution as input to the search for approximate nearest neighbors.
The search for neighbors traverses the HNSW graph and each candidate neighbor is looked up in the
document ID list from the filter execution.
Neighbors not on the document ID list are ignored and the greedy graph search continues until
targetHits hits have been found.
This filtering strategy is known as pre-filtering, as the filters go first before searching
for the approximate nearest neighbors. With pre-filtering, the probability of exposing targetHits
to the ranking phase is much higher than with the post-filtering approach.
The disadvantage is that the performance impact is higher than with the post-filter strategy.
In addition, the retrieved neighbors for a restrictive filter might be somewhat distant neighbors
than the nearest neighbor of the query embedding.
Distant neighbors could be combated by specifying a
distance threshold
as another constraint for the approximate nearestNeighbor query operator.
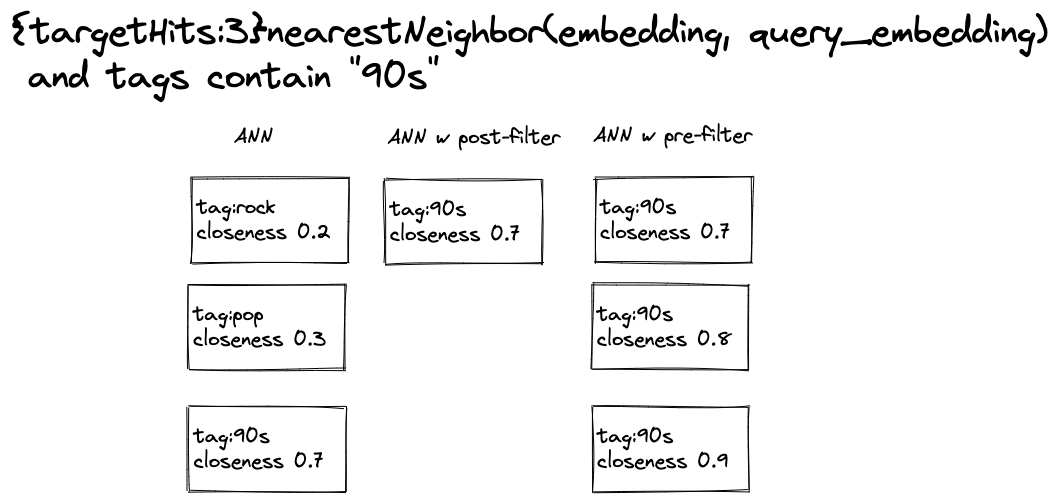 Figure 3 summarizes the strategies used for approximate nearest neighbor search with filtering.
In the case of post-filtering, only one hit is exposed to the ranking phase after the post-filter is
evaluated. In the case of pre-filtering, two additional hits were exposed, but they
are more distant neighbors.
Figure 3 summarizes the strategies used for approximate nearest neighbor search with filtering.
In the case of post-filtering, only one hit is exposed to the ranking phase after the post-filter is
evaluated. In the case of pre-filtering, two additional hits were exposed, but they
are more distant neighbors.
Filtering strategies and serving performance
From a performance and serving cost perspective, one can summarize on a high level:
-
Unconstrained approximate nearest neighbor search without filters is the fastest option, but real-world applications need constrained vector search. Pre-building several nearest neighbor indexes using pre-defined constraints offline also cost resources and index management.
-
Post-filtering is less resource-intensive than pre-filtering for the same number of
targetHits. IncreasingtargetHitsto combat the effect of post-filtering changes cost of the query as increasingtargetHitsincreases the number of distance calculations. -
Pre-filtering uses more resources than post-filtering for the same number of
targetHits. Pre-filtering needs to execute the filter and then search theHNSWgraph, constrained by the document ID list produced by the pre-filter execution.
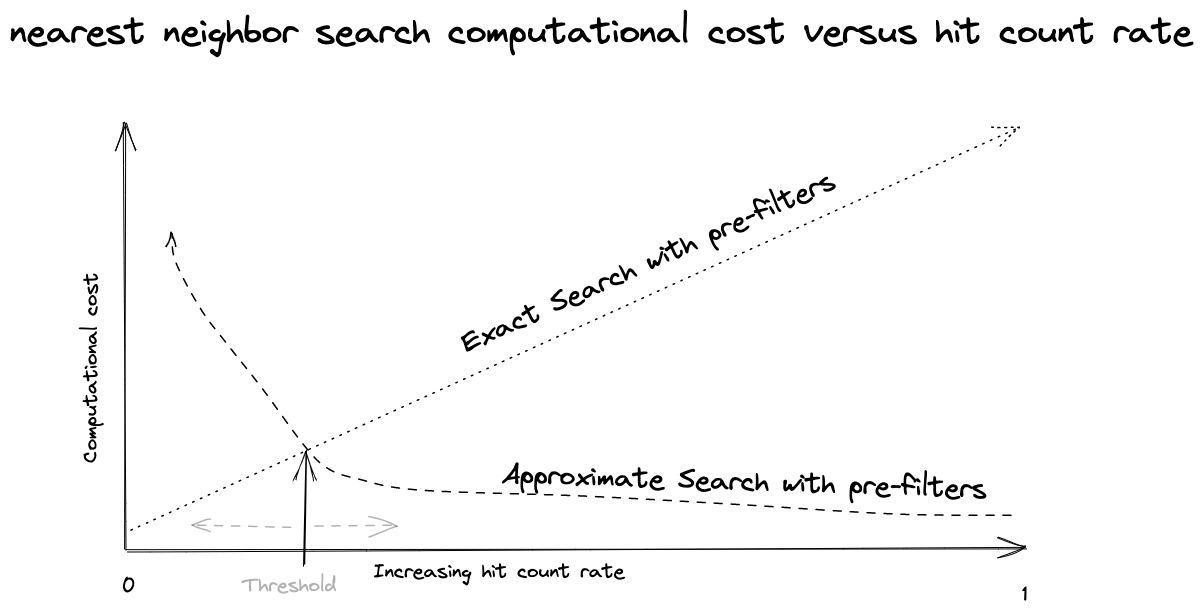 Figure 4 Approximate search with pre-filtering versus exact search with pre-filtering
Figure 4 Approximate search with pre-filtering versus exact search with pre-filtering
Figure 4 illustrates the performance characteristics of approximate search and exact search when using pre-filtering with increasing hit count rate.
With the pre-filtering strategy, searching the HNSW graph with a restrictive pre-filter
result causes the greedy graph search to traverse many nodes before finding the targetHits
which satisfies the document ID list from the pre-filter execution.
Due to this, there is a sweet spot or threshold where an exact search with filters
has a lower computational cost than an approximate search using the document ID list from the pre-filter execution.
The actual threshold value depends on vector dimensionality, HNSW graph properties,
and the number of vectors indexed in the Vespa instance.
Controlling the filtering behavior with approximate nearest neighbor search
Vespa exposes two parameters that control the query-time filtering strategy. These parameters give the developer flexibility in choosing a method that fits the application use case while hedging performance and resource cost.
The schema rank-profile parameters are:
- post-filter-threshold - default 1.0
- approximate-threshold - default 0.05
These parameters were introduced in Vespa 7.586.113, and can be configured in the rank profile, defined in the schema, or set using the query API on a per-query request basis. The query api parameters are:
- ranking.matching.postFilterThreshold - default 1.0
- ranking.matching.approximateThreshold - default 0.05
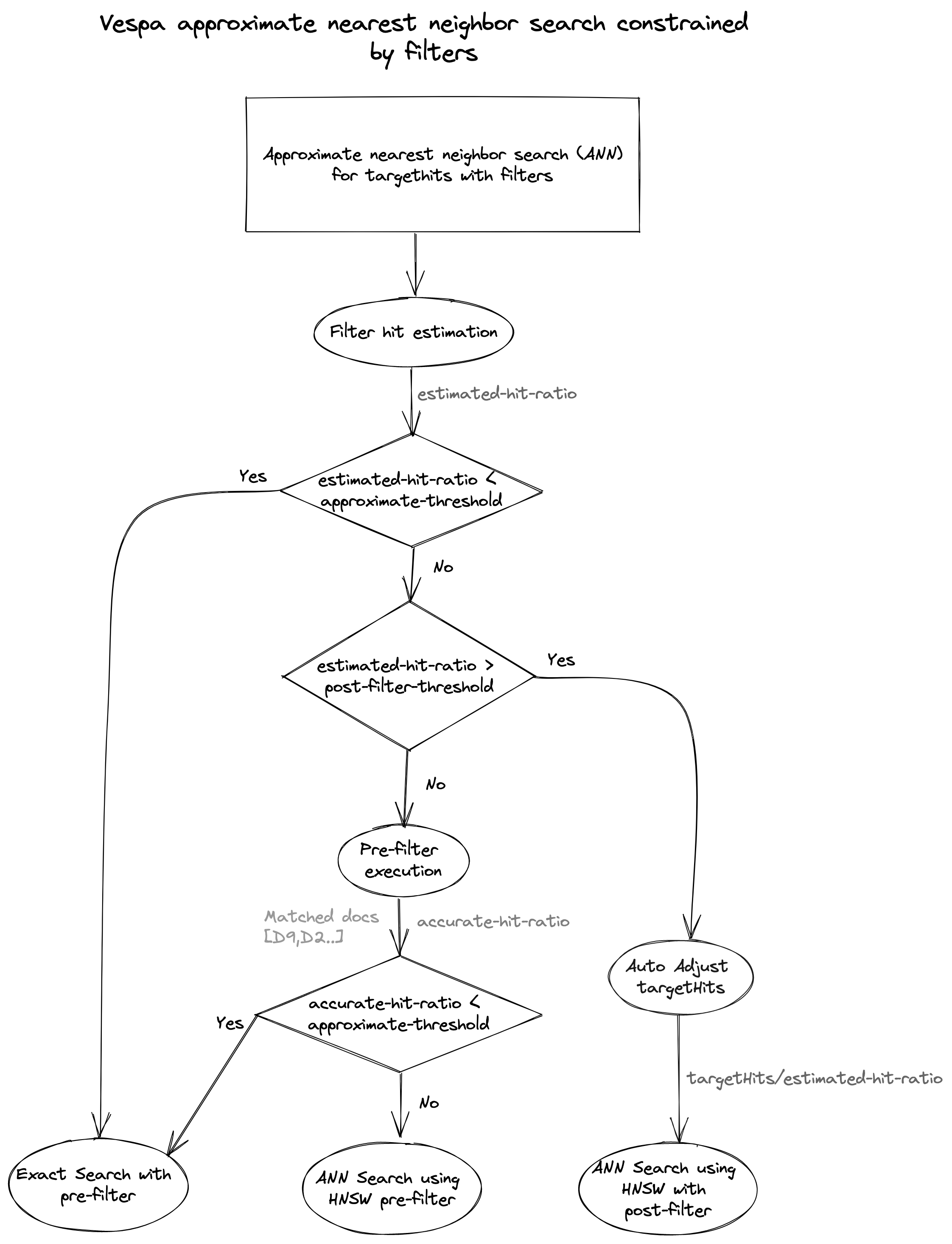 Figure 5 The flowchart shows how Vespa selects the
strategy for an approximate nearest neighbor (ann) search for
Figure 5 The flowchart shows how Vespa selects the
strategy for an approximate nearest neighbor (ann) search for targetHits with filters using mentioned parameters.
-
Filter hit estimation: First, Vespa estimates the filter hit ratio of the query. The resulting estimated-hit-ratio is compared with the two parameters to select between pre-filtering or post-filtering.
-
Exact search with pre-filters: Vespa switches from approximate to exact search with pre-filters based on estimated-hit-ratio.
-
ANN search using HNSW with post-filters: The estimated-hit-ratio crosses the
post-filter-thresholdand the post-filtering strategy is trigged.
Vespa will auto-adjusttargetHitstotargetHits/estimated-hit-ratio. By increasing thetargetHitsusing the estimated-hit-ratio the chance of exposing the user-specifiedtargetHitsto ranking increases.
The default post-filter-threshold is 1.0, hence effectively disabling this decision branch by default.
- Pre-filter execution:
Vespa executes the filter using the most efficient posting list representations. The result of this execution is a list of document IDs matching the filter and an accurate-hit-ratio. The accurate-hit-ratio is used to choose between:
-
ANN search using HNSW with pre-filters: Vespa uses the list of document IDs matching the filter while searching the HNSW graph for the
targetHitsnearest neighbors, skipping all neighbors of the query vector that are not present in the document IDs list. -
Exact search with pre-filters: Vespa switches from approximate to exact search with pre-filters since accurate-hit-ratio is less than
approximate-threshold.
Parameter usage guide
This section guides on how to use the introduced parameters to achieve pre-filtering, post-filtering, or allowing Vespa to choose the strategy dynamically based on the filter hit count ratio estimates.
Pre-filtering with exact search fallback
Pre-filtering is the default evaluation strategy, and this example shows the default settings.
This combination will never consider post-filtering, only pre-filtering.
Developers can tune the approximate-threshold to optimize the sweet spot threshold for falling back to exact search.
rank-profile pre-filtering-with-fallback {
post-filter-threshold: 1.0
approximate-threshold: 0.05
}
Post-filtering with exact search fallback
The following example uses post-filtering as a rule and pre-filtering is effectively disabled.
This strategy will always search the HNSW graph unconstrained, unless the estimated-hit-ratio
is less than the approximate-threshold of 5% where it uses exact search. Vespa’s post-filtering
implementation adjusts targetHits to targetHits/estimated-hit-ratio to increase the chance
of exposing the real targetHits to ranking. By auto-adjusting the targetHits, developers don’t need
to guess a higher value for targetHits to overcome the drawback of the post-filtering strategy.
rank-profile post-filtering-with-fallback {
post-filter-threshold: 0.0
approximate-threshold: 0.05
}
Let Vespa choose between pre- and post-filtering
The previous examples set extreme values for post-filter-threshold, either disabling or enabling it.
The following combination allows Vespa to choose the strategy
dynamically for optimal performance using the estimated-hit-ratio.
rank-profile hybrid-filtering {
post-filter-threshold: 0.75
approximate-threshold: 0.05
}
This parameter combination will trigger post-filtering with auto-adjusted targetHits for relaxed filters,
estimated to match more than 75% of the documents.
Moderate filters (between 5% and 75%) are evaluated using pre-filtering
and restrictive filters (< 5%) are evaluated using exact search. As mentioned in the Search query planning and estimation
section, the estimated-hit-ratio is an estimate which is conservative and will always overshoot. As a consequence, the
auto-adjustment of targetHits might undershoot, resulting in exposing fewer than targetHits to ranking
after post-filtering.
For exact fallback, one can allow the exact search to use multiple threads per search.
Summary
Constraining search for nearest neighbors using query-time constraints is mission-critical for
real-world applications using AI-powered vector representations. By introducing parameters for controlling vector search filtering behavior,
Vespa further fortifies its position in the industry as the leading open-source serving technology for vector search applications.
To try out these parameters in practice, see the practical nearest neighbor search guide and especially the section on controlling filter behavior.
See also Vespa sample applications built using Vespa’s approximate nearest neighbor search:
-
State-of-the-art text ranking: Vector search with AI-powered representations built on NLP Transformer models for candidate retrieval. The application has multi-vector representations for re-ranking, using Vespa’s phased retrieval and ranking serving pipelines. Furthermore, the application shows how embedding models, which maps the text data to vector representation, can be deployed to Vespa for run-time inference during both document and query processing.
-
State-of-the-art image search: AI-powered multi-modal vector representations to retrieve images for a text query.
All these are examples of applications built using AI-powered vector representations, and where real-world deployments need query-time constrained nearest neighbor search.
Vespa is available as a cloud service, see Vespa Cloud - getting started, or self-serve Vespa - getting started.