
A central architectural feature of Vespa.ai is the division of work between the stateless container cluster and the content cluster.
Most computation, such as evaluating machine-learned models, happens in the content cluster. However, it has become increasingly important to efficiently evaluate models in the container cluster as well, to process or transform documents or queries before storage or execution. One prominent example is to generate a vector representation of natural language text for queries and documents for nearest neighbor retrieval.
We have recently implemented accelerated model evaluation using ONNX Runtime in the stateless cluster, which opens up new usage areas for Vespa.
Introduction
At Vespa.ai we differentiate between stateful and stateless machine-learned model evaluation. Stateless model evaluation is what one usually thinks about when serving machine-learned models in production. For instance, one might have a stand-alone model server that is called from somewhere in a serving stack. The result of evaluating a model there only depends upon its input.
In contrast, stateful model serving combines input with stored or persisted data. This poses some additional challenges. One is that models typically need to be evaluated many times per query, once per data point. This has been a focus area of Vespa.ai for quite some time, and we have previously written about how we accelerate stateful model evaluation in Vespa.ai using ONNX Runtime.
However, stateless model evaluation does have its place in Vespa.ai as well. For instance, transforming query input or document content using Transformer models. Or finding a vector representation for an image for image similarity search. Or translating text to another language. The list goes on.
Vespa.ai has actually had stateless model evaluation for some time, but we’ve recently added acceleration of ONNX models using ONNX Runtime. This makes this feature much more powerful and opens up some new use cases for Vespa.ai. In this post, we’ll take a look at some capabilities this enables:
- The automatically generated REST API for model serving.
- Creating lightweight request handlers for serving models with some custom code without the need for content nodes.
- Adding model evaluation to searchers for query processing and enrichment.
- Adding model evaluation to document processors for transforming content before ingestion.
- Batch-processing results from the ranking back-end for additional ranking models.
We’ll start with a quick overview of the difference between where we evaluate machine-learned models in Vespa.ai.
Vespa.ai applications: container and content nodes
Vespa.ai is a distributed application consisting of various types of services on multiple nodes. A Vespa.ai application is fully defined in an application package. This single unit contains everything needed to set up an application, including all configuration, custom components, schemas, and machine-learned models. When the application package is deployed, the admin cluster takes care of configuring all the services across all the system’s nodes, including distributing all models to the nodes that need them.
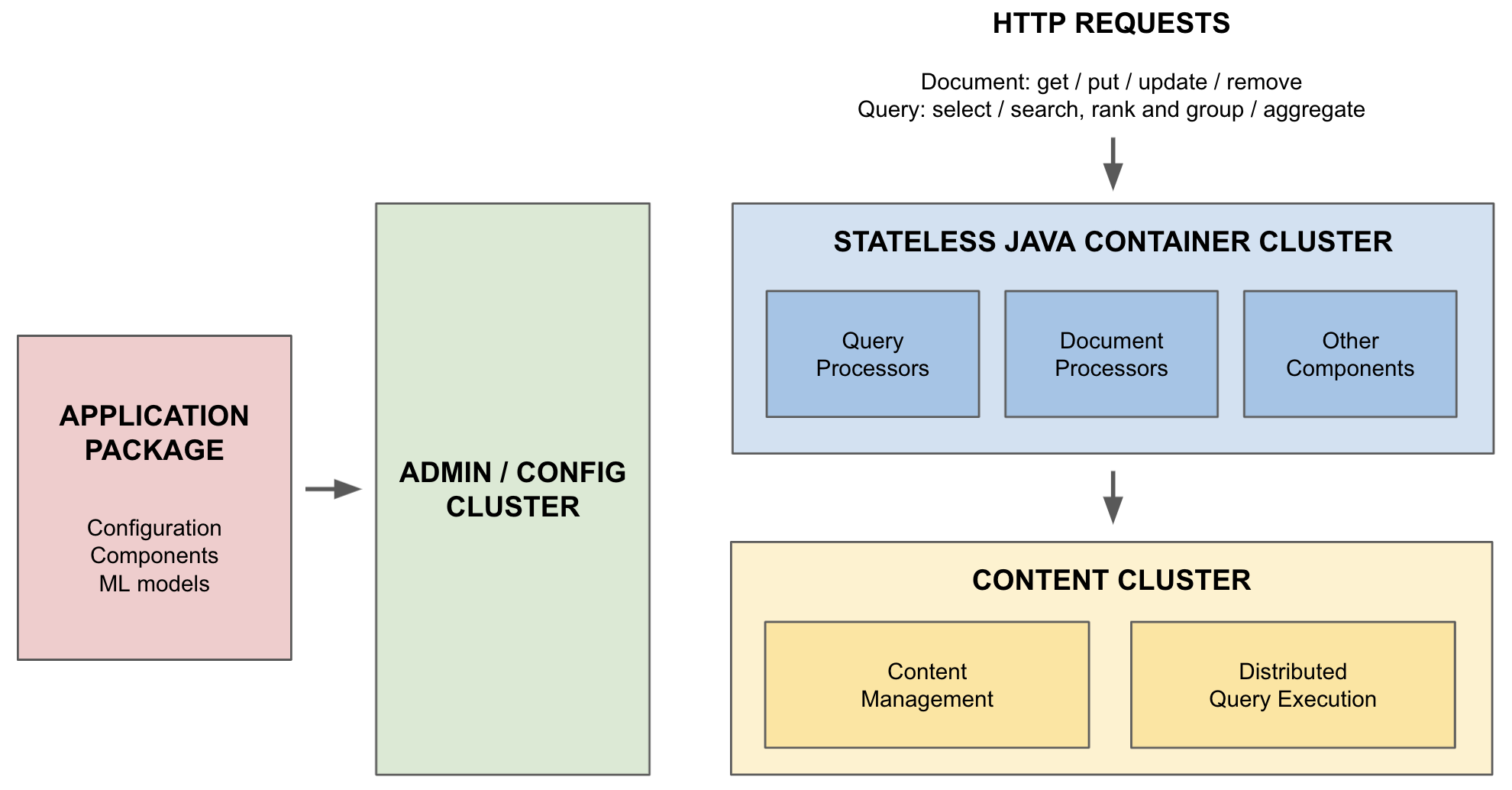
The container nodes process queries or documents before passing them on to the content nodes. So, when a document is fed to Vespa, content can be transformed or added before being stored. Likewise, queries can be transformed or enriched in various ways before being sent for further processing.
The content nodes are responsible for persisting data. They also do most of the required computation when responding to queries. As that is where the data is, this avoids the cost of transferring data across the network. Query data is combined with document data to perform this computation in various ways.
We thus differentiate between stateless and stateful machine-learned model evaluation. Stateless model evaluation happens on the container nodes and is characterized by a single model evaluation per query or document. Stateful model evaluation happens on the content nodes, and the model is typically evaluated a number of times using data from both the query and the document.
The exact configuration of the services on the nodes is specified in services.xml. Here the number of container and content nodes, and their capabilities, are fully configured. Indeed, a Vespa.ai application does not need to be set up with any content nodes, purely running stateless container code, including serving machine-learned models.
This makes it easy to deploy applications. It offers a lot of flexibility in combining many types of models and computations out of the box without any plugins or extensions. In the next section, we’ll see how to set up stateless model evaluation.
Stateless model evaluation
So, by stateless model
evaluation we mean
machine-learned models that are evaluated on Vespa container nodes. This is
enabled by simply adding the model-evaluation tag in services.xml:
...
<container>
...
<model-evaluation/>
...
</container>
...
When this is specified, Vespa scans through the models directory in the
application packages to find any importable machine-learned models. Currently,
supported models are TensorFlow, ONNX, XGBoost, LightGBM or Vespa’s own
stateless
models.
There are two effects of this. The first is that a REST API for model discovery
and evaluation is automatically enabled. The other is that custom
components can have
a special ModelsEvaluator object dependency injected into their constructors.
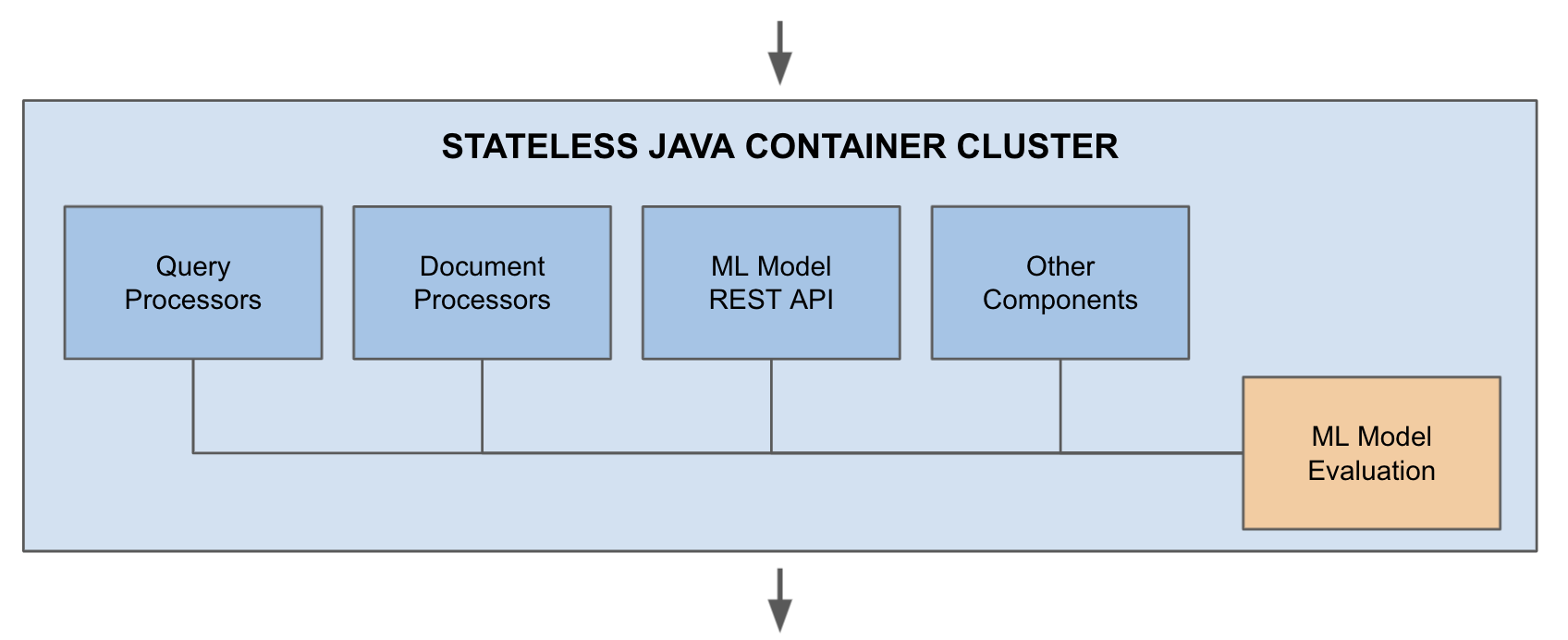
In the following we’ll take a look at some of the usages of these, and use the model-evaluation sample app for demonstratation.
REST API
The automatically added REST API provides an API for model discovery and evaluation. This is great for using Vespa as a standalone model server, or making models available for other parts of the application stack.
To get a list of imported models, call http://host:port/model-evaluation/v1.
For instance:
$ curl -s 'http://localhost:8080/model-evaluation/v1/'
{
"pairwise_ranker": "http://localhost:8080/model-evaluation/v1/pairwise_ranker",
"transformer": "http://localhost:8080/model-evaluation/v1/transformer"
}
This application has two models, the transformer model and the
pairwise_ranker model. We can inspect a model to see expected inputs and
outputs:
$ curl -s 'http://localhost:8080/model-evaluation/v1/transformer/output'
{
"arguments": [
{
"name": "input",
"type": "tensor(d0[],d1[])"
},
{
"name": "onnxModel(transformer).output",
"type": "tensor<float>(d0[],d1[],d2[16])"
}
],
"eval": "http://localhost:8080/model-evaluation/v1/transformer/output/eval",
"function": "output",
"info": "http://localhost:8080/model-evaluation/v1/transformer/output",
"model": "transformer"
}
All model inputs and output are Vespa tensors. See the tensor user guide for more information.
This model has one input, with tensor type tensor(d0[],d1[]). This tensor has
two dimensions: d0 is typically a batch dimension, and d1 represents for,
this model, a sequence of tokens. The output, of type tensor<float>(d0[],d1[],d2[16])
adds a dimension d2 which represents the embedding dimension. So the output is
an embedding representation for each token of the input.
By calling /model-evaluation/v1/transformer/eval and passing an URL encoded input
parameter, Vespa evaluates the model and returns the result as a JSON encoded
tensor.
Please refer to the sample application for a runnable example.
Request handlers
The REST API takes exactly the same input as the models it serves. In some cases one might want to pre-process the input before providing it to the model. A common example is to tokenize natural language text before passing the token sequence to a language model such as BERT.
Vespa provides request handlers which lets applications implement arbitrary HTTP APIs. With custom request handlers, arbitrary code can be run both before and after model evaluation.
When the model-evaluation tag has been supplied, Vespa makes a special
ModelsEvaluator object available which can be injected into a component
(such as a request handler):
public class MyHandler extends ThreadedHttpRequestHandler {
private final ModelsEvaluator modelsEvaluator;
public MyHandler(ModelsEvaluator modelsEvaluator, Context context) {
super(context);
this.modelsEvaluator = modelsEvaluator;
}
@Override
public HttpResponse handle(HttpRequest request) {
// Get the input
String inputString = request.getProperty("input");
// Convert to a Vespa tensor
TensorType expectedType = TensorType.fromSpec("tensor<int8>(x[])");
Tensor input = Tensor.from(expectedType, inputString);
// Perform any pre-processing to the tensor
// ...
// Evaluate the model
FunctionEvaluator evaluator = modelsEvaluator.evaluatorOf("transformer");
Tensor result = evaluator.bind("input", input).evaluate();
// Perform any post-processing to the tensor
// ...
}
A full example can be seen in the MyHandler class in the sample application and it’s unit test.
As mentioned, arbitrary code can be run here. Pragmatically, it is often more convenient to put the processing pipeline in the model itself. While not always possible, this helps protect against divergence between the data processing pipeline in training and in production.
Document processors
The REST API and request handler can work with a purely stateless application, such as a model server. However, it is much more common for Vespa.ai applications to have content. As such, it is fairly common to process incoming documents before storing them. Vespa provides a chain of document processors for this.
Applications can implement custom document processors, and add them to the processing chain. In the context of model evaluation, a typical task is to use a machine-learned model to create a vector representation for a natural language text. The text is first tokenized, then run though a language model such as BERT to generate a vector representation which is then stored. Such a vector representation can be for instance used in nearest neighbor search. Other examples are sentiment analysis, creating representations of images, object detection, translating text, and so on.
The ModelsEvaluator can be injected into your component as already seen:
public class MyDocumentProcessor extends DocumentProcessor {
private final ModelsEvaluator modelsEvaluator;
public MyDocumentProcessor(ModelsEvaluator modelsEvaluator) {
this.modelsEvaluator = modelsEvaluator;
}
@Override
public Progress process(Processing processing) {
for (DocumentOperation op : processing.getDocumentOperations()) {
if (op instanceof DocumentPut) {
DocumentPut put = (DocumentPut) op;
Document document = put.getDocument();
// Get tokens
Tensor tokens = (Tensor) document.getFieldValue("tokens").getWrappedValue();
// Perform any pre-processing to the tensor
// ...
// Evaluate the model
FunctionEvaluator evaluator = modelsEvaluator.evaluatorOf("transformer");
Tensor result = evaluator.bind("input", input).evaluate();
// Reshape and extract the embedding vector (not shown)
Tensor embedding = ...
// Set embedding in document
document.setFieldValue("embedding", new TensorFieldValue(embedding));
}
}
}
}
Notice the code looks a lot like the previous example for the request handler.
The document processor receives a pre-constructed ModelsEvaluator from Vespa
which contains the transformer model. This code receives a tensor contained
in the tokens field, runs that through the transformer model, and puts the
resulting embedding into a new field. This is then stored along with the
document.
Again, a full example can be seen in the MyDocumentProcessor class in the sample application and it’s unit test.
Searchers: query processing
Similar to document processing, queries are processed along a chain of searchers. Vespa provides a default chain of searchers for various tasks, and applications can provide additional custom searchers as well. In the context of model evaluation, the use cases are similar to document processing: a typical task for text search is to generate vector representations for nearest neighbor search.
Again, the ModelsEvaluator can be injected into your component:
public class MySearcher extends Searcher {
private final ModelsEvaluator modelsEvaluator;
public MySearcher(ModelsEvaluator modelsEvaluator) {
this.modelsEvaluator = modelsEvaluator;
}
@Override
public Result search(Query query, Execution execution) {
// Get the query input
String inputString = query.properties().getString("input");
// Convert to a Vespa tensor
TensorType expectedType = TensorType.fromSpec("tensor<int8>(x[])");
Tensor input = Tensor.from(expectedType, inputString);
// Perform any pre-processing to the tensor
// ...
// Evaluate model
FunctionEvaluator evaluator = modelsEvaluator.evaluatorOf("transformer");
Tensor output = evaluator.bind("input", input).evaluate();
// Reshape and extract the embedding vector (not shown)
Tensor embedding = ...
// Add this tensor to query
query.getRanking().getFeatures().put("query(embedding)", embedding);
// Continue processing
return execution.search(query);
}
}
As before, a full example can be seen in the MySearcher class in the sample application and it’s unit test.
Searchers: result post-processing
Searchers don’t just process queries before being sent to the back-end: they are just as useful in post-processing the results from the back-end. A typical example is to de-duplicate similar results in a search application. Another is to apply business rules to reorder the results, especially if coming from various back-ends. In the context of machine learning, one example is is to de-tokenize tokens back to a natural language text.
Post-processing is similar to the example above, but the search is executed first, and tensor fields from the documents are extracted and used as input to the models. In the sample application we have a model that compares all results with each other to perform another phase of ranking. See the MyPostProcessing searcher for details.
Conclusion
In Vespa.ai, most of the computation required for executing queries has traditionally been run in the content cluster. This makes sense as it avoids transmitting data across the network to external model servers; this quickly becomes a scalability bottleneck.
With the introduction of accelerated machine-learned model evaluation in the container cluster, we further increase the capabilities of Vespa as a fully-featured platform for low-latency computations over large, evolving data.
In summary, Vespa.ai offers ease of deployment, flexibility in combining many types of models and computations out of the box without any plugins or extensions, efficient evaluation and a less complex system to maintain. This makes Vespa.ai an attractive platform.
In a later post, we will follow up with performance measurements and some guidelines on when to move model evaluation out of the content node and to the container.