
Holiday shopping season is upon us and it’s time for a blog post on E-commerce search and recommendation using Vespa.ai. Vespa.ai is used as the search and recommendation backend at multiple Yahoo e-commerce sites in Asia, like tw.buy.yahoo.com.
This blog post discusses some of the challenges in e-commerce search and recommendation, and shows how they can be solved using the features of Vespa.ai.

Photo by Jonas Leupe on Unsplash
Text matching and ranking in e-commerce search
E-commerce search have text ranking requirements where traditional text ranking features like BM25 or TF-IDF might produce poor results. For an introduction to some of the issues with TF-IDF/BM25 see the influence of TF-IDF algorithms in e-commerce search. One example from the blog post is a search for ipad 2 which with traditional TF-IDF ranking will rank ‘black mini ipad cover, compatible with ipad 2’ higher than ‘Ipad 2’ as the former product description has several occurrences of the query terms Ipad and 2.
Vespa allows developers and relevancy engineers to fine tune the text ranking features to meet the domain specific ranking challenges. For example developers can control if multiple occurrences of a query term in the matched text should impact the relevance score. See text ranking occurrence tables and Vespa text ranking types for in-depth details. Also the Vespa text ranking features takes text proximity into account in the relevancy calculation, i.e how close the query terms appear in the matched text. BM25/TF-IDF on the other hand does not take query term proximity into account at all. Vespa also implements BM25 but it’s up to the relevancy engineer to chose which of the rich set of built-in text ranking features in Vespa that is used.
Vespa uses OpenNLP for linguistic processing like tokenization and stemming with support for multiple languages (as supported by OpenNLP).
Custom ranking business logic in e-commerce search
Your manager might tell you that these items of the product catalog should be prominent in the search results. How to tackle this with your existing search solution? Maybe by adding some synthetic query terms to the original user query, maybe by using separate indexes with federated search or even with a key value store which rarely is in synch with the product catalog search index?
With Vespa it’s easy to promote content as Vespa’s ranking framework is just math and allows the developer to formulate the relevancy scoring function explicitly without having to rewrite the query formulation. Vespa controls ranking through ranking expressions configured in rank profiles which enables full control through the expressive Vespa ranking expression language. The rank profile to use is chosen at query time so developers can design multiple ranking profiles to rank documents differently based on query intent classification. See later section on query classification for more details how query classification can be done with Vespa.
A sample ranking profile which implements a tiered relevance scoring function where sponsored or promoted items are always ranked above non-sponsored documents is shown below. The ranking profile is applied to all documents which matches the query formulation and the relevance score of the hit is the assigned the value of the first-phase expression. Vespa also supports multi-phase ranking.

Sample hand crafted ranking profile defined in the Vespa application package.
The above example is hand crafted but for optimal relevance we do recommend looking at learning to rank (LTR) methods. See learning to Rank using TensorFlow Ranking and learning to Rank using XGBoost. The trained MLR models can be used in combination with the specific business ranking logic. In the example above we could replace the default-ranking function with the trained MLR model, hence combining business logic with MLR models.
Facets and grouping in e-commerce search
Guiding the user through the product catalog by guided navigation or faceted search is a feature which users expects from an e-commerce search solution today and with Vespa, facets and guided navigation is easily implemented by the powerful Vespa Grouping Language.
Sample screenshot from Vespa e-commerce sample application UI demonstrating search facets using Vespa Grouping Language.
The Vespa grouping language supports deep nested grouping and aggregation operations over the matched content. The language also allows pagination within the group(s). For example if grouping hits by category and displaying top 3 ranking hits per category the language allows paginating to render more hits from a specified category group.
The vocabulary mismatch problem in e-commerce search
Studies (e.g. this study from FlipKart) finds that there is a significant fraction of queries in e-commerce search which suffer from vocabulary mismatch between the user query formulation and the relevant product descriptions in the product catalog. For example, the query “ladies pregnancy dress” would not match a product with description “women maternity gown” due to vocabulary mismatch between the query and the product description. Traditional Information Retrieval (IR) methods like TF-IDF/BM25 would fail retrieving the relevant product right off the bat.
Most techniques currently used to try to tackle the vocabulary mismatch problem are built around query expansion. With the recent advances in NLP using transfer learning with large pre-trained language models, we believe that future solutions will be built around multilingual semantic retrieval using text embeddings from pre-trained deep neural network language models. Vespa has recently announced a sample application on semantic retrieval (removed) which addresses the vocabulary mismatch problem as the retrieval is not based on query terms alone, but instead based on the dense text tensor embedding representation of the query and the document. The mentioned sample app reproduces the accuracy of the retrieval model described in the Google blog post about Semantic Retrieval.
Using our query and product title example from the section above, which suffers from the vocabulary mismatch, and instead move away from the textual representation to using the respective dense tensor embedding representation, we find that the semantic similarity between them is high (0.93). The high semantic similarity means that the relevant product would be retrieved when using semantic retrieval. The semantic similarity is in this case defined as the cosine similarity between the dense tensor embedding representations of the query and the product description. Vespa has strong support for expressing and storing tensor fields which one can perform tensor operations (e.g cosine similarity) over for ranking, this functionality is demonstrated in the mentioned sample application.
Below is a simple matrix comparing the semantic similarity of three pairs of (query, product description). The tensor embeddings of the textual representation is obtained with the Universal Sentence Encoder from Google.
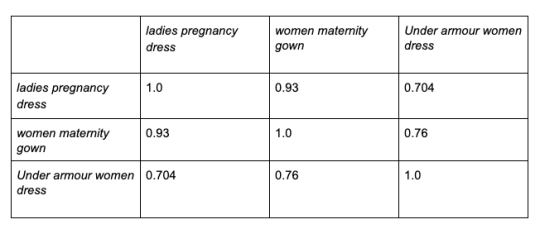
Semantic similarity matrix of different queries and product descriptions.
The Universal Sentence Encoder Model from Google is multilingual as it was trained on text from multiple languages. Using these text embeddings enables multilingual retrieval so searches written in Chinese can retrieve relevant products by descriptions written in multiple languages. This is another nice property of semantic retrieval models which is particularly useful in e-commerce search applications with global reach.
Query classification and query rewriting in e-commerce search
Vespa supports deploying stateless machine learned (ML) models which comes handy when doing query classification. Machine learned models which classify the query is commonly used in e-commerce search solutions and the recent advances in natural language processing (NLP) using pre-trained deep neural language models have improved the accuracy of text classification models significantly. See e.g text classification using BERT for an illustrated guide to text classification using BERT. Vespa supports deploying ML models built with TensorFlow, XGBoost and PyTorch through the Open Neural Network Exchange (ONNX) format. ML models trained with mentioned tools can successfully be used for various query classification tasks with high accuracy.
In e-commerce search, classifying the intent of the query or query session can help ranking the results by using an intent specific ranking profile which is tailored to the specific query intent. The intent classification can also determine how the result page is displayed and organised.
Consider a category browse intent query like ‘shoes for men’. A query intent which might benefit from a query rewrite which limits the result set to contain only items which matched the unambiguous category id instead of just searching the product description or category fields for ‘shoes for men’ . Also ranking could change based on the query classification by using a ranking profile which gives higher weight to signals like popularity or price than text ranking features.
Vespa also features a powerful query rewriting language which supports rule based query rewrites, synonym expansion and query phrasing.
Product recommendation in e-commerce search
Vespa is commonly used for recommendation use cases and e-commerce is no exception.
Vespa is able to evaluate complex Machine Learned (ML) models over many data points (documents, products) in user time which allows the ML model to use real time signals derived from the current user’s online shopping session (e.g products browsed, queries performed, time of day) as model features. An offline batch oriented inference architecture would not be able to use these important real time signals. By batch oriented inference architecture we mean pre-computing the inference offline for a set of users or products and where the model inference results is stored in a key-value store for online retrieval.
Update 2021-05-20: Blog recommendation tutorials are replaced by the News search and recommendation tutorial: In our blog recommendation tutorial we demonstrate how to apply a collaborative filtering model for content recommendation and in part 2 of the blog recommendation tutorial we show how to use a neural network trained with TensorFlow to serve recommendations in user time. Similar recommendation approaches are used with success in e-commerce.
Keeping your e-commerce index up to date with real time updates
Vespa is designed for horizontal scaling with high sustainable write and read throughput with low predictable latency. Updating the product catalog in real time is of critical importance for e-commerce applications as the real time information is used in retrieval filters and also as ranking signals. The product description or product title rarely changes but meta information like inventory status, price and popularity are real time signals which will improve relevance when used in ranking. Also having the inventory status reflected in the search index also avoids retrieving content which is out of stock.
Vespa has true native support for partial updates where there is no need to re-index the entire document but only a subset of the document (i.e fields in the document). Real time partial updates can be done at scale against attribute fields which are stored and updated in memory. Attribute fields in Vespa can be updated at rates up to about 40-50K updates/s per content node.
Campaigns in e-commerce search
Using Vespa’s support for predicate fields it’s easy to control when content is surfaced in search results and not. The predicate field type allows the content (e.g a document) to express if it should match the query instead of the other way around. For e-commerce search and recommendation we can use predicate expressions to control how product campaigns are surfaced in search results. Some examples of what predicate fields can be used for:
- Only match and retrieve the document if time of day is in the range 8–16 or range 19–20 and the user is a member. This could be used for promoting content for certain users, controlled by the predicate expression stored in the document. The time of day and member status is passed with the query.
- Represent recurring campaigns with multiple time ranges.
Above examples are by no means exhaustive as predicates can be used for multiple campaign related use cases where the filtering logic is expressed in the content.
Scaling & performance for high availability in e-commerce search
Are you worried that your current search installation will break by the traffic surge associated with the holiday shopping season? Are your cloud VMs running high on disk busy metrics already? What about those long GC pauses in the JVM old generation causing your 95percentile latency go through the roof? Needless to say but any downtime due to a slow search backend causing a denial of service situation in the middle of the holiday shopping season will have catastrophic impact on revenue and customer experience.

Photo by Jon Tyson on Unsplash
The heart of the Vespa serving stack is written in C++ and don’t suffer from issues related to long JVM GC pauses. The indexing and search component in Vespa is significantly different from the Lucene based engines like SOLR/Elasticsearch which are IO intensive due to the many Lucene segments within an index shard. A query in a Lucene based engine will need to perform lookups in dictionaries and posting lists across all segments across all shards. Optimising the search access pattern by merging the Lucene segments will further increase the IO load during the merge operations.
With Vespa you don’t need to define the number of shards for your index prior to indexing a single document as Vespa allows adaptive scaling of the content cluster(s) and there is no shard concept in Vespa. Content nodes can be added and removed as you wish and Vespa will re-balance the data in the background without having to re-feed the content from the source of truth.
In ElasticSearch, changing the number of shards to scale with changes in data volume requires an operator to perform a multi-step procedure that sets the index into read-only mode and splits it into an entirely new index. Vespa is designed to allow cluster resizing while being fully available for reads and writes. Vespa splits, joins and moves parts of the data space to ensure an even distribution with no intervention needed
At the scale we operate Vespa at Verizon Media, requiring more than 2X footprint during content volume expansion or reduction would be prohibitively expensive. Vespa was designed to allow content cluster resizing while serving traffic without noticeable serving impact. Adding content nodes or removing content nodes is handled by adjusting the node count in the application package and re-deploying the application package.
Also the shard concept in ElasticSearch and SOLR impacts search latency incurred by cpu processing in the matching and ranking loops as the concurrency model in ElasticSearch/SOLR is one thread per search per shard. Vespa on the other hand allows a single search to use multiple threads per node and the number of threads can be controlled at query time by a rank-profile setting: num-threads-per-search. Partitioning the matching and ranking by dividing the document volume between searcher threads reduces the overall latency at the cost of more cpu threads, but makes better use of multi-core cpu architectures. If your search servers cpu usage is low and search latency is still high you now know the reason.
In a recent published benchmark which compared the performance of Vespa versus ElasticSearch for dense vector ranking Vespa was 5x faster than ElasticSearch. The benchmark used 2 shards for ElasticSearch and 2 threads per search in Vespa.
The holiday season online query traffic can be very spiky, a query traffic pattern which can be difficult to predict and plan for. For instance price comparison sites might direct more user traffic to your site unexpectedly at times you did not plan for. Vespa supports graceful quality of search degradation which comes handy for those cases where traffic spikes reaches levels not anticipated in the capacity planning. These soft degradation features allow the search service to operate within acceptable latency levels but with less accuracy and coverage. These soft degradation mechanisms helps avoiding a denial of service situation where all searches are becoming slow due to overload caused by unexpected traffic spikes. See details in the Vespa graceful degradation documentation.
Summary
In this post we have explored some challenges in e-commerce Search and Recommendation and highlighted some features of Vespa which can be used to tackle e-commerce search and recommendation use cases. If you want to try Vespa for your e-commerce application you can go check out our e-commerce sample application found here . The sample application can be scaled to full production size using our hosted Vespa Cloud Service at https://cloud.vespa.ai/. Happy Holiday Shopping Season!