


Photo by vnwayne fan on Unsplash
We are thrilled to announce significant updates to Vespa’s support for inference with text embedding models that maps texts into vector representations: General support for Huggingface models including multi-lingual embedding, embedding inference on GPUs, and new recommended models available on the Vespa Cloud model hub.
Vespa’s best-in-class vector and multi-vector search support and inferences with embedding models allow developers to build feature-rich semantic search applications without managing separate systems for embedding inference and vector search over embedding representations.
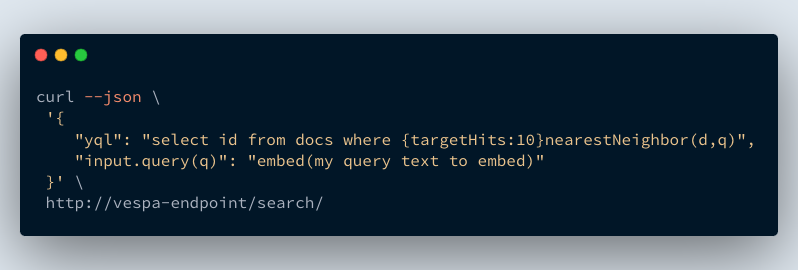 Vespa query request using embed
functionality to produce the vector embedding inside Vespa.
Vespa query request using embed
functionality to produce the vector embedding inside Vespa.
About text embedding models
Text embedding models have revolutionized natural language processing (NLP) and information retrieval tasks by capturing the semantic meaning of unstructured text data. Unlike traditional representations that treat words as discrete symbols, embedding models maps text into continuous vector spaces.
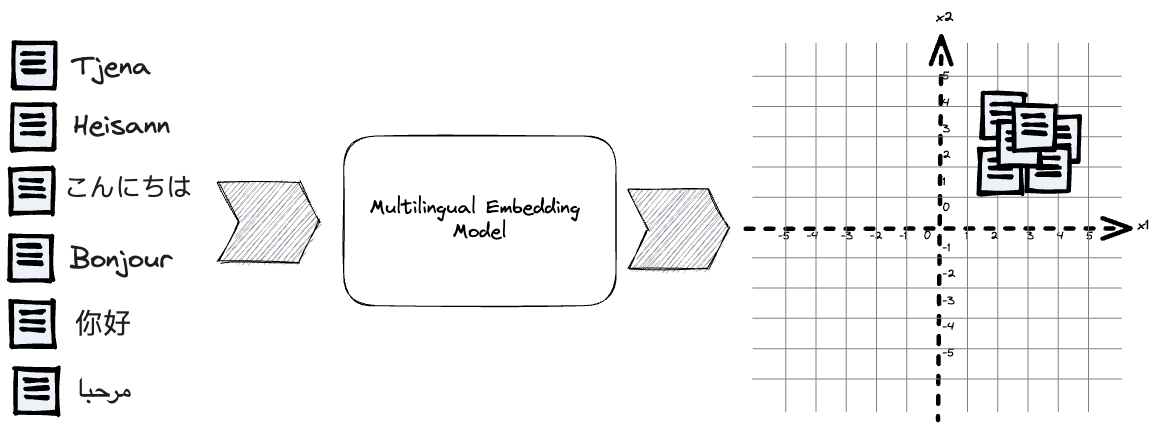
Embedding models trained on multilingual datasets can represent concepts across different languages enabling information retrieval across diverse linguistic contexts.
Embedder Models from Huggingface
Vespa now comes with generic support for embedding models hosted on Huggingface.
With the new Huggingface Embedder functionality, developers can export embedding models from Huggingface and import them in ONNX format in Vespa for accelerated inference close to where the data is created:
<container id="default" version="1.0">
<component id="my-embedder-id" type="hugging-face-embedder">
<transformer-model model-id="cloud-model-id"
path="my-models/model.onnx"/>
<tokenizer-model model-id="cloud-model-id"
path="my-models/tokenizer.json"/>
</component>
...
</container>
The Huggingface Embedder also supports multilingual embedding models that handle 100s of languages. Multilingual embedding representations open new possibilities for cross-lingual applications using Vespa linguistic processing and multilingual vector representations to implement hybrid search. The new Huggingface Embedder also supports multi-vector representations, simplifying deploying semantic search applications at scale without maintaining complex fan-out relationships due to model input context length constraints. Read more about the Huggingface embedder in the documentation.
GPU Acceleration of Embedding Models
Vespa now supports GPU acceleration of embedding model inferences. By harnessing the power of GPUs, Vespa embedders can efficiently process large amounts of text data, resulting in faster response times, improved scalability, and lower cost. GPU support in Vespa also unlocks using larger and more powerful embedding models while maintaining low serving latency and cost-effectiveness.
GPU acceleration is automatically enabled in Vespa Cloud for instances where GPU(s) is available. Configure your stateless Vespa container cluster with a GPU resource in services.xml. For open-source Vespa, specify the GPU device using the embedder ONNX configuration.
Vespa Model Hub Updates
To make it easier to create embedding applications, we have added new state-of-the-art text embedding models on the Vespa Model Hub for Vespa Cloud users. The Vespa Model Hub is a centralized repository of selected models, making it easier for developers to discover and use powerful open-source embedding models.
This expansion of the model hub provides developers with a broader range of embedding options. It empowers them to make tradeoffs related to embedding quality, inference latency, and embedding dimensionality-related resource footprint.
We expand the hub with the following open-source text embedding models:
| Embedding Model | Dimensionality | Metric | Language | Vespa Hub Model Id |
|---|---|---|---|---|
| e5-small-v2 | 384 | angular | English | e5-small-v2 |
| e5-base-v2 | 768 | angular | English | e5-base-v2 |
| e5-large-v2 | 1024 | angular | English | e5-large-v2 |
| multilingual-e5-base | 768 | angular | Multilingual | multilingual-e5-base |
These embedding models perform strongly on various tasks, as demonstrated on the MTEB: Massive Text Embedding Benchmark leaderboard. The MTEB includes 56 datasets across 8 tasks, such as semantic search, clustering, classification, and re-ranking.
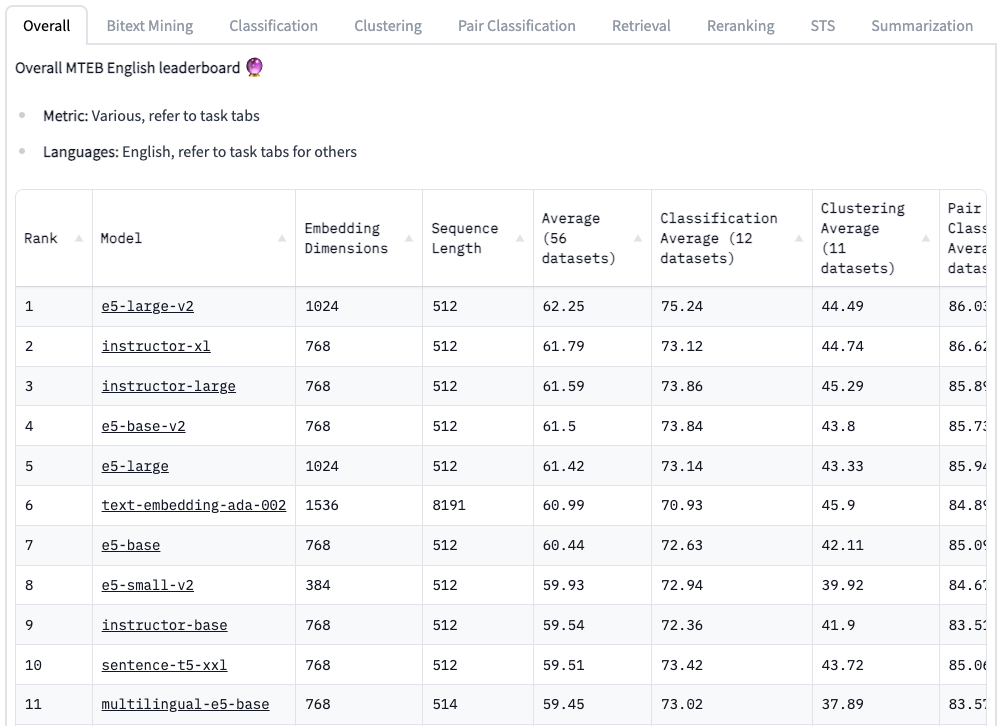 MTEB Leaderboard, notice the strong performance of the E5-v2 models
MTEB Leaderboard, notice the strong performance of the E5-v2 models
Developers using Vespa Cloud can add these embedding models to their application by referencing the Vespa Cloud Model hub identifier:
<component id="e5" type="hugging-face-embedder">
<transformer-model model-id="e5-small-v2"/>
</component>
With three lines of configuration added to the Vespa app, Vespa cloud developers can use the embed funcionality for
embedding queries and embedding document fields.
Producing the embeddings closer to the Vespa storage and indexes avoids network transfer-related latency and egress costs, which can be substantial for high-dimensional vector representations. In addition, with Vespa Cloud’s auto-scaling feature, developers do not need to worry about scaling with changes in inference traffic volume.
Vespa Cloud also allows bringing your own models using the HuggingFace Embedder with model files submitted in the application package. In Vespa Cloud, inference with embedding models is automatically accelerated with GPU if the application uses Vespa Cloud GPU instances. Read more on the Vespa Cloud model hub.
Summary
The improved Vespa embedding management options offer a significant leap in capabilities for anybody working with embeddings in online applications, enabling developers to leverage state-of-the-art models, accelerate inference with GPUs, and access a broader range of embedding options through the Vespa model hub. All this functionality is available in Vespa version 8.179.37 and later.
Got questions? Join the Vespa community in Vespa Slack.