


Minimizing LLM Distraction with Cross-Encoder Re-Ranking

Photo by Will van Wingerden on Unsplash
This blog post announces Vespa support for the declarative expression of global re-ranking, further streamlining the process of deploying multi-phase ranking pipelines at massive scale without writing code or managing complex inference infrastructure.
Introduction
Connecting Large Language Models (LLMs) with text retrieved using a search engine or a vector database is becoming popular. However, retrieving irrelevant text can cause LLMs to generate incorrect responses, as demonstrated in Large Language Models Can Be Easily Distracted by Irrelevant Context. In other words, the quality of the retrieval and ranking stages sets an upper bound on the effectiveness of the overall retrieval-augmented LLM pipeline.
Transformer models such as BERT have shown an impressive enhancement over previous text ranking methods, with multi-vector and cross-encoder models outperforming single-vector representation models. Multi-vector and cross-encoder models are more complex but shine in a zero-shot setting without in-domain fine-tuning. Cross-encoder models encode the query and document as input, allowing for deep token cross-interactions and a better ranking, as demonstrated on the BEIR benchmark. The downside of cross-encoders for text ranking is their computational complexity, which is quadratic with the query and document lengths. The computational complexity makes them only suitable for re-ranking phases, where more efficient retrieval and ranking models have significantly pruned the number of documents in advance.
Phased ranking
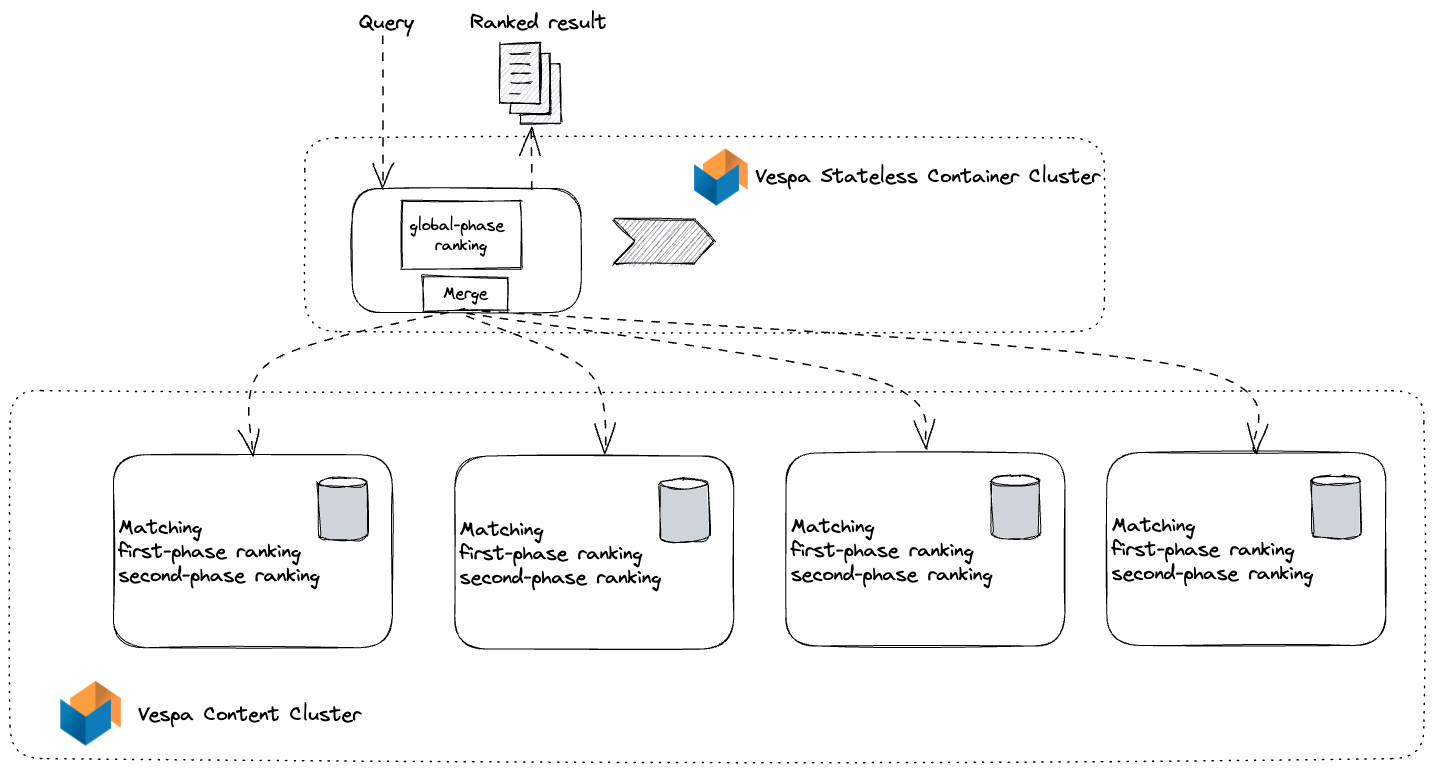
Vespa has best-in-class support for expressing multi-phased retrieval and ranking. Using multi-stage retrieval and ranking pipelines is an industry best practice for efficiently matching and ranking content. The basic concept behind this approach is to use a ranking model at each stage of the pipeline to filter out less relevant candidates, thereby reducing the number of documents ranked at each subsequent stage. By following this method, the number of documents gradually decreases until only the top-ranking results remain, which can be returned or used as input for an LLM prompt. Vespa supports distributed search, where Vespa distributes data elastically across multiple stateful content nodes. Each stateful Vespa content node performs local-optimal retrieval and ranking over a subset of all the data.
With the new declarative global re-ranking support, Vespa can run inference and re-rank results after finding the top-ranking documents from all nodes after executing the local per-node ranking phases.
Introducing global ranking phase
Vespa configures rank expressions in rank-profiles in the document schema(s), allowing the user to express how retrieved documents are ranked.
rank-profile phased {
first-phase {
expression: log(bm25(title)) + cos(distance(field,embedding))
}
second-phase {
expression { firstPhase + lightgbm("f834_v2.json")}
rerank-count: 1000
}
}
In the above declarative rank-profile example, the developer has specified a hybrid combination of dense vector similarity and exact keyword scoring (bm25) as the first-phase function. The per node top 1K ranking documents from the first phase are re-ranked using a machine-learned model, which uses Vespa’s support for scoring with LightGBM models.
Each node running the query would execute the first and second ranking phases. Finally, the per-node ranking result is merged based on the second-phase score into globally ordered top-ranking hits. With the declarative global-phase introduced, users can add a new ranking phase:
rank-profile global-phased {
first-phase {
expression: log(bm25(title)) + cos(distance(field,embedding))
}
second-phase {
expression { firstPhase + lightgbm("f834_v2.json")}
rerank-count: 1000
}
global-phase {
expression { sum(onnx(transformer).score) }
rerank-count: 100
}
}
With global-phase support, developers can express a new phase on top of the merged and globally ordered results from the previous distributed ranking phases. The stateless containers evaluate the global-phase expression. The stateless containers also scatter and gather hits from the stateful content nodes, and the global ranking stage happens after merging the results.
The above global phase expression re-ranks the top-100 results using a Transformer based cross-encoder mode. Vespa supports inference with ONNX models, both close to the data on content nodes and in the Vespa stateless containers. Vespa does deploy-time verification of the global-phase expression and derives the required inputs to the model. The document-side feature inputs are sent from the stateful content nodes to the stateless container nodes, along with the hit data. The Vespa internal RPC protocol between the stateless and stateful clusters uses a binary format and avoids network serialization overheads.
Accelerated global phase re-ranking using GPU
We just announced GPU-accelerated ML inference in Vespa Cloud, and global-phase ranking expressions can use GPU acceleration for inference with ONNX models if the instance runs on a CUDA-compatible GPU. Since the global phase is performed in the stateless container service, scaling the number of instances is much faster than scaling content nodes, which requires data movement.
With the Vespa Cloud’s autoscaling of GPU-powered stateless container instances, Vespa users can benefit from reduced serving-related costs and increased performance. Enable GPU acceleration by specifying the GPU device number to run the model on.
rank-profile global-phased {
onnx-model transformer {
...
gpu-device: 0
}
}
See documentation for details.
Summary
With the new declarative stateless ranking phase support in Vespa, search developers can quickly deploy and use state-of-the-art cross-encoders for re-ranking. As demonstrated on the BEIR benchmark, cross-encoders are generally more robust and achieve far better zero-shot ranking than single vector models using cosine similarity.
Global phase re-ranking is available from Vespa 8.164. See the MS Marco Passage Ranking sample application and documentation to get started with global-phase ranking and reduce LLM distraction. Got questions about this feature or Vespa in general? Join our community Slack channel to learn more. **UPDATE 2025-01-22: Link to MS Marco sample app instead, the transformers app is discontinued: **