


Today, we announce the general availability of search.vespa.ai - a new search experience for all (almost) Vespa-related content - powered by Vespa, LangChain, and OpenAI’s chatGPT model. This post overviews our motivation for building it, its features, limitations, and how we made it:
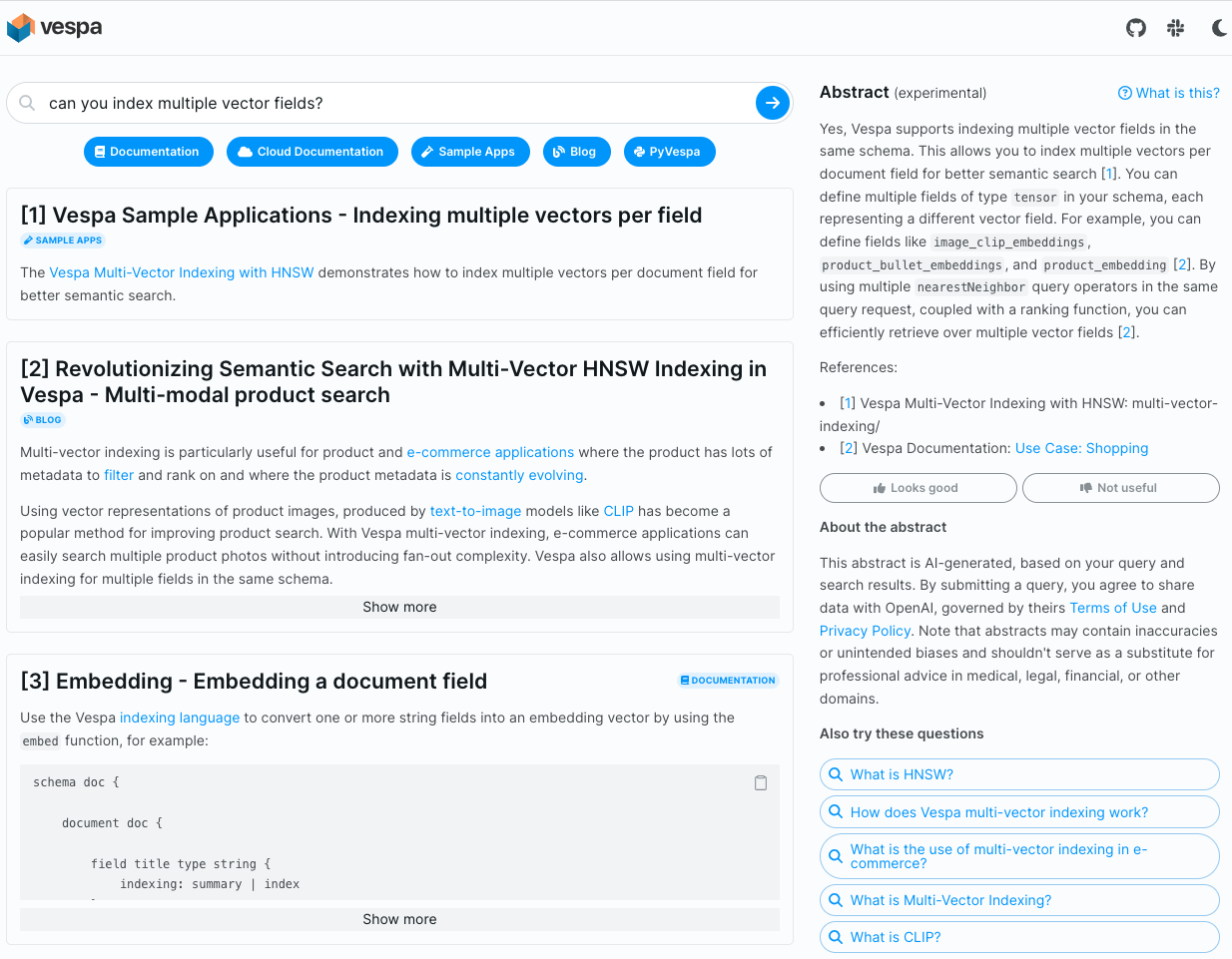
Over the last year, we have seen a dramatic increase in interest in Vespa (From 2M pulls to 11M vespaengine/vespa pulls within just a few months), resulting in many questions on our Slack channel, like “Can Vespa use GPU?” or “Can you expire documents from Vespa?”.
Our existing search interface could only present a ranked list of documents for questions like that, showing a snippet of a matching article on the search result page (SERP). The user then had to click through to the article and scan for the fragment snippets relevant to the question. This experience is unwieldy if looking for the reference documentation of a specific Vespa configuration setting like num-threads-per-search buried in large reference documentation pages.
We wanted to improve the search experience by displaying a better-formatted response, avoiding clicking through, and linking directly to the content fragment. In addition, we wanted to learn more about using a generative large language model to answer questions, using the top-k retrieved fragments in a so-called retrieval augmented generation (RAG) pipeline.
This post goes through how we built search.vespa.ai - highlights:
- Creating a search for chunks of information - the bit of info the user is looking for. The chunks are called paragraphs or fragments in this article
- Rendering fragments in the result page, using the original layout, including formatting and links.
- Using multiple ranking strategies to match user queries to fragments: Exact matching, text matching, semantic matching, and multivector semantic query-to-query matching.
- Search suggestions and hot links.
The Vespa application powering search.vespa.ai is running in Vespa Cloud. All the functional components of search.vespa.ai are Open Source and are found in repositories like vespa-search, documentation, and vespa-documentation-search - it is a great starting point for other applications using features highlighted above!
Getting the Vespa content indexed
The Vespa-related content is spread across multiple git repositories using different markup languages like HTML, Markdown, sample apps, and Jupyter Notebooks. Jekyll generators make this easy; see vespa_index_generator.rb for an example.
First, we needed to convert all sources into a standard format so that the search result page could display a richer formatted experience instead of a text blob of dynamic summary snippets with highlighted keywords.
Since we wanted to show full, feature-rich snippets, we first converted all the different source formats to Markdown. Then, we use the markdown structure to split longer documents into smaller retrieval units or fragments where each retrieval unit is directly linkable, using URL anchoring (#). This process was the least exciting thing about the project, with many iterations, for example, splitting larger reference tables into smaller retrievable units. We also adapted reference documentation to make the fragments linkable - see hotlinks. The retrievable units are indexed in a paragraph schema:
schema paragraph {
document paragraph {
field path type string {}
field doc_id type string {}
field title type string {}
field content type string {}
field questions type array<string> {}
field content_tokens type int {}
field namespace type string {}
}
field embedding type tensor<float>(x[384]) {
indexing: "passage: " . (input title || "") . " " . (input content || "") | embed ..
}
field question_embedding type tensor<float>(q{}, x[384]) {
indexing {
input questions |
for_each { "query: " . _ } | embed | ..
}
}
}
There are a handful of fields in the input (paragraph document type) and two synthetic fields that are produced by Vespa,
using Vespa’s embedding functionality.
We are mapping different input string fields to two different
Vespa tensor representations.
The content and title fields are concatenated and embedded
to obtain a vector representation of 384 dimensions (using e5-v2-small).
The question_embedding is a multi-vector tensor;
in this case, the embedder embeds each input question.
The output is a multi-vector representation (A mapped-dense tensor).
Since the document volume is low, an exact vector search is all we need,
and we do not enable HNSW indexing of these two embedding fields.
LLM-generated synthetic questions
The questions per fragment are generated by an LLM (chatGPT). We do this by asking it to generate questions the fragment could answer. The LLM-powered synthetic question generation is similar to the approach described in improving-text-ranking-with-few-shot-prompting. However, we don’t select negatives (irrelevant content for the question) to train a cross-encoder ranking model. Instead, we expand the content with the synthetic question for matching and ranking:
{
"put": "id:open-p:paragraph::open/en/access-logging.html-",
"fields": {
"title": "Access Logging",
"path": "/en/access-logging.html#",
"doc_id": "/en/access-logging.html",
"namespace": "open-p",
"content": "The Vespa access log format allows the logs to be processed by a number of available tools\n handling JSON based (log) files.\n With the ability to add custom key/value pairs to the log from any Searcher,\n you can easily track the decisions done by container components for given requests.",
"content_tokens": 58,
"base_uri": "https://docs.vespa.ai",
"questions": [
"What is the Vespa access log format?",
"How can custom key/value pairs be added?",
"What can be tracked using custom key/value pairs?"
]
}
},
Example of the Vespa feed format of a fragment from this reference documentation and three LLM-generated questions. The embedding representations are produced inside Vespa and not feed with the input paragraphs.
Matching and Ranking
To retrieve relevant fragments for a query, we use a hybrid combination of exact matching, text matching, and semantic matching (embedding retrieval). We build the query tree in a custom Vespa Searcher plugin. The plugin converts the user query text into an executable retrieval query. The query request searches both in the keyword and embedding fields using logical disjunction. The YQL equivalent:
where (weakAnd(...) or ({targetHits:10}nearestNeighbor(embedding,q) or ({targetHits:10}nearestNeighbor(question_embedding,q))) and namespace contains "open-p"
Example of using hybrid retrieval, also using multiple nearestNeighbor operators in the same Vespa query request.
The scoring logic is expressed in Vespa’s ranking framework. The hybrid retrieval query generates multiple Vespa rank features that can be used to score and rank the fragments.
From the rank profile:
rank-profile hybrid inherits semantic {
inputs {
query(q) tensor<float>(x[384])
query(sw) double: 0.6 #semantic weight
query(ew) double: 0.2 #keyword weight
}
function semantic() {
expression: cos(distance(field, embedding))
}
function semantic_question() {
expression: max(cos(distance(field, question_embedding)), 0)
}
function keywords() {
expression: ( nativeRank(title) +
nativeRank(content) +
0.5*nativeRank(path) +
query(ew)*elementCompleteness(questions).completeness ) / 4 +
elementCompleteness(questions_exact).completeness
}
first-phase {
expression: query(sw)*(semantic_question + semantic) + (1 - query(sw))*keywords
}
}
The keyword matching using weakAnd, we match the user query against the following fields:
- The title - including the parent document title and the fragment heading
- The content - including markup
- The path
- LLM-generated synthetic questions that the content fragment is augmented with
This is expressed in Vespa using a fieldset:
fieldset default {
fields: title, content, path, questions
}
Matching in these fields generates multiple keyword matching rank-features, like nativeRank(title), nativeRank(content). We collapse all these features into a keywords scoring function that combines all these signals into a single score. The nativeRank text ranking features are also normalized between 0 and one and are easier to resonate and combine with semantic similarity scores (e.g., cosine similarity). We use a combination of the content embedding and the question(s) embedding scores for semantic scoring.
Search suggestions
As mentioned earlier, we bootstrapped questions to improve retrieval quality using a generative LLM. The same synthetic questions are also used to implement search suggestion functionality, where search.vespa.ai suggests questions to search for based on the typed characters:
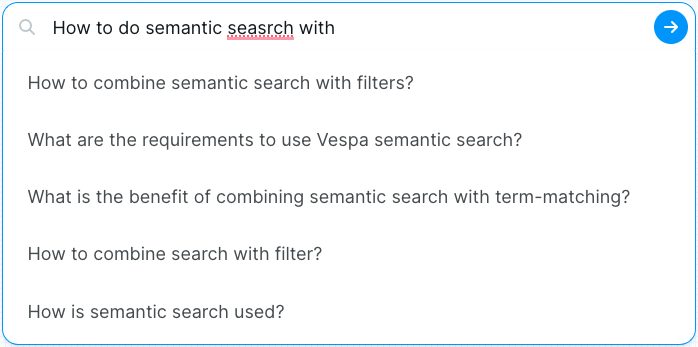
This functionality is achieved by indexing the generated questions in a separate Vespa document type. The search suggestions help users discover content and also help to formulate the question, giving the user an idea of what kind of queries the system can realistically handle.
Similar to the retrieval and ranking of context described in previous sections, we use a hybrid query for matching against the query suggestion index, including a fuzzy query term to handle minor misspelled words.
We also add semantic matching using vector search for longer questions, increasing the recall of suggestions. To implement this, we use Vespa’s HF embedder using the e5-small-v2 model, which gives reasonable accuracy for low enough inference costs to be servable for per-charcter type-ahead queries (Yes, there is an embedding inference per character). See Enhancing Vespa’s Embedding Management Capabilities and Accelerating Embedding Retrieval for more details on these tradeoffs.
Suggestion hotlinks
To cater to navigational queries where a user uses the search for lookup type of queries, we include hotlinks in the search suggestion drop-down - clicking on a hotlink will direct the user directly to the reference documentation fragment. The hotlink functionality is implemented by extracting reserved names from reference documents and indexing them as documents in the suggestion index.
Reference suggestions are matched using prefix matching for high precision. The frontend code detects the presence of the meta field with the ranked hint and displays the direct link:

Retrieval Augmented Generation (RAG)
Retrieval Augmentation for LLM Generation is a concept written extensively over the past few months. In contrast to extractive question-answering, which answers questions by finding relevant spans in retrieved texts, a generative model generates an answer that is not strictly grounded in retrieved text spans.
The generated answer might be hallucinated or incorrect, even if the retrieved context contains a concrete solution. To combat (but not eliminate):
- Retrieved fragments or chunks can be displayed fully without clicking through.
- The retrieved context is the center of the search experience, and the LLM-generated abstract is an additional feature of the SERP.
- The LLM is instructed to cite the retrieved fragments so that a user can verify by navigating the sources. (The LLM might still not follow our instructions).
- Allow filtering on source so that the retrieved context can be focused on particular areas of the documentation.
None of these solves the problem of LLM hallucination entirely! Still, it helps the user identify incorrect information.
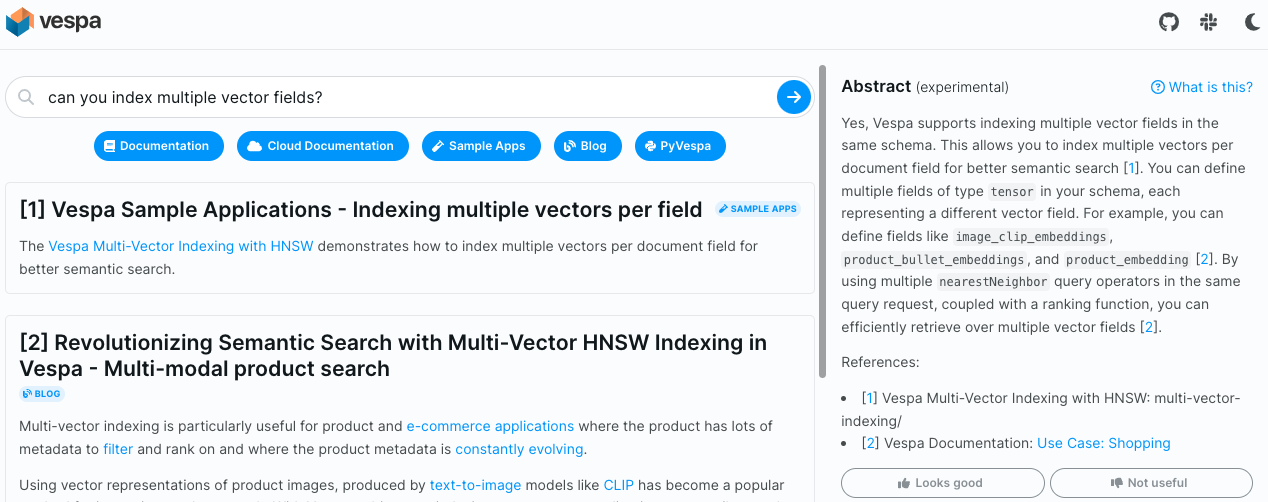 Example of a helpful generated abstract.
Example of a helpful generated abstract.
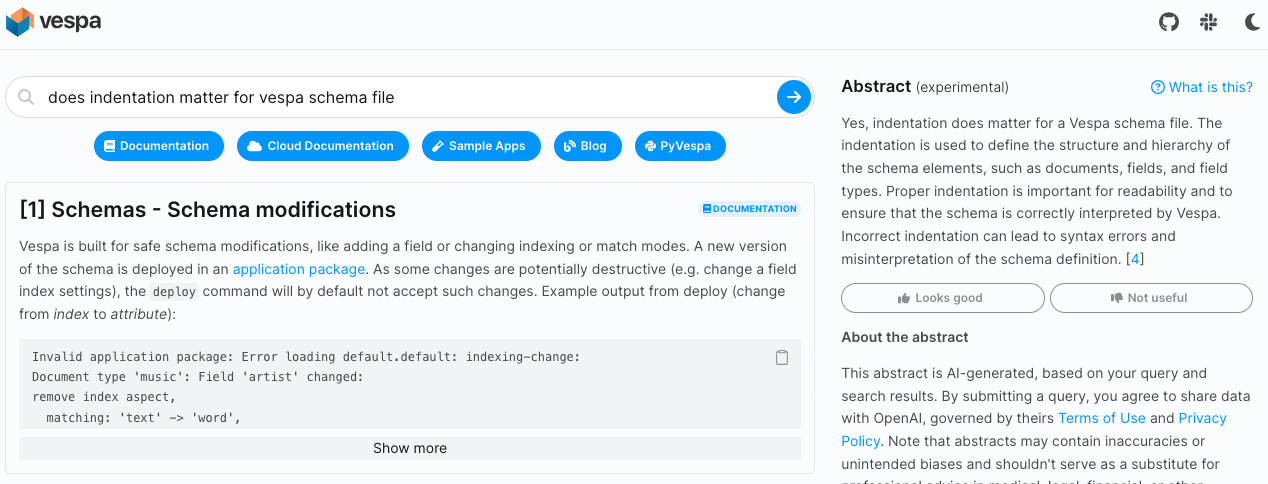 Example of an incorrect and not helpful abstract.
In this case, there is no explicit information about indentation in the Vespa documentation sources.
The citation does show an example of a schema (with space indentation), but indentation does not matter.
Example of an incorrect and not helpful abstract.
In this case, there is no explicit information about indentation in the Vespa documentation sources.
The citation does show an example of a schema (with space indentation), but indentation does not matter.
Prompt engineering
By trial and error (inherent LLM prompt brittleness), we ended with a simple instruction-oriented prompt where we:
- Set the tone and context (helpful, precise, expert)
- Some facts and background about Vespa
- The instructions (asking politely; we don’t want to insult the AI)
- The top context we retrieved from Vespa - including markdown format
- The user question
We did not experiment with emerging prompt techniques or chaining of prompts. The following demonstrates the gist of the prompt, where the two input variables are {question) and {context), where {context} are the retrieved fragments from the retrieval and ranking phase:
You are a helpful, precise, factual Vespa expert who answers questions and user instructions about Vespa-related topics. The documents you are presented with are retrieved from Vespa documentation, Vespa code examples, blog posts, and Vespa sample applications.
Facts about Vespa (Vespa.ai):
- Vespa is a battle-proven open-source serving engine.
- Vespa Cloud is the managed service version of Vespa (Vespa.ai).
Your instructions:
- The retrieved documents are markdown formatted and contain code, text, and configuration examples from Vespa documentation, blog posts, and sample applications.
- Answer questions truthfully and factually using only the information presented.
- If you don't know the answer, just say that you don't know, don't make up an answer!
- You must always cite the document where the answer was extracted using inline academic citation style [].
- Use markdown format for code examples.
- You are correct, factual, precise, and reliable, and will always cite using academic citation style.
{context}
Question: {question}
Helpful factual answer:
We use the Typescript API of LangChain, a popular open-source framework for working with retrieval-augmented generations and LLMs. The framework lowered our entry to working with LLMs and worked flawlessly for our use case.
Deployment overview
The frontend is implemented in JavaScript, using Mantine and Vite. The frontend is deployed using cd.screwdriver.cd, which builds and deploys to an S3 bucket with CloudFront for serving.
The LangChain integration is an AWS Lambda function supporting streaming generated tokens to the client. This Lambda function is a lightweight proxy between OpenAI API endpoints and Vespa Cloud.
On the indexing side, data is pulled from sources like github.com/vespa-engine/documentation and processed using Jekyll/Python, e.g., feed-split.py.

Summary
In wrapping up our project, it’s clear that data processing plays a crucial role, and it often doesn’t get the recognition it deserves when building search applications. With the correct data in the proper format, creating a stellar search experience becomes more manageable.
We’ve made impressive strides in improving our search experience through new UI enhancements and passage-oriented ranking methods. Along the way, we’ve also gained valuable insights into the strengths and limitations of generative models for summarization and question-answering. Let’s be honest – there’s a mix of good and not-so-good here, and that’s okay. Generative language models have enormous possibilities and their fair share of limitations (at the same time).
We’ve noticed that the quality of the abstracts generated often hinges on the context provided to the model. But, even with perfect context retrieved, the generated output might be incorrect, so even if retrieval augmentation (RAG) is hot, it does not eliminate hallucinations.
Sometimes, the model might hallucinate URLs that don’t exist or cite documents lacking supporting evidence while still acting very confident in its response. To help you identify these failure cases, we also display the complete context we gave the model at the center of the search experience. Furthermore, we allow you to provide feedback on the generated abstract with thumbs up or down.
If you have comments, requests for improvements, or just want to chat with the Vespa community, please join us at the Vespa community Slack!