
Lester Solbakken presenting at Berlin Buzzwords 2022
Berlin Buzzwords 2022 has just finished and we thought it would be great to summarize the event. Berlin Buzzwords is Germany’s most exciting conference on storing, processing, streaming and searching large amounts of digital data, with a focus on open source software projects.
AI-powered Semantic Search; A story of broken promises?
Jo Kristian Bergum from the Vespa team gave a talk on AI-powered Semantic Search; A story of broken promises?.
Semantic search using AI-powered vector embeddings of text, where relevancy is measured using a vector similarity function, has been a hot topic for the last few years. As a result, platforms and solutions for vector search have been springing up like mushrooms. Even traditional search engines like Elasticsearch and Apache Solr ride the semantic vector search wave and now support fast but approximative vector search, a building block for supporting AI-powered semantic search at scale.
Without doubt, sizeable pre-trained language models like BERT have revolutionized the state-of-the-art on data-rich text search relevancy datasets. However, the question search practitioners are asking themself is, do these models deliver on their promise of an improved search experience when applied to their domain? Furthermore, is semantic search the silver bullet which outcompetes traditional keyword-based search across many search use cases? This talk delves into these questions and demonstrates how these semantic models can dramatically fail to deliver their promise when used on unseen data in new domains.
If you were interested in this talk, why don’t you check out some of our previous work on state-of-the-art text ranking:
- Pretrained Transformer Language Models for Search - part 1
- Pretrained Transformer Language Models for Search - part 2
- Pretrained Transformer Language Models for Search - part 3
- Pretrained Transformer Language Models for Search - part 4
Also check out the Vespa MS Marco sample application which demonstrates how to represent state-of-the-art ranking methods with Vespa.
See also our blog posts on Vector search:
- Billion-scale vector search using hybrid HNSW-IF
- Query Time Constrained Approximate Nearest Neighbor Search
- Billion-scale vector search with Vespa - part two
- Billion-scale vector search with Vespa - part one
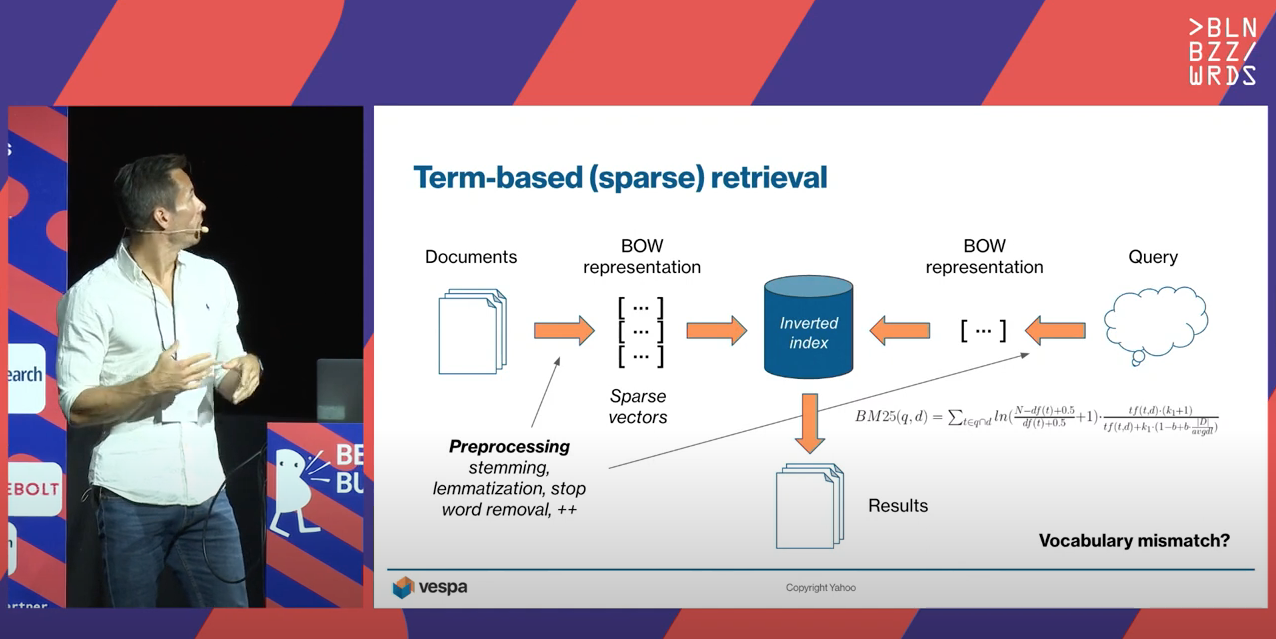
Hybrid search > sum of its parts?
Lester Solbakken from the Vespa team gave a talk on Hybrid search > sum of its parts?.
Over the decades, information retrieval has been dominated by classical methods such as BM25. These lexical models are simple and effective yet vulnerable to vocabulary mismatch. With the introduction of pre-trained language models such as BERT and its relatives, deep retrieval models have achieved superior performance with their strong ability to capture semantic relationships. The downside is that training these deep models is computationally expensive, and suitable datasets are not always available for fine-tuning toward the target domain.
While deep retrieval models work best on domains close to what they have been trained on, lexical models are comparatively robust across datasets and domains. This suggests that lexical and deep models can complement each other, retrieving different sets of relevant results. But how can these results effectively be combined? And can we learn something from language models to learn new indexing methods? This talk will delve into both these approaches and exemplify when they work well and not so well. We will take a closer look at different strategies to combine them to get the best of both, even in zero-shot cases where we don’t have enough data to fine-tune the deep model.
Understanding Vespa with a Lucene mindset
Atita Arora from OpenSource connections gave a great talk on Understanding Vespa with a Lucene mindset. Fantastic overview of Vespa, Vespa’s strengths and how Vespa compares to Apache Lucene based search engines.
Vespa is no more a ‘new kid on the block’ in the domain of search and big data. Everyone is wooed over reading about its capabilities in search, recommendation, and machine-learned aspects augmenting search especially for large data-sets. With so many great features to offer and so less documentation to how to get started on Vespa , we want to take an opportunity to introduce it to the lucene based search users. We will cover about Vespa architecture , getting started , leveraging advance features , important aspects all in the analogies easier for someone with a fresh or lucene based search engines mindset.
Matscholar: The search engine for materials science researchers
John Dagdelen from the department of materials science and engineering at UC Berkeley,
gave a insightful talk on Matscholar: The search engine for materials science researchers. This talk demonstrates how Vespa can be used to power advanced search use cases, including entity recognition,
embedding, grouping and aggregation.
Matscholar (Matscholar.com) is a scientific knowledge search engine for materials science researchers. We have indexed information about materials, their properties, and the applications they are used in for millions of materials by text mining the abstracts of more than 5 million materials science research papers. Using a combination of traditional and AI-based search technologies, our system extracts the key pieces of information and makes it possible for researchers to do queries that were previously impossible. Matscholar, which utilizes Vespa.ai and our own bespoke language models, greatly accelerates the speed at which energy and climate tech researchers can make breakthroughs and can even help them discover insights about materials and their properties that have gone unnoticed.
Summary
Berlin Buzzwords is a great industry conference, and the 2022 edition was no exception. Lots of interesting discussions, talks and new friends and connections were made.
If you were inspired by the Vespa talks you can get started by the following Vespa sample applications:
-
State-of-the-art text ranking: Vector search with AI-powered representations built on NLP Transformer models for candidate retrieval. The application has multi-vector representations for re-ranking, using Vespa’s phased retrieval and ranking pipelines. Furthermore, the application shows how embedding models, which map the text data to vector representation, can be deployed to Vespa for run-time inference during document and query processing.
-
State-of-the-art image search: AI-powered multi-modal vector representations to retrieve images for a text query.
These are examples of applications built using AI-powered vector representations and where real-world deployments need query-time constrained nearest neighbor search.
Vespa is available as a cloud service; see Vespa Cloud - getting started, or self-serve Vespa - getting started.