

Photo by Victoire Joncheray on Unsplash
We are excited to announce the general availability of a native Vespa ColBERT embedder implementation in Vespa, enabling explainable semantic search using deep-learned token-level vector representations.
This blog post covers:
- An overview of ColBERT, highlighting its distinctions from conventional text embedding models.
- The new native Vespa ColBERT embedder implementation, featuring an innovative asymmetric compression technique enabling a remarkable 32x compression of ColBERT’s token-level vector embeddings without significant impact on ranking accuracy.
- A comprehensive FAQ section covering various topics, including strategies for extending ColBERT’s capabilities to handle long contexts.
What is ColBERT?
The ColBERT retrieval and ranking model was introduced in ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT by Omar Khattab and Matei Zaharia. It is one of the most cited recent information retrieval papers, with over 800 citations. Later improvements (distillation, compression) were incorporated in ColBERT v2.
We have earlier described and represented ColBERT in Vespa. However, with the new native ColBERT embedder and enhanced support for compression, we have improved the developer experience and reduced the vector storage footprint by up to 32x.
Why should I care?
Typical text embedding models use a pooling method, like averaging, on the output token vectors from the final layer of transformer-based encoder models. The pooling generates a lone vector that stands for all the tokens in the input context window of the encoder model.
The similarity is solely based on this lone vector representation. In simpler terms, as the text gets longer, the representation becomes less precise—think of it like trying to sum up a whole passage with just one word.
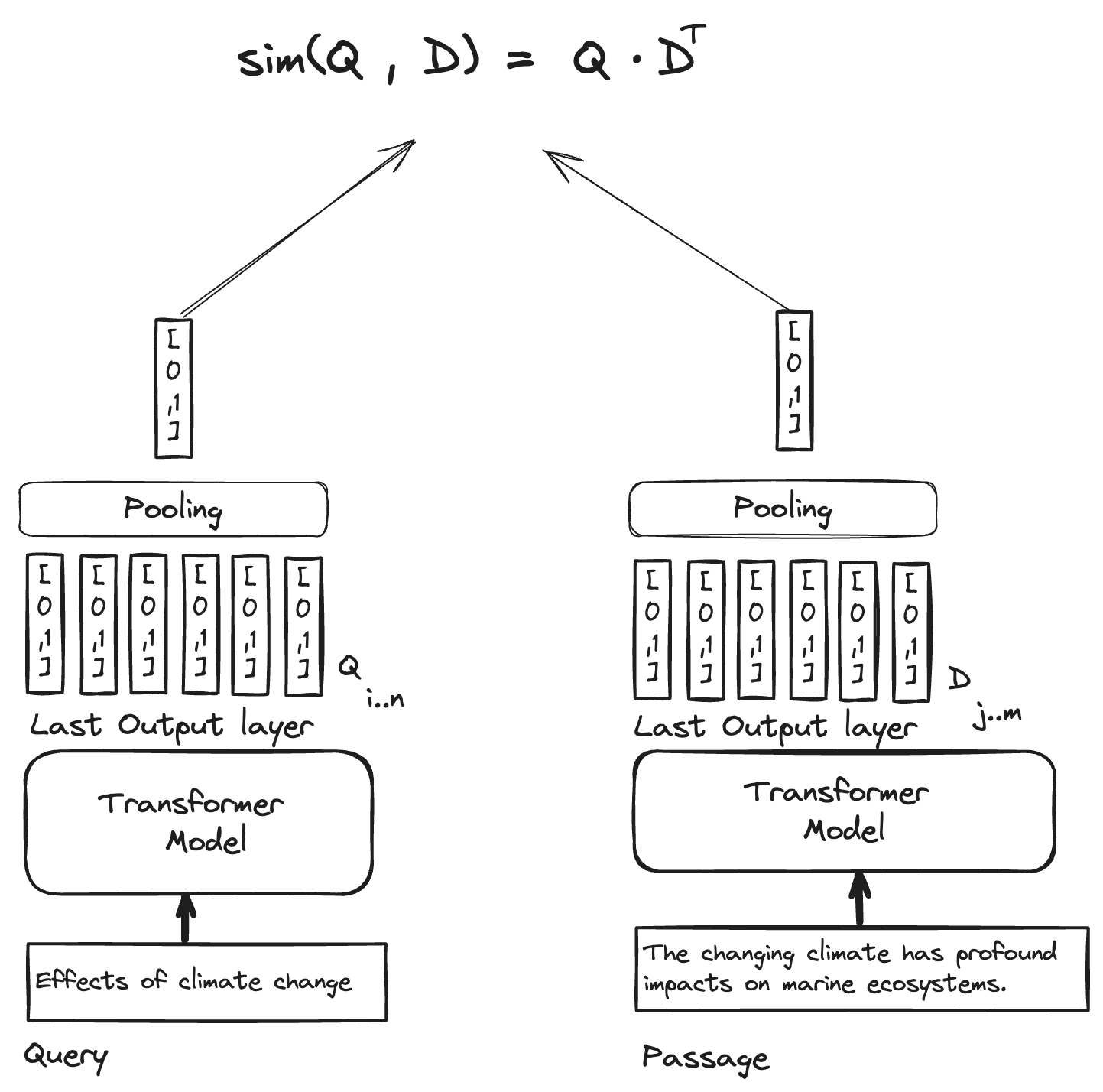
Illustration of regular text embedding models that encode all the words in the context window of the language model into a single vector representation. The query document similarity expression is only considering the lone vector representation from the pooling operation. For a great practical introduction and behind-the-scenes of text embedding models, we can recommend this blog post.
ColBERT represents the query and document by the contextualized token vectors without the pooling operation of regular embedding models. This per-token vector representation enables a more detailed similarity comparison between the query and the passage representation, allowing each query token to interact with all document tokens.
Each query token vector representation is contextualized by the other query token vectors, the same for the passage vector representations. The contextualization comes from the all-to-all attention mechanism of the transformer-based encoder model. The contextualization also includes the position in the text, so the same word repeating in the text is encoded differently and not like a bag of unique words (SPLADE).
Unlike cross-encoders that concatenate the two inputs into a single forward pass of the transformer model, with direct attention between them, the ColBERT architecture enables separation that enables pre-computation of the passage representation for the corpus.
The final missing piece is the ColBERT similarity function used to score passages for a query; meet MaxSim:
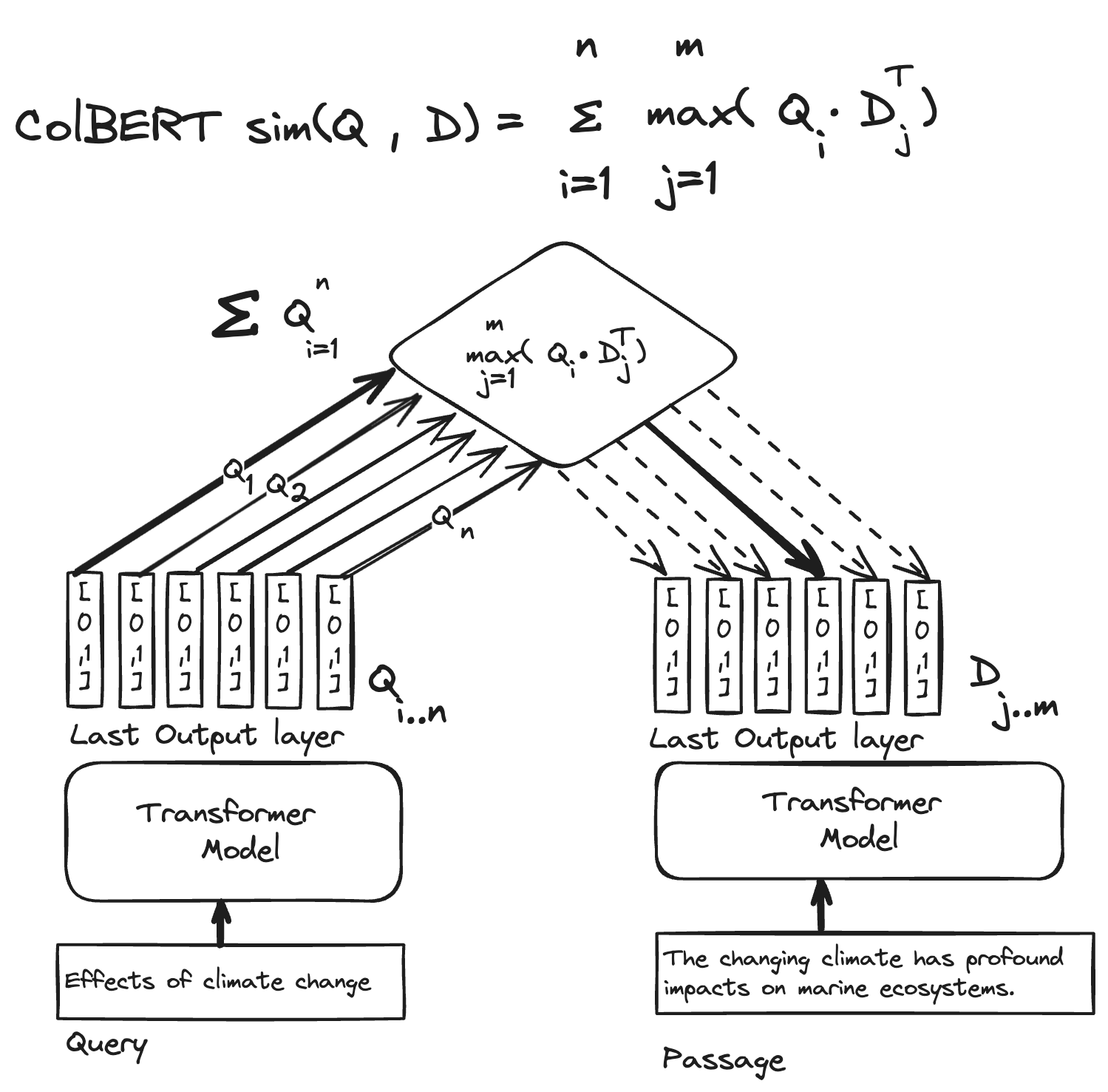
Illustration of the ColBERT model representation and the late-interaction similarity expression (MaxSim). For each query token representation (Qi), compute the dot product for all passage token representations (Dj) and keep track of the max score for query token vector i. The final similarity score is the sum of all max dot product scores for all query token vectors.
The ColBERT token-level vector representation and the MaxSim function have many advantages compared to regular text embedding models with pooling operations for search-oriented tasks.
- Superior ranking quality in zero-shot settings, approaching higher compute FLOPs cross-encoder models that input the query and passage.
- Better training efficiency. Fine-tuning a ColBERT model for ranking requires fewer labeled examples than regular text embedding models that must learn a single vector representation. More on that in Annotating Data for Fine-Tuning a Neural Ranker?.
- Explainability, unlike typical text embedding models, the MaxSim expression is explainable, similar to traditional text scoring functions like BM25.
Since the rise of semantic search, lack of explainability has been a pain point for practitioners. With regular text embedding models, one can only wave in the direction of the training data to explain why a given document has a high score for a query.
ColBERT’s similarity function with the token level interaction creates transparency in the scoring, as it allows for inspection of the score contribution of each token. To illustrate the interpretability capabilities of the similarity function, we built a simple demo that allows you to input queries and passages and explain the MaxSim scoring, highlighting terms that contributed to the overall score.

Screenshot of the demo that runs a small quantized ColBERT model in the browser, allowing you to explore the interpretability feature of the ColBERT model. The demo highlights the words that contributed most to the overall MaxSim score. The demo runs entirely in the browser without any server-side processing.
Vespa ColBERT embedder
The new native Vespa colbert-embedder is enabled and configured in the
Vespa application package’s services.xml
like other native Vespa embedders:
<container version="1.0">
<component id="colbert" type="colbert-embedder">
<transformer-model url="https://huggingface.co/colbert-ir/colbertv2.0/resolve/main/model.onnx"/>
<tokenizer-model url="https://huggingface.co/colbert-ir/colbertv2.0/raw/main/tokenizer.json"/>
</component>
</container>
With this simple configuration, you can start using the embedder in queries and during document processing like any other Vespa native embedder. See the Vespa colbert sample application for detailed usage examples.
Contextual token vector compression using binarization
The per-token vector embeddings take up more storage space than models that pool token vectors into a single vector. ColBERT reduces the Transformer model’s last layer dimensionality (e.g., 768 to 128), but it is still larger than single-vector models.
To address the storage overhead, we introduce an asymmetric binarization compression
scheme, significantly reducing storage with minimal ranking accuracy
impact as demonstrated in a later section. Query token vectors
maintain full precision, while document-side token vectors are compressed.
In Vespa, the token embeddings are represented as a mixed tensor:
tensor<tensor-cell-type>(dt{},x[dim]) where dim is the vector dimensionality of the contextualized
token embeddings and tensor-cell-type the precision (e.g float versus bfloat16).
The mapped tensor dimension (dt{} in this example) allows
for representing variable-length passages without
the storage overhead of using a fixed-length dense (indexed) representation.
The mixed tensor representation allows us also to extend the context
window of ColBERT to arbitrary-length documents by text chunking, where
one can add one more mapped dimension to represent the chunk.
Using int8 as the target tensor cell precision
type,
will cause Vespa embedder implementation to binarize the token
vectors and pack the compressed vector into dim/8 dimensions. If
the original token embedding dimensionality is 128 floats, we can
use 16 bytes (int8) to represent the compressed token embedding.
This compression technique reduces the storage footprint of the token vectors by 32x. Compared to a regular text embedding representation such as text-embedding-ada-002, which utilizes 1536 float dimensions (6144 bytes), the space footprint of ColBERT is lower for up to 384 tokens.
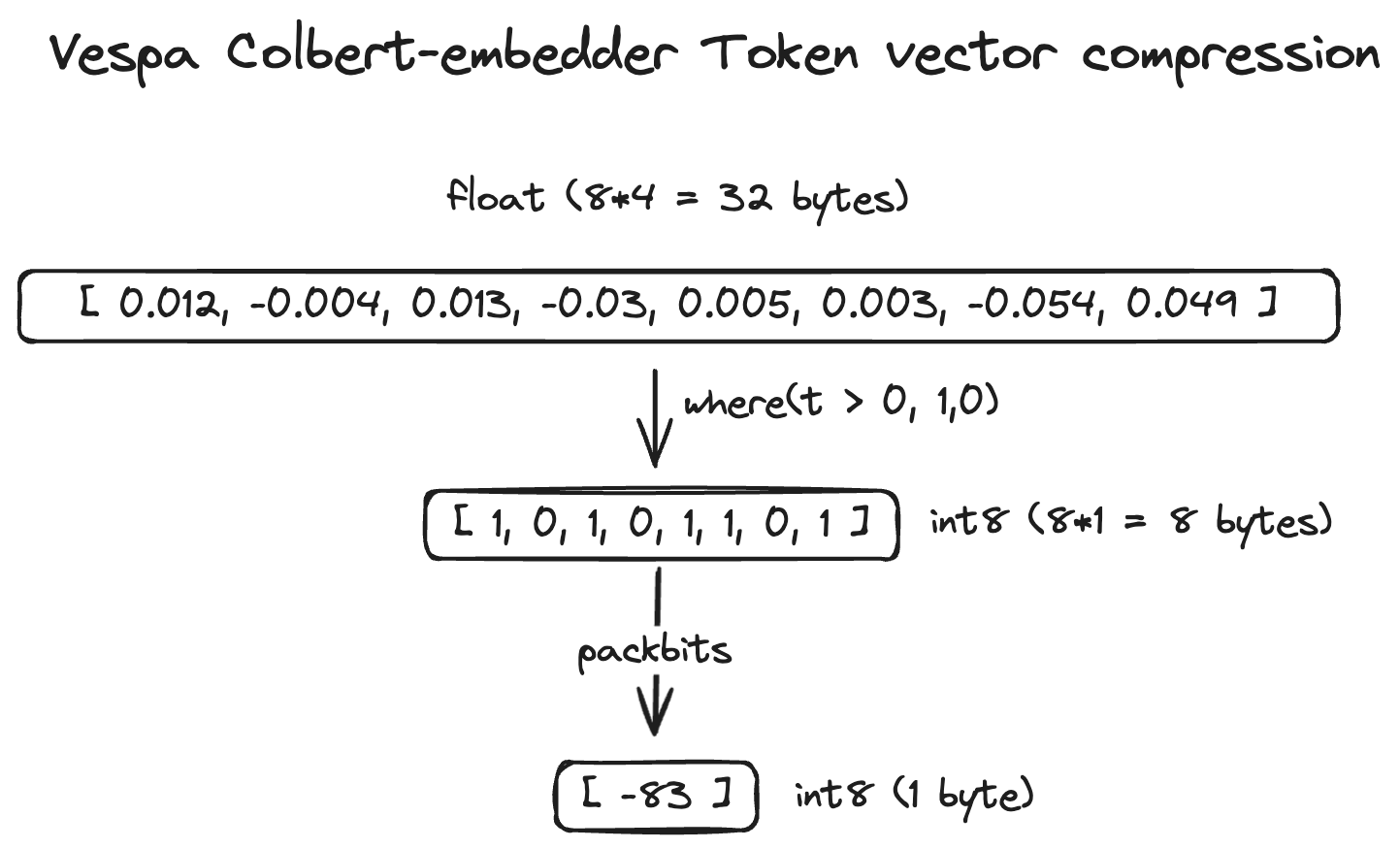
The binarization and compacting performed by the colbert embedder
for int8 target tensors is shown in the illustration above. This
asymmetric compression scheme is inspired by previous work with
billion-scale vector datasets.
colbert embedder schema usage with float representation:
schema doc {
document doc {
field text type string {}
}
field colbert type tensor<float>(dt{}, x[128]) {
indexing: input text | embed colbert | attribute
}
}
colbert embedder schema usage with int8 representation.
schema doc {
document doc {
field text type string {}
}
field colbert type tensor<int8>(dt{}, x[16]) {
indexing: input text | embed colbert | attribute
}
}
This configuration triggers compression.
colbert embedder schema usage with int8 representation and paragraph inputs.
schema doc {
document doc {
field chunks type array<string> {}
}
field colbert type tensor<int8>(paragraph{}, dt{}, x[16]) {
indexing: input chunks | embed colbert paragraph | attribute
}
}
The compressed version can be unpacked in ranking expressions using the
unpack_bits function
to restore (lossy) the 128-dimensional float representation.
This representation is what is used in the MaxSim tensor compute expression against the full precision query tensor representation.
Refer to usage examples in the documentation and the sample application for more details.
For applications with lower query throughput or smaller ranking windows - the mixed colbert tensor representation can also be offloaded to disk storage using the Vespa paged attribute option.
Ranking quality versus compression
We evaluate the impact of compression on three search-oriented datasets that are part of the BEIR benchmark.
We use CoLBERT as a second-phase ranking model in a phased ranking funnel,
where we re-rank results from a regular text embedding model (e5-small-v2).
For both experiments we use the colbert sample application
as the starting app.
We use a re-rank count of 50 using a second-phase expression, re-ranking the top hits from the E5 retriever. For datasets with both title and text, we concatenate them to form the input to the embedder. Note that we use the pre-computed document vector representations during the re-ranking stage, encoding the documents at query time would make it unusable for production use cases. Also, the re-ranking step is performed on the Vespa content nodes, avoiding shifting vector data around.
This type of retrieval and ranking pipeline is quite common. While the single-vector representation model with pooling excels in recall (retrieving all relevant information), it falls short in precision (capturing what is relevant) compared to more expressive MaxSim similarity.
The following reports nDCG@10 for both
E5 as a single stage retriever, and with ColBERT as a second-phase
ranking expression, with and without compression.
| Dataset | E5 | E5->ColBERT | E5->ColBERT compressed |
| beir/trec-covid | 0.7449 | 0.7939 | 0.8003 |
| beir/nfcorpus | 0.3246 | 0.3434 | 0.3323 |
| beir/fiqa | 0.3747 | 0.3919 | 0.3885 |
As can be observed above, there is not a significant difference between the compressed and non-compressed representations regarding effectiveness. However, the compressed version reduces the storage footprint by 32x!
We also note that the E5 models have been trained on millions of text pairs, while the ColBERT checkpoint used here has been trained on less than 100K examples.
Why does it work?
The query token vector representations remain unchanged, preserving their original semantic information. The compression method simplifies the document token vectors by representing positive dimensions as one and negative dimensions as zero. This binary representation effectively indicates the presence or absence of important semantic features within the document token vectors.
Positive dimensions contribute to increasing the dot product, indicating relevant semantic similarities, while negative dimensions are ignored.
Serving Performance
We do not touch on the model inference part of ColBERT as it scales the same way as a regular text embedding model; see this blog post on scaling the inference part. As we expose ColBERT MaxSim as a ranking expression, the ranking serving performance depends on the following factors:
- The number of hits exposed to the MaxSim tensor similarity expression
- The token-level vector dimensionality
- The number of token vectors per document and query
We can estimate the FLOPS for the MaxSim expression using the following formula:
FLOPs=2×M×N×K
where M is the number of query vectors, N is the number of document
vectors, and K is the ColBERT dimensionality. For example, for beir/nfcorpus, we have on average, 356 document and 32 query tokens.
This calculation yields 229,376 FLOPs for a single matrix multiplication. When re-ranking 1000 documents, this equates to 230 megaFLOPS (230 × 10^6). Empirically, this results in an operational time of around 230 milliseconds when utilizing a single CPU thread.
If we decrease the re-ranking window to 100 documents, the operation time reduces to 23 milliseconds. Similarly, if we had fewer document token vectors (shorter documents), we would get a linear reduction in latency; for example, reducing to 118 tokens would cut latency down to 8ms.
Depending on the specific application, employing Vespa’s support for using multiple threads per search can further reduce latency, leveraging the capabilities of multi-core CPU architectures more effectively. While increasing the number of threads per search does not alter the FLOP compute requirements, it reduces latency by parallelizing the workload.
Summary
We are enthusiastic about ColBERT, believing that genuine explainability in semantic search relies on contextual token-level embeddings, allowing each query token to interact with all document tokens.
This (late) interaction also unlocks explainability. Explaining why a passage scores as it does for a query has been a significant challenge in neural search with traditional text embedding models.
Another important observation is that the ColBERT architecture requires much fewer labeled examples for fine-tuning. Learning token-level vectors is more manageable than learning a single lone vector representation. With larger, generative models, we can efficiently generate in-domain labeled data to fine-tune ColBERT to our task and domain. As the ColBERT is based on a straightforward encoder model, you can fine-tune ColBERT on a single commodity GPU.
As ColBERT is a new concept for many practitioners, we have included a comprehensive FAQ section that address common questions we have received about ColBERT over the past few years.
ColBERT in Vespa FAQ
I have many structured text fields like product title and brand description, can I use ColBERT in Vespa?
Yes, you can either embed the concatenation of the fields, or have several colbert tensors, one per structured field. The latter allows you to control weighting in your Vespa ranking expressions with multiple Max Sim calculations (per field) for the same query input tensor.
Can I combine ColBERT with query filters in Vespa?
Yes, ColBERT is exposed as a ranking model in Vespa and can be used to rank documents matching the query formulation, including filters, and also result grouping.
Our ranking uses many signals other than textual semantic similarity, can I use ColBERT?
Yes, Vespa’s ranking framework allows many different signals of rank features as we call them in Vespa. Features can be combined in ranking expressions in ranking phases.
The MaxSim expression can be used as any other feature, and in combination with other custom features, even as a feature in a GBDT-based ranker using Vespa’s xgboost or lightgbm support.
How does ColBERT relate to Vespa’s support for nearestNeighbor search? It does not directly relate to Vespa’s nearestNeighbor support. The nearestNeighbor search operator could be used to retrieve hits in the first stage of a ranking pipeline and where ColBERT is used in a second-phase expression. Vespa’s native embedders map text to a tensor representation, which can be used in ranking; independent of the query retrieval formulation.
How does ColBERT relate to Vespa HNSW indexing for mixed tensors?
It does not. Since the MaxSim expression is only used during ranking
phases, enabling HNSW indexing
on the mixed
tensor representing the colbert token embeddings will be a fruitless
waste of resources. Make sure that you do not specify an index on
the mixed tensor field used to represent the document token embeddings.
Are there any multilingual ColBERT checkpoints?
The official checkpoint has only been trained on a single dataset of English texts and uses English vocabulary. Recently, we have seen more interest in multilingual checkpoints (See M3).
Do I need to use the new colbert-embedder if I want to use ColBERT for ranking in Vespa?
No, we added colbert-embedder as a convenience feature. Embedding (pun intended) the embedder into Vespa allows for inference acceleration (GPU) and shifting considerably fewer bytes over the network than doing the inference outside of Vespa.
You can still produce ColBERT-like token level embeddings outside of Vespa and pass the document tensor at indexing time, and the query tensor using the Vespa query API. See this notebook for using M3 with Vespa for inspiration.
Can ColBERT handle long contexts?
It is possible to perform chunking like with traditional context length limited single-vector embedding models. Since Vespa 8.303.17, the colbert-embedder also supports array inputs, so one can store one ColBERT representation per paragraph-sized text chunk.
Using an array of strings as input to the embedder requires a 3d
mixed tensor with two mapped dimensions. In the example below,
the mapped paragraph dimension represents the chunk id (array index).
schema doc {
document doc {
field chunks type array<string> {}
}
field colbert type tensor<int8>(paragraph{}, dt{}, x[16]) {
indexing: input chunks | embed colbert paragraph | attribute
}
}
We can then, wrap the MaxSim tensor expression used for a single input with another tensor
reduce operation, for example to find the best matching paragraph,
we can reduce the paragraph dimension using max aggregation.
See this
Vespa tensor playground
example
that demonstrates both MaxSim for a single input text and
multiple chunked inputs. Note that having another mapped level increases the number of dot products.
Can I combine ColBERT with reranking with cross-encoder models in Vespa?
Yes, an example phased ranking pipeline could use hybrid retrieval, re-rank with ColBERT, and perform a final global phase re-ranking with a cross-encoder.
Using ColBERT as an intermediate step can help reduce the ranking depth of the cross-encoder. The Vespa msmarco ranking sample application demonstrates such an effective ranking pipeline, including the colbert-embedder.
How does ColBERT compare to hybrid search?
ColBERT can be used in a hybrid search
pipeline
as just another neural scoring feature, used in any of the Vespa
ranking phases (preferably in second-phase for optimal performance
to avoid moving vector data up the stateless container for
global-phase evaluation).
Vespa allows combining the MaxSim score with other scores using, for example, reciprocal rank fusion or other normalization rank features. The sample application features examples of using ColBERT MaxSim in a hybrid ranking pipeline.
Can I run ColBERT if I’m GPU-poor?
Yes, you can. The model inference (mapping the text to vectors) is compute intensive (comparable with regular text embedding models) and benefits from GPU inference. It’s possible to use a quantized model for CPU inference and this works well with low latency for shorter input sequences, e.g queries. You might want to consider this checkpoint for CPU-inference as it is based on a small Transformer mode. It also uses 32-dimensional vectors, with the mentioned compression schema reduces the footprint of the token vectors down to 4 bytes per token vector.
Why is ColBERT interpretable while regular text embeddings are not?
By inspecting the query <-> document token-level similarities, we can deduce which tokens in the document contributed the most to the score.
What are the tradeoffs? If it stores a vector per token, it must be expensive!
We can look at performance and deployment cost along three axes: Effectiveness (ranking quality), storage, and computations. In this context, we can recommend Moving Beyond Downstream Task Accuracy for Information Retrieval Benchmarking, which provides a framework to compare different methods.
As the ColBERT document representation in Vespa can be offloaded to disk, it becomes drastically cheaper than data structures used for retrieval (shortlisting).
Why didn’t you expose the ColBERT 2 PLAID retrieval optimization in Vespa?
Primarily because Vespa is designed for low-latency real-time indexing, and the PLAID optimization requires batch processing the document token vectors to find centroids. This centroid selection would not work well in a real-time setting where our users expect outstanding performance from document number one to billions of documents. With Vespa, users can use different retrieval mechanisms and still enjoy the power of ColBERT in ranking phases.
What other vector databases support ColBERT out-of-the box?
No other vector database or search engine supports ColBERT out-of-the-box as far as we know.
That is a lot of dot products - do you use any acceleration to speed it up?
Yes, MaxSim is a more expressive interaction between the query and the document than regular text embedding models, but still two orders fewer FLOPs than cross-encoders.
Vespa’s core backend is written in C++, and the dot products are accelerated
using SIMD instructions.
Why is ColBERT not listed on the MTEB?
The MTEB benchmark only lists single vector embedding models and the benchmark covers many different tasks other than retrieval/re-ranking. Similarly, cross-encoders or other Information Retrieval (IR) oriented models are also not listed on MTEB.
How does ColBERT compare with listwise prompt rank models like RankGPT?
The core difference is the FLOPs versus the effectiveness, both can be used in a ranking pipeline and where ColBERT can reduce the number of documents that are re-ranked using the more powerful (but also several orders higher FLOPs) listwise prompt ranker.
How can I produce a ColBERT-powered contextualized snippet like in the demo?
We are working on integrating this feature in Vespa, the essence is to use the MaxSim interaction to find which of the terms in the document contributed most to the overall score. This, can in practise be done by returning the similarity calculations as a tensor using match-features, then a custom searcher can use this information to highlight the source text. This Vespa tensor playground example might be helpful.
Can I fine-tune my own ColBERT model, maybe in a different language than English?
Yes you can, https://github.com/bclavie/RAGatouille is a great way to get started with training ColBERT models and the base-model can also be a multilingual model. We can also recommend UDAPDR: Unsupervised Domain Adaptation via LLM Prompting and Distillation of Rerankers that fine-tunes a ColBERT model using synthetic data. See also related work for in-domain adaption of ranking models.
What do you mean by zero-shot in the context of retrieval and ranking?
See Improving Zero-Shot Ranking with Vespa Hybrid Search for more context on the difference between applying a ranking model in-domain and out-of-domain (zero-shot) setting.
How could you empirically observe the ranking contribution to latency?
Vespa allows per query tracing and profiling of queries which is extremely useful for understanding which parts of a retrieval and ranking pipeline consumes time and resources. With this feature, we could experiment with a varying number of hits exposed to ranking with a query time parameter overriding the schema configuration.
Do any of the embedding model providers support ColBERT-like models?
We see increased interest in training ColBERT type of models. For example, Jina.ai just announced a ColBERT checkpoint with extended context length.
We believe that a promising future direction for embedding models is to provide multiple optional representations, see M3.
I have more questions; I want to learn more!
For those interested in learning more about Vespa or ColBERT, join the Vespa community on Slack or Discord to exchange ideas, seek assistance from the community, or stay in the loop on the latest Vespa developments.
