

Photo by Jamie Street on Unsplash
Updated 2022-10-21: Added links and clarified some sections
In this blog series we demonstrate how to represent transformer models in a multi-phase retrieval and ranking pipeline using Vespa.ai. We also evaluate these models on the largest Information Retrieval (IR) relevance dataset, namely the MS Marco Passage ranking dataset. Furthermore, we demonstrate how to achieve close to state-of-the-art ranking using miniature transformer models with just 22M parameters, beating large ensemble models with billions of parameters.
Blog posts in this series:
- Post one: Introduction to neural ranking and the MS Marco passage ranking dataset
- Post two: Efficient retrievers, sparse, dense, and hybrid retrievers
- Post three: Re-ranking using multi-representation models (ColBERT)
- Post four: Re-ranking using cross-encoders
In this first post we give an introduction to Transformers for text ranking and three different methods of applying them for ranking. We also cover multi-phase retrieval and ranking pipelines, and introduce three different ways to efficiently retrieve documents in a phased retrieval and ranking pipeline.
Introduction
Since BERT was first applied to search and document ranking, we at the Vespa team have been busy making it easy to use BERT or Transformer models in general, for ranking and question answering with Vespa.ai. In previous work, we demonstrated how to use BERT as a representation model (bi-encoder), for efficient passage retrieval for question answering. We also demonstrated how we could accelerate BERT models for production serving using distillation and quantization.
Search or information retrieval is going through a neural paradigm shift, some have even called it the BERT revolution. The introduction of pre-trained language models BERT have led to significant advancement of the state of the art in search and document ranking.
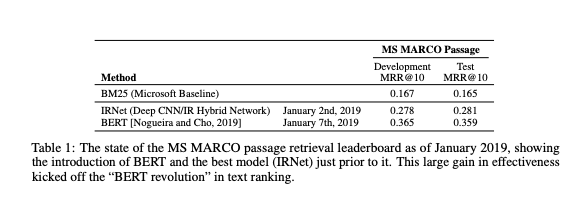
The table shows how significant the advancement was when first applied to the MS MARCO Passage Ranking leaderboard. The state-of-the-art on MS Marco passage ranking advanced by almost 30% within a week, while improvements up until then had been incremental at best. Compared to the baseline BM25 text ranking (default Apache Lucene 9 text scoring), applying BERT improved the ranking effectiveness by more than 100%.
The table above is from Pretrained Transformers for Text Ranking: BERT and Beyond, which is a brilliant resource for understanding how pre-trained transformers models can be used for text ranking. The MS MARCO Passage ranking relevancy dataset consists of about 8.8M passages, and more than 500 000 queries with at least one judged relevant document. It is by far the largest IR dataset available in the public domain and is commonly used to evaluate ranking models.
The MS Marco passage ranking dataset queries are split in three different subsets, the train, development (dev) and test (eval). The train split can be used to train a ranking model using machine learning. Once a model is built, one can test the effectiveness of the ranking model on the development and test split. Applying the learned model on the development and test set is called in-domain usage of the model. If the trained ranking model is applied on a different relevancy dataset, it’s usually referred to as out of domain usage, or zero-shot. How well models trained on MS Marco query and passage pairs generalize to other domains is out of scope for this blog post, but we can sincerely recommend BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models.
The official evaluation metric used for the MS Marco Passage ranking leaderboard is MRR@10. The name might sound scary, but it’s a trivial way to judge the effectiveness of a ranking algorithm. RR@10 is the Reciprocal Rank of the first relevant passage within the top 10 ranking positions for a given query. @k denotes the depth into the top ranking documents we look for the first relevant document. The reciprocal rank formula is simply 1/(position of the first relevant hit). If the judged relevant hit (as judged by a human) is ranked at position 1 the reciprocal rank score is 1. If the relevant hit is found at position 2 the reciprocal rank score is 0.5 and so on. The mean in mean reciprocal rank is simply the mean RR over all queries in the dev or test split which gives us an overall score. The MS Marco passage ranking development (dev) set consists of 6,980 queries.
The query relevance judgment list for the development (dev) set is in the public domain. Researchers can compare methods based on this. The judgements for the eval query set is not in the public domain. Researchers, or industry practitioners, need to submit their ranking for the queries in the test set to have the MRR@10 evaluated and the ranking run listed on the leaderboard. Note that the MS Marco ranking leaderboards are not run time constrained, so many of the submissions take days of computation to produce ranked lists for the queries in dev and eval splits.
There is unfortunately a lot of confusion in the industry on how BERT can successfully be used for text ranking. The IR research field has moved so fast since the release of BERT in late 2018 that the textbooks on text ranking are already outdated. Since there is no textbook, industry practitioners need to look at how the research community is applying BERT or Transformer models for ranking. BERT is a pre-trained language model, and to use it effectively for document or passage ranking, it needs to be fine-tuned for retrieval or ranking. For examples of not so great ways to use BERT for ranking, see How not to use BERT for Document ranking.
As demonstrated in Pretrained Transformers for Text Ranking: BERT and Beyond, pre-trained language models of the Transformer family achieve best accuracy for text ranking and question answering tasks when used as an interaction model with all-to-all cross-attention between the query and document. Generally, there are 3 ways to use Transformer models for text ranking and all of them require training data to fine tune for retrieval or ranking.
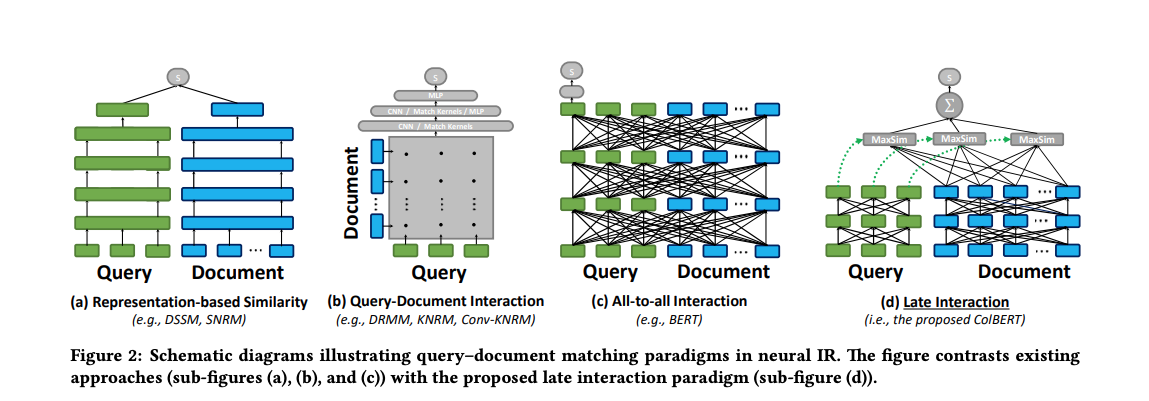
Figure from ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT illustrating various deep neural networks for ranking. In the following section we give an overview of three of these methods using Transformer models.
Representation based ranking using Transformer models
It is possible to use the Transformer model as the underlying deep neural network for representation based learning. Given training data, one can learn a representation of documents and queries so that relevant documents are closer or more similar in this representation than irrelevant documents. The representation based ranking approach falls under the broad representation learning research field and representation learning can be applied to text, images, videos or even combinations (multi-modal representations). For text ranking, queries and documents are embedded into a dense embedding space using one or two Transformer models (bi-encoders). The embedding representation is learned by the training examples given to the model. Once the model has been trained, one can pre-compute the embeddings for all documents, and at query time, use nearest neighbor search for efficient document retrieval.
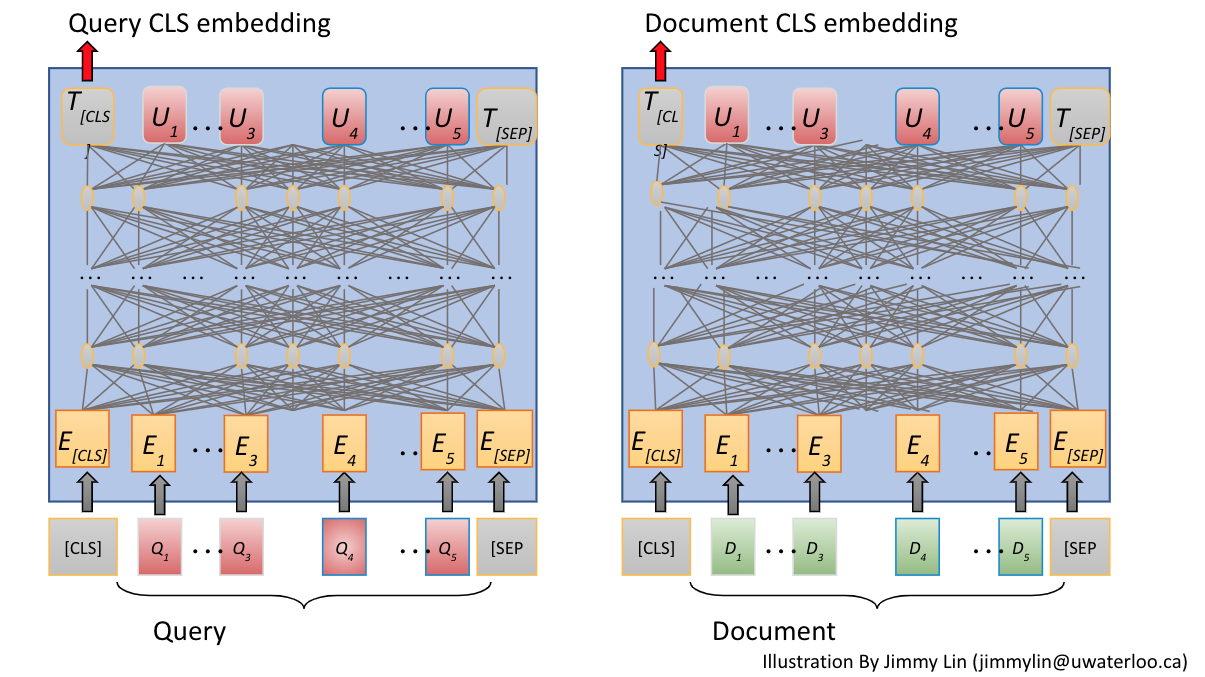
Document retrieval using dense embedding models, is commonly referred to as dense retrieval. The query and the document are embedded independently, and the model is during training given examples of the form (query, relevant passage, negative passage). The model(s) weights are adjusted per batch of training triplets. The embedding representation from the Transformer model could be based on for example the CLS token of BERT (Classification Token), or using a pooling strategy over the last Transformer layer.
The huge benefit of using representation based similarity on top of Transformer models is that the document representation can be produced offline by encoding them through the trained transformer and unless the model changes, this only needs to be done once when indexing the document. At online serving time, the serving system only needs to obtain the query embedding by running the query through the transformer model and use the resulting query embedding vector as the input to a nearest neighbor search in the dense embedding space to find relevant documents. On the MS Marco Passage ranking set, dense retrieval using a learned representation has demonstrated good results over the last year or so. Dense retrievers achieve much better accuracy (MRR@10 and Recall@1000) than sparse traditional search using exact lexical matching (e.g BM25) and the current state-of-the-art uses a dense retriever as the first phase candidate selection for re-ranking using a more sophisticated (and computationally expensive) all-to-all interaction model.
Since the query is usually short, the online encoding complexity is relatively low and encoding latency is acceptable even on a cpu serving stack. Transformer models with full all to all cross attention have quadratic run time complexity with the input sequence length so the smaller the sequence input the better the performance is. Most online serving systems can also cache the query embedding representation to save computations and reduce latency.
All to all interaction ranking using Transformers
The “classic way to use BERT for ranking is to use it as an all-to-all interaction model where both the query and the document is fed through the Transformer model simultaneously and not independently as with the representation based ranking model. For BERT this is usually accomplished with a classification layer on top of the CLS token output, and the ranking task is converted into a classification task where one classifies if the document is relevant for the query or not (binary classification). This approach is called monoBERT or vanilla BERT, or BERT cat (categorization). It’s a straightforward approach and inline with the proposed suggestions of the original BERT paper for how to use BERT for task specific fine tuning.
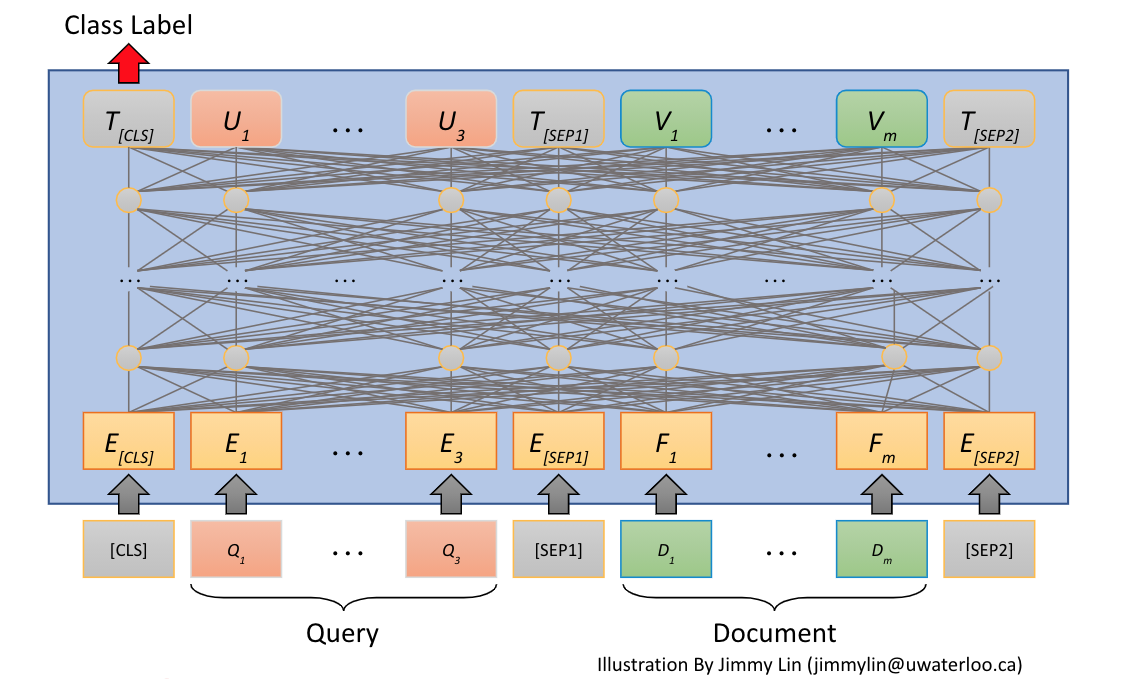
Similar to the representation model, all to all interaction models need to be trained by triplets and the way we sample the negative examples (irrelevant) is important for the overall effectiveness of the model. The first BERT submission to the MS Marco passage ranking used mono-BERT to re-rank the top 1K documents from a more efficient sparse first phase retriever (BM25).
With all to all interaction there is no known way to efficiently pre-compute the document representation offline. Running online inference with cross-attention models over all documents in a collection is computationally prohibitively expensive even for large organizations like Google or Microsoft, so to deploy it for production one needs a way to reduce the number of candidate documents which are fully evaluated using the all to all cross attention model. This has led to increased interest in multi-stage retrieval and ranking architectures but also more efficient Transformer models without quadratic complexity due to the cross attention mechanisms (all to all attention).
Late Interaction using Transformers
An alternative approach for using Transformers for ranking was suggested in ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT.
Unlike the all to all query document interaction model, the late contextualized interaction over BERT enables processing the documents offline since the per document token contextual embedding is generated independent of the query tokens. The embedding outputs of the last Transformer layer is calculated at document indexing time and stored in the document. For a passage of 100 tokens we end up with 100 embedding vectors of dimensionality n where n is a tradeoff between ranking accuracy and storage (memory) footprint. The dimensionality does not necessarily need to be the same as the transformer model’s hidden size. Using 32 dimensions per token embedding gives almost the same accuracy as the larger 768 dim of BERT base. Similar one can use low precision like float16 or quantization (int8) to reduce the memory requirements per dimension.
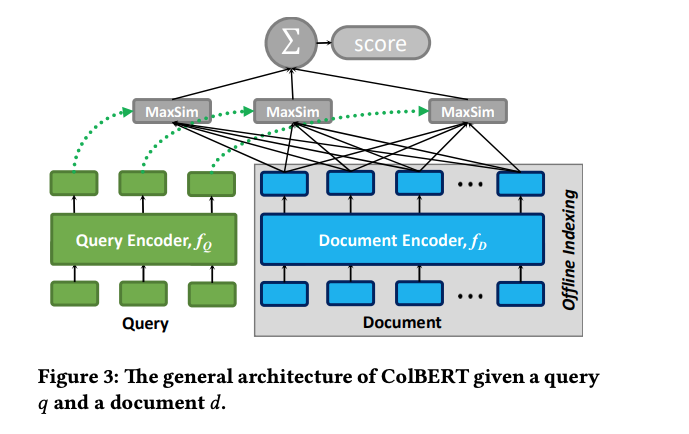
The ability to run the document and obtain the per term contextual embedding offline significantly speeds up onstage query evaluation, since at query time one only needs to do one pass through the Transformer model with the query to obtain the contextual query term embeddings. Then calculate the proposed MaxSim operator over the pre-computed per term contextualized embeddings for the documents we want to re-rank.
Similar to the pure representation based model we only need to encode the query through the transformer model at query time. The query tokens only attend to other query tokens, and similar document tokens only attend to other document tokens.
As demonstrated in the ColBERT paper, the late interaction ColBERT model achieves almost the same ranking accuracy as the more computationally complex all-to-all query document interaction models. The model is trained in the same way as with representation or all-to-all interaction models. The downside of the late interaction model is the storage cost of the document term embeddings. Instead of one embedding like with the single-representation model there is an embedding vector per term in the document.
How large depends on the number of dimensions and the precision used per value (e.g. using bfloat16 saves 50% compared to float32).
Multi-phase retrieval and ranking
Due to computationally complexity of especially the all to all interaction model there has been renewed interest in multiphase retrieval and ranking. In a multiphased retrieval and ranking pipeline, the first phase retrieves candidate documents using a cost efficient retrieval method and the more computationally complex cross-attention or late interaction model inference is limited to the top ranking documents from the first phase.
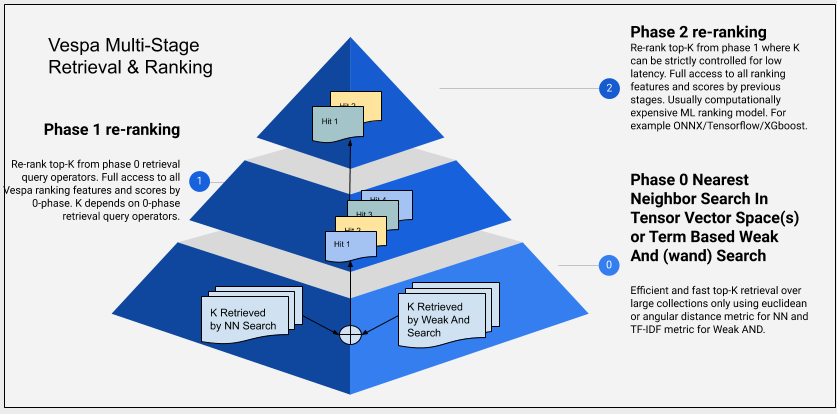
Illustration of a multi-stage retrieval and ranking architecture is given in the figure above. The illustration is from Phased ranking with Vespa. The three phases illustrated in the diagram is per content node, which is retrieving and re-ranking a subset of the total document volume. In addition, one can also re-rank the global top-scoring documents after the results from the nodes involved in the query are merged to find the global best documents. This step might also involve diversification of the result set before final re-ranking.
A multi-phase retrieval and ranking architecture is described in Bert passage re-ranking with BERT. The authors describe a pipeline where the first ranking phase uses simple text ranking (BM25) and the second phase re-ranks the top-K documents from the first phase. Similar multi-stage retrieval and ranking architectures have been used for open domain question answering applications where a set of candidate passages are retrieved and where a fine-tuned cross-attention Transformer model is used to extract the best answer from the retrieved top-k candidate passages.
Broadly there are two categories of efficient sub-linear retrieval methods and also a hybrid combination of the two.
Sparse Lexical Retrieval
Classic information retrieval (IR) relies on lexical matching. A technique that has been around since the early days of Information Retrieval. One example of a popular lexical-based retrieval scoring function is BM25. Retrieval can be done in sub-linear time using inverted indexes and accelerated by dynamic pruning algorithms like WAND. Dynamic pruning algorithms avoid exhaustively scoring all documents which match at least one of the query terms.
Dense Retrieval
Embedding based models embed or map queries and documents into a latent low dimensional dense embedding vector space and use vector search to retrieve documents. Dense retrieval could be accelerated by using approximate nearest neighbor search, for example indexing the document vector representation using HNSW graph indexing. In-domain dense retrievers based on bi-encoder architecture trained on MS Marco passage data have demonstrated that they can outperform sparse lexical retrievers with a large margin. In a multi stage retriever and ranking pipeline, the first stage is focused on getting a good recall at k where k is the re-ranking depth we can afford from a computationally complexity perspective (cost and serving latency).
Both of these retrieval methods are capable of searching through millions of documents per node with low latency and cost, Vespa supports both methods.
Hybrid Dense Sparse Retrieval
Recent research indicates that combining dense and sparse retrieval improve recall, see for example A Replication Study of Dense Passage Retriever. The hybrid approach combines dense and sparse retrieval but requires search technology which supports both sparse lexical and dense retrieval. Vespa.ai supports hybrid retrieval in the same query by combining the WAND and ANN algorithms.
Summary
In this blog post we have introduced the MS Marco Passage Ranking dataset and how BERT or Transformer models in general have significantly advanced the state of the art of text ranking. We looked at the three different approaches for using Transformers for retrieval and (re)ranking and finally we covered multi-stage retrieval and ranking.
In the next blog post in this series, we’ll look at efficient candidate retrievers:
- Sparse lexical retrieval accelerated by the WAND query operator and how it compares to exhaustive search (OR)
- Dense retrieval accelerated by ANN query operator in Vespa (HNSW) and representing the Transformer based query encoder model in Vespa
- Hybrid search - combining the best of both.
In the third post, we will look at re-rankers using ColBERT and in the fourth post, we will add an all-to-all interaction model to the mix.