
Welcome to the latest edition of the Vespa newsletter. In the previous update, we introduced the Vespa.ai Playground, the Vespa Kubernetes Operator, Pyvespa 1.0, and more.
This month, we’re announcing several updates focused on retrieval quality, ranking flexibility, and developer productivity. Each feature is designed to help engineering teams build faster, more accurate, and more maintainable retrieval and ranking systems, while giving businesses better relevance, lower operational overhead, and more predictable performance at scale.
Let’s dive into what’s new.
Calling All Vespians: Vespa.ai Live Has Landed

As more teams build with Vespa, bringing the community closer together has become a major focus for us. Earlier this year, we ran our first virtual meetups, extending our Slack community and were joined by more than 100 Vespians from around the world — from the US and Ukraine to Singapore, Australia, Kazakhstan, Egypt, and beyond. But while virtual events are great, nothing quite compares to meeting in person — learning from peers, exchanging ideas, and continuing the conversation over coffee, beer, or wine. That’s why we’re excited to announce our first in-person community meetup: Vespa.ai Live!
The event includes technical sessions, real-world user experiences, expert panels, interactive unconference discussions, and plenty of opportunities to connect with others building in this space. Hosted by The Search Juggler, Charlie Hull, the day will bring together external experts and leading authors Trey Grainger and Doug Turnbull, Vespa engineers, community voices with speakers from Walmart, Etsy and RavenPack, and a keynote from Vespa co-founder and CEO Jon Bratseth.
On September 9, join the pre-event training, with Vespa 101: Getting started with Vespa, and Ranking 202: A deeper dive into improving retrieval quality - details and registration.
Most of all, Vespa.ai Live is intended to be community-driven — where Vespians share lessons learned and boldly go beyond the frontier of modern AI retrieval.
Product updates
- Vespa Cloud: Detailed metric dashboards
- Vespa Cloud: Index backup
- Vespa Cloud: Fine-grained maintenance controls
- Vespa Cloud: Voyage AI, OpenAI, and Mistral AI embedding integration
- Vespa Cloud: Custom resource tags
- Vespa skills for agents
- A new query operator for text matching
- Cluster-size independent configuration of relevance effort
- Boolean array fields
- Match specific array elements
- In-memory document ids
- Search group pinning
- Near matching aware ranking
- Detect ignored write operations
- Accessing the max first phase score in re-ranking
- Geo distance in grouping
Vespa Cloud: Detailed metric dashboards
As companies deploy their large-scale latency-sensitive applications on Vespa Cloud there is a need for more detailed insights into how the application is performing. While the Vespa Cloud Console has always provided an overview metrics dashboard, many finer details have only been available to Vespa’s operations engineers.
What’s new: We have added all the metrics dashboard used by Vespa engineers to the console so that customers who want to are empowered to dig as deeply as they like. We’ve also added explanations to the dashboards to make them easier to understand.
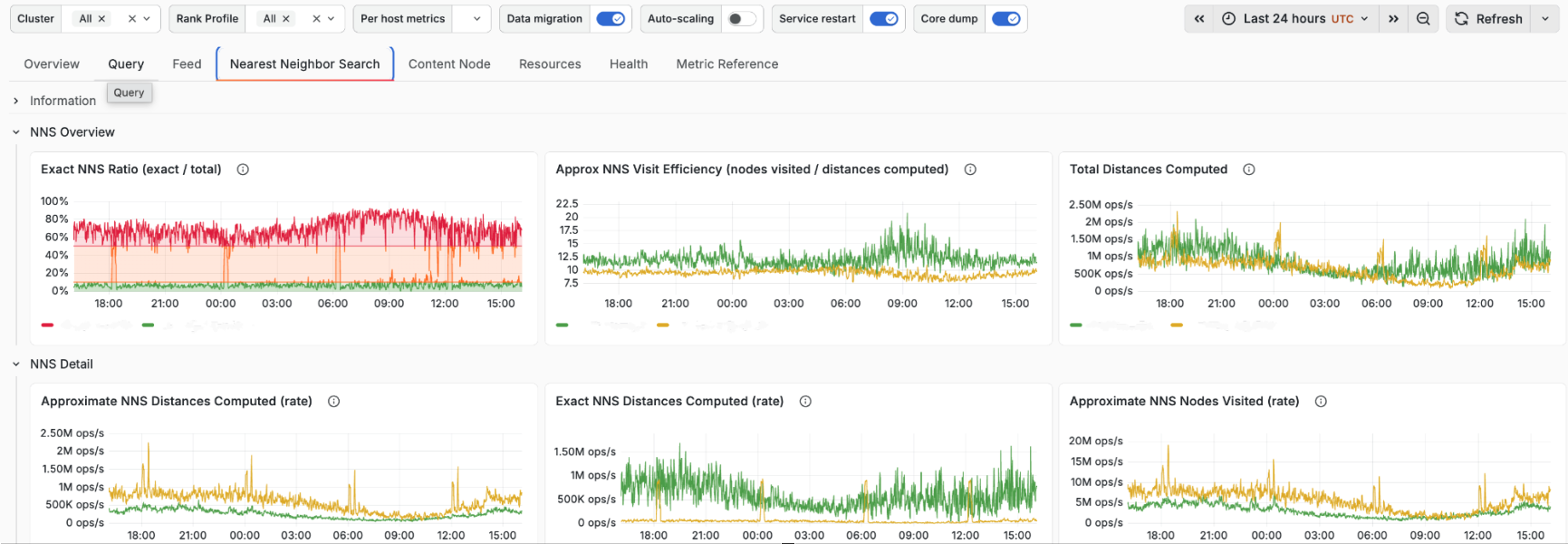
Vespa Cloud: Index backup
Reliability at scale means being prepared for the unexpected. Vespa Cloud now provides automated snapshot backups of indexes from content nodes, enabling catastrophe recovery without a full re-index.
What’s New: Vespa Cloud now supports backing up indexes from content nodes. The snapshot backups can be used for catastrophe restore of nodes. Read more.
Vespa Cloud: Fine-Grained maintenance controls
Vespa Cloud has always provided control over when and how application changes and Vespa upgrades are rolled out in production by the CD pipeline. In addition, Vespa Cloud does occasional OS upgrades as a background host level operation which is orchestrated but not rolled out by the CD pipeline.
We already see a need to run these processes more aggressively and anticipate that this trend will accelerate as capabilities similar to Claude Mythos become widely available. While this is necessary to maintain a strong security posture in the times ahead it has the potential to increase the impact from OS level maintenance on observed metrics, such as when these operations happen during peak traffic.
What’s new: Vespa Cloud now lets you control when these maintenance operations are allowed to happen in the same way as deployments are controlled. See the maintenance attribute in deployment.xml’s block-change tag.
Vespa Cloud: Voyage AI, OpenAI, and Mistral AI embedding integration
Embedding models are central to AI search, and it’s now simpler to use the most popular ones in Vespa Cloud.
What’s new: You can now save your API key in Vespa Cloud and invoke the embedding APIs of Voyage AI, OpenAI, and Mistral AI. These APIs can be invoked at document processing time (indexing), as well as query time. With Voyage AI and the voyage-4 model family, you can use the API for documents and a smaller, local model for queries, eliminating the need for an API call in the query path.
Read more in the Vespa embedding documentation for: Voyage AI, OpenAI, and Mistral AI.
Vespa Cloud: Custom resource tags
With Vespa Cloud Enclave, Vespa will provision resources in accounts owned by the customer. Many companies want to track these resources, e.g. for financial monitoring.
What’s New: Vespa now lets you declare custom resource tags in deployment.xml that will be applied on provisioned resources. The tag declarations can contain template variables such that resources can be tagged with e.g. the application they belong to. Read more.
Vespa skills for agents
Coding agents are good at working with Vespa applications. Giving them the relevant skills makes this even more efficient.
What’s new: We have released a collection of skills for agents working with Vespa applications, available here. This includes skills for working with application packages, feeding and queries, as well as migrating from ElasticSearch to Vespa. We run evaluations over these skills to ensure that they actually improve outcomes with current models.
A new query operator for text matching
To do lexical matching with an arbitrary input string in Vespa, you can use userInput(“my text”) in YQL.
This assumes that the text can control simple syntax for controlling the matching, such as “some-field:” to specify the field to match.
Sometimes, the text should just be interpreted as raw text with no such query syntax.
What’s new: Vespa now supports a new text() operator which interprets the argument text simply as raw text with no syntax.
When there’s no syntax, the text can only end up searching one field or fieldSet
and so the regular syntax can be used to specify the field: where my-field contains text(“my text”).
Read more.
Cluster-size independent configuration of relevance effort
Vespa has various parameters to set how much effort (CPU) should be spent on providing good results in a query. These parameters are specified as a value per content node, so if you want the total expenditure to stay constant when you change the number of content nodes, you must remember to update these parameters.
This is easy to forget, and of course impossible with autoscaling activated. What’s more, when new nodes are added to clusters, they will initially have less data than other nodes, but will get the same setting as nodes with a full share of data.
What’s new: Vespa now supports alternatives of these configuration parameters prefixed by “total”, which allows you to specify values across all the content nodes. Vespa will automatically calculate the right share for each node in the cluster group, including when nodes temporarily have less data than normally.
The new “total-” parameters are:
- NearestNeighbor and WeakAnd totalTargetHits: The minimum number of hits the query operator should produce
- Match-phase total-max-hits / ranking.matchphase.totalmaxhits
- First-phase total-keep-rank-count / ranking.totalKeepRankCount
- Second-phase total-rerank-count / ranking.secondPhase.totalRerankCount
Boolean array fields
Once developers move beyond the basics to really put the power of Vespa to work they often want to pack large amounts of dynamic metadata into documents, such as for example storing information about each document’s relationship to each zip code in the US. At scale the memory efficiency with such usage really matters.
What’s new: Vespa now lets you create arrays of bits fields: field my_bits type array<bool>.
Booleans can both be standalone or part of a struct type which is wrapped in an array.
Read more.
Match specific array elements
Arrays in documents can be searched both as attributes and text indexes. You can also match multiple struct values or text tokens of the same array element by using the sameElement operator. In some use cases, you also want to match a specific index in the array.
What’s new: Vespa now lets you specify the array index you want to match in queries: select … where my_bits[94085] = true.
You can also search for multiple indexes in the same query by using slightly more complicated syntax:
select … where my_array contains ({elementFilter:[33, 34]}sameElement(first_name contains "John", last_name contains "Doe")
See the elementFilter documentation. This is also supported in JSON queries by using an index attribute.
Search group pinning
When a content cluster has multiple groups, they will all have the same data, but their indexes will be slightly different since each node in each group has a different subset of the data written in a different order. This can lead to some inconsistency when a user is paging over a result set and hitting different groups.
What’s new: Vespa now lets you pin queries to a specific group to make pagination queries consistent. Read more.
In-memory document ids
Document ids in Vespa are only stored on disk only. This saves memory, but makes it impossible to retrieve the full ids of many documents really fast in queries and visiting.
What’s new: From Vespa 8.691 you can declare in the schema that document ids should reside in memory for fast access similar to attributes. Read more.
Near matching aware ranking
When using the near and onear query operators, the most intuitive ranking is using only the terms matching in the operator itself for rank scoring. Example:
Suppose near(term1, term2) matches document1 because of a single window where term1 and term2 appear close enough. If document1 contains term1 many additional times outside the valid proximity window, this is less relevant with respect to ranking.
What’s new: From Vespa 8.672, terms outside the match window are not considered in relevance calculations. Read more.
Detect ignored write operations
Content clusters can specify what documents they should receive in a document selection. Sending a document operation which is ignored by every cluster is not an error, but you may want to know.
What’s New: From Vespa 8.680, the document/v1 API includes a dedicated X-Vespa-Ignored-Operation HTTP response header. When an operation is ignored during routing (for example, because the target document no longer exists), this header is present and set to “true”. Read more in this issue.
Accessing the max first phase score in re-ranking
What’s new: firstPhaseMax is a new rank feature which exposes the rank score of the top scoring document locally on the node in second-phase ranking.
One usage of this is to enable dropping documents that score too low relative to the best-scoring document, by combining it with a rank-score-drop-limit.
Geo distance in grouping
What’s new: Grouping now lets you group by geo_distance:
all( group(fixedwidth(geo_distance(attribute(location), 63.4, 10.4).km, 10)) each(output(count())) )
Image Search demo
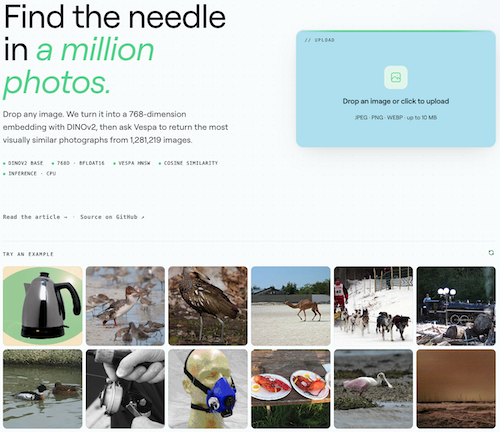
Try the image search demo to test how ranking profiles with different tensor precision in ranking affect results. Hint: binarized embeddings perform really well, read the report!
Vespa Learn
learn.vespa.ai is a self-paced course that teaches you how to build search, recommendation, and RAG applications with Vespa. You will go from zero to a working e-commerce search engine with hybrid retrieval and machine learning ranking, building it up one piece at a time across six modules.
What’s New on YouTube
- Multimodal Intelligence for Life Sciences on AWS (Webinar)
- The Personalization Problem in eCommerce AM (Webinar)
- The Personalization Problem in eCommerce EM (Webinar)
- The Relevance Problem in eCommerce (Webinar)
- Vespa Now: Q1 Product Update (Webinar)
- Zero Results Webinar
Find more videos in the @vespaai channel.
Blogs and ebooks
- Learn how Kleinanzeigen built a single system with user behavioral profiles alongside ads, WAND for fast inner-product retrieval over sparse attribute vectors, embedding-based ANN search, and click and search events processed as document updates: From Elasticsearch to Vespa: Rebuilding the Kleinanzeigen Homepage Feed.
- Scaling a Vespa Application: Feeding Fast and Furiously
- The Vespa Cloud Metrics Dashboard
- Using Large ONNX Models with External Data in Vespa Embedders
- Asymmetric Retrieval: Spend on Docs, Embed your Queries for Free
- How Metal AI Built an Agent-Driven Intelligence Platform on Vespa Cloud
- Build a High-Quality RAG App on Vespa Cloud in 15 Minutes
Upcoming events
- Commerce AI Summit London: June 3, London, UK. An executive-style event connecting retailers, brands, and AI solution providers.
- Berlin Buzzwords: June 7-9, Berlin, Germany. Europe’s leading conference for data infrastructure, search, and machine learning.
- Shoptalk Europe: June 9-11, Fira Gran Via, Barcelona. Europe’s home for retail innovation, bringing together 4,500+ trailblazers and 180+ speakers focused on AI and the future of commerce.
- Etail UK: June 16-17, Manchester, England. A leading eCommerce and retail conference focused on digital commerce strategy, customer experience, and AI-driven personalization for modern retail teams.
👉 Follow us on LinkedIn to stay in the loop on upcoming events, blog posts, and announcements.
Thanks for joining us in exploring the frontiers of AI with Vespa. Ready to take your projects to the next level? Deploy your application for free on Vespa Cloud today.