

BM25 is having a moment
Google search interest in “BM25” jumped about 5× in early August 2025. Around the same time, OpenAI’s models started volunteering BM25 noticeably more — gpt-4o named it on 12% of neutral retrieval prompts; gpt-4.1 and gpt-5-chat on 30–35%.1 The LIMIT paper showing dense embedding models flubbing trivial retrieval landed three weeks later.2
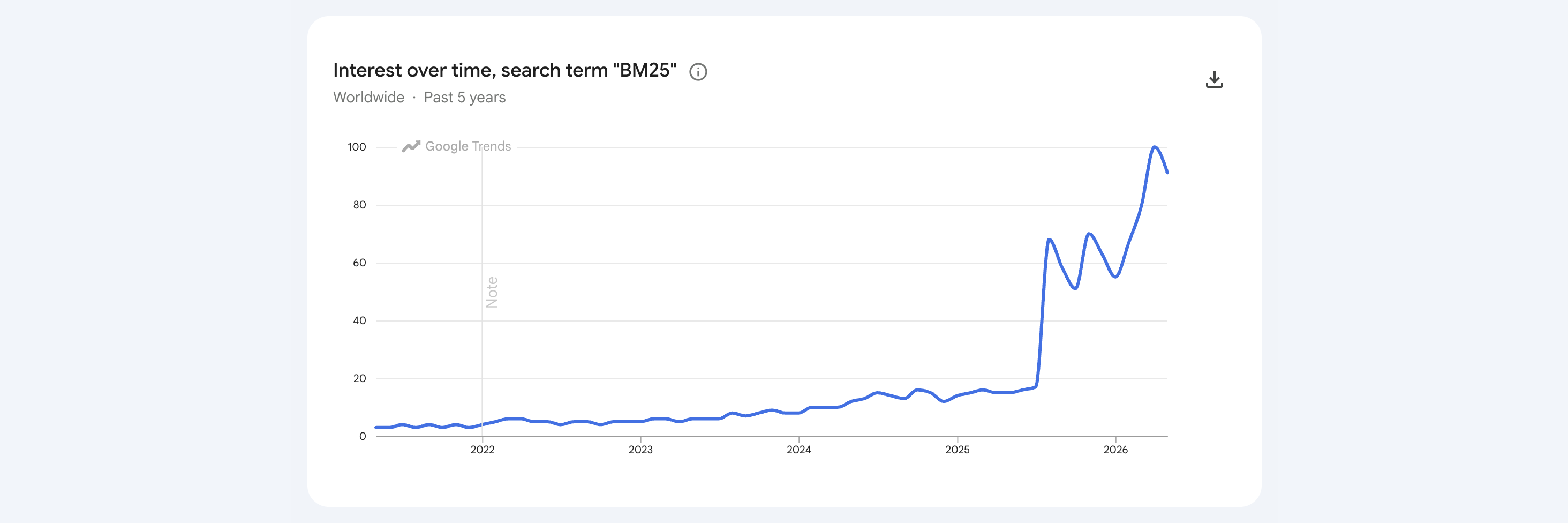
Whatever the reasons for this spike, the renewed interest in lexical search is likely a good thing. Lexical scoring is still a very robust baseline, especially in out-of-domain or zero-shot settings. And BM25 is a great baseline, but can we do better?
Building on BM25
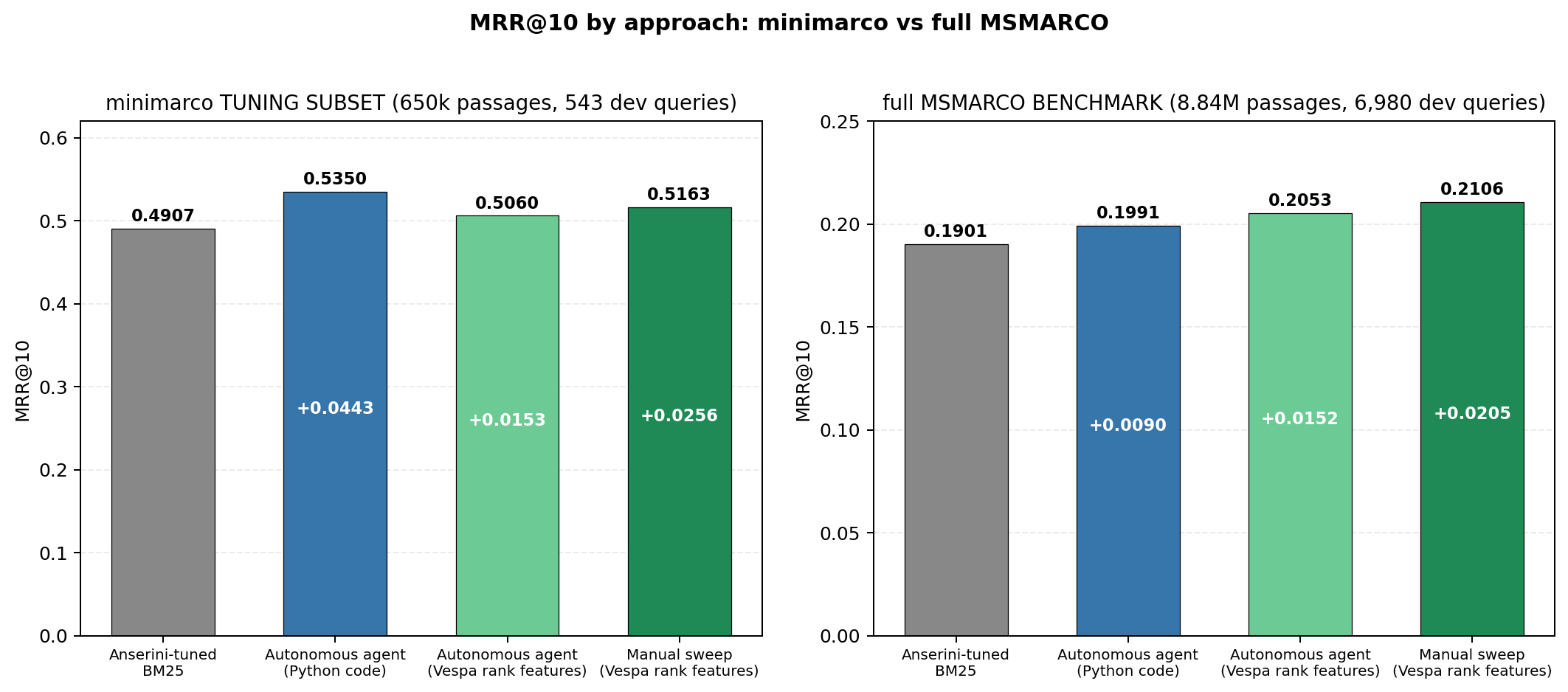
Earlier this month, Doug Turnbull published a really neat autoresearch experiment: let an LLM iterate on a Python BM25 reranker for 8 rounds and see how much better it gets on the MSMARCO3 passage-ranking benchmark. He randomly selects a 650k-passage slice he calls “minimarco”, and his agent is able to improve MRR@10 from 0.4913 → 0.5350 (+0.044). Very cool!
Of course, we wanted to try it for ourselves too. Our Vespa twist on it: instead of letting an LLM write arbitrary code in reranker.py, can
we get a similar lift while limiting our search space to existing Vespa rank features?
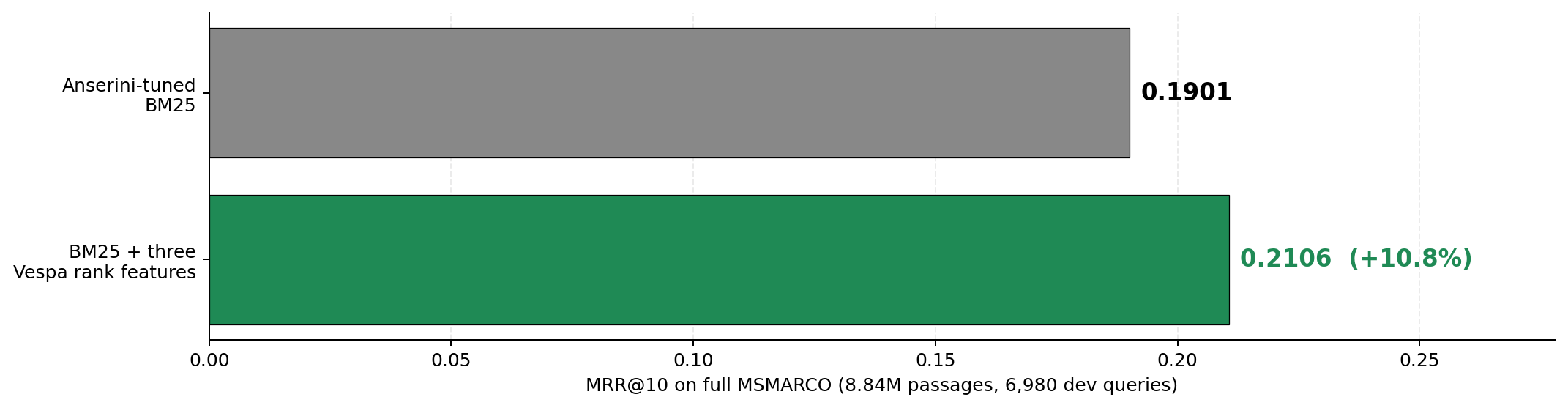
Spoiler: It turns out we can indeed get a significant improvement - and one that generalises better to the full dataset too. Let’s show you exactly how we did it!
Reproducing Doug’s setup
His recipe to create the “minimarco” subset is two lines of pandas:
collection = pd.read_csv("collection.tsv", sep="\t", names=["doc_id", "description"])
minimarco = collection.sample(n=650_000, random_state=42).reset_index(drop=True)
That trims the corpus from 8.84M MSMARCO passages down to 650k. Of the 6,980 dev queries, 543 still have a labeled relevant passage that landed in our random subset (the rest are unscoreable here, since their answer isn’t in the sample).
We loaded the 650k passages into Vespa with a minimal schema, setting the two BM25 hyperparameters to the Anserini-tuned MSMARCO defaults commonly used on this benchmark.
rank-profile bm25 inherits default {
first-phase {
expression: bm25(description)
}
rank-properties {
bm25(description).k1: 0.6 # Anserini-tuned MSMARCO defaults
bm25(description).b: 0.62
}
}
Running the 543 scoreable queries against this schema gives MRR@10 = 0.4907. Doug’s number is 0.4913 - close enough that the small gap could be explained by e.g. differences in stemming - the way his SearchArray’s Snowball vs. Vespa’s OpenNLP English4 normalize words. So we’re starting from the same baseline - now let’s see what we can add!
The three tweaks that moved the needle
We had time to try about 20 things in an afternoon. Three of them robustly survived 10 paired rotations against the running baseline — meaning each round we drew 10 different random subsets of the dev queries, evaluated both the candidate and the current best config on the same queries, and only kept changes that beat the previous best across all 10 subsets.
#1: Stopword-limit on weakAnd
Vespa’s text()
operator searches its tokens with a
weakAnd by default,
which has a built-in document-frequency (DF) based stopword filter. We set it extremely aggressively here -
ranking.matching.weakand.stopwordLimit = 0.05, which means Vespa automatically drops query terms that appear in more than 5% of docs. No need to create a hand-curated
list. This makes our queries faster too - the high-DF terms have the longest posting lists,
so skipping them more than halved our wall-clock latency.5
| stopword-limit | Δ MRR@10 paired |
|---|---|
| off | - |
| 0.05 | +0.0136 |
| 0.02 | -0.0088 |
At 0.02 the filter has become way too aggressive and starts dropping important content words.
#2: nativeProximity
The nativeProximity feature is a continuous proximity score that rewards docs
where the matched query terms are close together. Doug’s agent did something
loosely similar by writing code to score based on adjacent-bigram phrase term frequencies. We just pulled it from
Vespa’s rank-feature catalog:
rank-profile lexical inherits default {
inputs {
query(w_prox) double: 0.0 # query-time tunable weight
}
first-phase {
expression: bm25(description) + query(w_prox) * nativeProximity
}
...
}
Our sweep results: w_prox = 10 is a good value here, with a wide plateau (8-14 are all within
noise). Wide plateaus like this are a positive sign that the gain is real, not a noise-fitted spike.
#3: fieldMatch.earliness
fieldMatch(description).earliness is a feature that rewards matches near the start
of the field. A match is often a stronger signal if it appears early —
writing tends to introduce its main topic up front (headline, abstract,
summary). w_fm_early = 8 peaks at +0.0189 paired over the proximity-only anchor.
Iterating fast — and validating more thoroughly
A nice property of doing this in Vespa: every “did this weight help?” question is just a query parameter against the index which is already built when we fed the data. ~33 ms per query, ~0.4 s for a 109-query training eval, ~22 s to test one weight value across 10 paired rotations. It stayed fast because we weren’t paying for re-indexing or re-scoring of every query/document pair; we were just passing numbers in an HTTP body.
That speed is also what lets us validate each candidate more thoroughly. The eval set is tiny - 109 training queries per rotation - so any single split is noisy. Try 20 weight combos against one split, and one or two will look like wins by pure luck (the paired noise is ±0.014, bigger than the gains we’re chasing). Our fix is to test each candidate across many different random splits and keep only what holds up everywhere. That’s painful if every eval is an LLM call or a re-index, but nearly free when it’s just another query - so we ran 10 rotations per weight. That’s the difference between a real +0.005 and a lucky one, and possibly a big reason the single-split agent loop overfits: not enough independent looks at the data before committing to a change.
Our best recipe from this run
bm25 + 10·nativeProximity + 8·fieldMatch.earliness + sw=0.05.
On the full 543-query minimarco dev set: MRR@10 = 0.5163 (+0.0256
over BM25 = 0.4907). Doug’s agent gets 0.5350 (+0.044), so it’s ahead of us by
about 0.019 in absolute terms.
What happens on full MSMARCO?
First, what these numbers mean: minimarco is also where we tuned, so the minimarco column is in-sample. The 10-rotation gate guards against getting lucky on a single split — but not against fitting the 543-query subset as a whole. The full 8.84M-doc corpus is the real out-of-sample test, so that’s the column to trust for generalization.
Doug honestly flags this in his post: his agent’s gains don’t generalize well. On the full 8.84M-doc benchmark, his round-8 reranker scores 0.1991 vs BM25’s 0.1897 - only +0.0094 of the original +0.044 improvement survives. We tried our configurations on the full corpus too:
How well do our results transfer to the full dataset?
| minimarco | full MSMARCO | retention | |
|---|---|---|---|
| BM25 | 0.4907 | 0.1901 | N/A |
| Free-form-Python agent | 0.5350 (+0.044) | 0.1991 (+0.009) | 21% |
| Our agent (Vespa rank features) | 0.5060 (+0.015) | 0.2053 (+0.015) | 99% |
| Our manual sweep (Vespa rank features) | 0.5163 (+0.026) | 0.2106 (+0.021) | 80% |
Most of our minimarco lift from both attempts survives the jump to full MSMARCO - these are all features with generalizable signal, re-tuning the weights on the full dataset might squeeze out more.
Why this gap?
- An LLM with free-form Python has more rope. By round 8 the agent
hard-codes a stopword list containing
vacatandmedicinand a conditional liketoks[1] not in ("can", "invent"). Those help on the minimarco subset; they don’t help anywhere else - it’s overfitting. - We’re using rank features that IR researchers and Vespa engineers have
already validated as carrying generalizable signal. We didn’t have to invent
nativeProximityfrom scratch here. The LLM has to rediscover something like it from termfreq primitives within a single round, which is harder. - The LLM writing arbitrary python does have the freedom to invent completely novel techniques, but on this extremely well-studied dataset we can perhaps consider it somewhat unlikely.
Our own “autoresearch” loop
In our results, we refer to our first experiment as “manual”, but it’s 2026 - that sweep wasn’t a human hand-typing weights either. We used a coding assistant (Claude Code) to do the exploration, with us steering at a high level and holding it to the 10-rotation rule. So really, it’s LLM-vs-LLM - what changes between the runs is the search space and how rigorously each one accepts a change, not human vs machine.
After the quick sweep we wondered: would a fully autonomous LLM agent like Doug’s,
inside our constrained search space, generalize any better? We built a small loop
(same eval_margin = 0.002, same rotating seeds, same gpt-5.5 model with xhigh
reasoning) that edits the Vespa first-phase rank expression instead of
reranker.py. The key difference from Doug’s setup: a change is accepted only if it
clears the same 10-rotation paired-robustness check our manual sweep uses — so the
agent and the sweep differ only in search space and autonomous-vs-steered, not in how
rigorously a change is accepted. ~700 lines of Python, $6 of OpenAI spend, 30
minutes.
In our run the agent found two valuable features — nativeProximity and
fieldMatch.earliness, the same pair the manual sweep landed on — and reached
MRR@10 = 0.2053 on full MSMARCO (+0.0152): about 99% retention of its
minimarco lift, even higher than the manual sweep’s 80% and far above the
free-form-Python run’s 21%. Its absolute score sits a touch below the manual sweep’s
(0.2053 vs 0.2106) because it didn’t add the stopwordLimit matching-side lever in
this run — but almost all of the lift it did find carried over. That’s the
constrained search space doing its job: the agent can’t encode token-specific tactics
like a hard-coded stopword list, so its ceiling on overfitting is lower.
Our final config
body = {
"yql": "select doc_id from passage where description contains ({language:'en'}text(@q))",
"q": user_query_text,
"ranking.profile": "lexical",
"hits": 10,
"language": "en",
"input.query(w_prox)": 10.0,
"input.query(w_fm_early)": 8.0,
"ranking.matching.weakand.stopwordLimit": 0.05,
}
This is all that’s needed to use these features. Just a simple linear combination of well-known signals, and a demonstration that there is much more tuning potential to be had from lexical search too. And your coding agent already knows how to do it!
BM25 has served the IR community well for 30+ years, and we don’t think it’s going anywhere. But Vespa has all the pieces in place to go beyond the baseline - with lexical signals, advanced multi-vector ranking and more, and we keep working to raise the bar. Subscribe to the newsletter if you’d like to hear about it!
Going further
The full code for this experiment — the Vespa app, the
paired-rotation sweep harness, and the LLM agent loop, with a step-by-step
reproduction guide — is at vespaai-playground/msmarco-bm25-autoresearch.
To actually give your coding agent the Vespa knowledge to quickly succeed, there’s an official skills pack for Claude Code / Codex / Cursor / Gemini CLI: github.com/vespaai-playground/skills — which includes schema authoring, rank features, query building, etc.
Want to go even further? A weighted sum of three features is still on the simple end of the spectrum. The next step is to stop hand-weighting and let a model learn the best combination on your dataset: the RAG Blueprint collects ~190 lexical and semantic match/rank features and trains a GBDT (LightGBM) model to combine them — a more advanced version of what we did by hand here, and it mixes BM25-style lexical signals with vector-semantic ones.
Want to play with Vespa? Start with the free trial or pull the vespaengine/vespa container.
Notes
Come hang out in Vespa Slack or Discord if you want to chat ranking features or compare notes on retrieval evals. Thanks to Doug for publishing the experiment!
-
We asked the three models the same six neutral retrieval prompts, 10 reps each. BM25 mention rates: gpt-4o 12%, gpt-4.1 30%, gpt-5-chat 35%. The shift happens at gpt-4.1, not GPT-5. ↩
-
On the Theoretical Limitations of Embedding-Based Retrieval, Google DeepMind & Johns Hopkins, arXiv:2508.21038 (Aug 2025). LIMIT is a benchmark of deliberately simple retrieval queries — top embedding models scored under 20% recall@100 on queries as simple as “who likes apples?”. ↩
-
MSMARCO is a widely-used passage-ranking benchmark — 8.84M short passages and a dev set of 7,437 qrels (query + relevant-passage-ID pairs collected by human annotators). MRR@10 = mean reciprocal rank of the first relevant passage in each query’s top-10 results, averaged across queries (0 if no relevant passage in top-10). ↩
-
Vespa also ships Lucene Linguistics as an alternative for stemming, tokenization, and language detection — we stuck with the default OpenNLP here and did no tuning of linguistics. ↩
-
Tripling the query performance of lexical search takes a complementary latency-and-cost-focused approach —
stopwordLimit=0.6combined withadjust-targetandfilter-thresholdfor 3–11× speedup with negligible quality change. We pushedstopwordLimitto the aggressive end of the range for quality, since on MSMARCO the benefit comes from setting the parameter low enough to exclude common question words — about 72% of dev queries are question-style (“what is X”, “how do Y”), and at0.6those terms are not excluded. On keyword-heavy workloads the optimum would be higher — re-measure on your own query distribution before adopting. Query rewriting on lexical queries is likely stronger, but we didn’t do it here. ↩