
In the previous update, we mentioned Better Tensor formats, AWS PrivateLink, Autoscaling, Data Plane Access Control as well as Container and Content Node Performance.
We also want to thank you for your PRs! In particular (see below), most of the new pyvespa features were submitted from non-Vespa Team members - thank you! We are grateful for the contributions, please do keep those PRs coming!
We’re excited to share the following updates:
GPU-accelerated ML inference
In machine learning, computing model inference is a good candidate for being accelerated by special-purpose hardware, such as GPUs. Vespa supports evaluating multiple types of machine-learned models in stateless containers, e.g., TensorFlow, ONNX, XGBoost, and LightGBM models. For some use cases, using a GPU makes it possible to perform model inference with higher performance, and at a lower price point, when compared to using a general-purpose CPU.
The Vespa Team is announcing support for GPU-accelerated ONNX model inference in Vespa, including support for GPU instances in Vespa Cloud - read more.
Vespa Cloud: BCP-aware autoscaling
As part of a business continuity plan (BCP), applications are often deployed to multiple zones so the system has ready, on-hand capacity to absorb traffic should a zone fail. Using autoscaling in Vespa Cloud sets aside resources in each zone to handle an equal share of the traffic from the other zones in case one of them goes down - e.g., it assumes a flat BCP structure.
This is not always how applications wish to structure their BCP traffic shifting though - so applications can now define their BCP structure explicitly using the BCP tag in deployment.xml. Also, during a BCP event, when it is acceptable to have some delay until capacity is ready, you can set a deadline until another zone must have sufficient capacity to accept the overload; permitting delays like this allows autoscaling to save resources.
Vespa for e-commerce
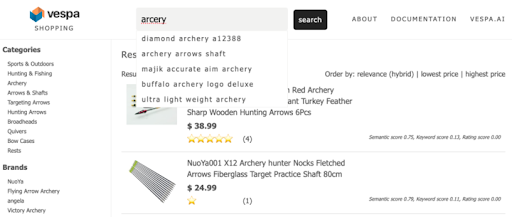
Vespa is often used in e-commerce applications. We have added exciting features to the shopping sample application:
- Use NLP techniques to generate query suggestions from the index content based on spaCy and en_core_web_sm.
- Use the fuzzy query operator and prefix search for great query suggestions - this handles misspelled words and creates much better suggestions than prefix search alone.
- For query-contextualized navigation, the order in which the groups are rendered is determined by both counting and the relevance of the hits.
- Native embedders are used to map the textual query and document representations into dense high-dimensional vectors, which are used for semantic search - see embeddings. The application uses an open-source embedding model, and inference is performed using stateless model evaluation, during document and query processing.
- Hybrid ranking / Vector search: The default retrieval uses approximate nearest neighbor search in combination with traditional lexical matching. The keyword and vector matching is constrained by the filters such as brand, price, or category.
Read more about these and other Vespa features used in use-case-shopping.
Optimizations and features
- Vespa supports multiple schemas with multiple fields. This can amount to thousands of fields. Vespa’s index structures are built for real-time, high-throughput reads and writes. With Vespa 8.140, the static memory usage is cut by 75%, depending on field types. Find more details in #26350.
- Extracting documents is made easier using vespa visit in the Vespa CLI. This makes it easier to clone applications with data to/from self-hosted/Vespa Cloud applications.
pyvespa
Pyvespa – the Vespa Python experimentation library – is now split into two repositories: pyvespa and learntorank. Update learntorank is deprecated this is for better separation of the python API and to facilitate prototyping and experimentation for data scientists. Pyvespa 0.32 has been released with many new features for fields and ranking; see the release notes.
This time, most of the new pyvespa features are submitted from non-Vespa Team members! We are grateful for – and welcome more – contributions. Keep those PRs coming!
GCP Private Service Connect in Vespa Cloud
In January, we announced AWS Private Link. We are now happy to announce support for GCP Private Service Connect in Vespa Cloud. With this service, you can set up private endpoint services on your application clusters in Google Cloud, providing clients with safe, non-public access to the application!
In addition, Vespa Cloud supports deployment to both AWS and GCP regions in the same application deployment. This support simplifies migration projects, optimizes costs, adds cloud provider redundancy, and reduces complexity. We’ve made adopting Vespa Cloud into your processes easy!
- Use the guide to clone applications, and you can easily roam the different environments, including self-hosted solutions.
- Use Vespa Cloud’s built-in cloud migration support to take out project risk.
-
And use the Vespa toolbox for deployment and migrations to make the process smooth and (almost) without work. Check out vespa-documentation-search for an example:
<prod> <region>aws-us-east-1c</region> <delay minutes="10" /> <test>aws-us-east-1c</test> <region>aws-eu-west-1a</region> <region>gcp-us-central1-f</region> </prod>
Blog posts since the last newsletter
- GPU-accelerated ML inference in Vespa Cloud
- Improving Search Ranking with Few-Shot Prompting of LLMs
Thanks for reading! Try out Vespa on Vespa Cloud or grab the latest release at docs.vespa.ai/en/learn/releases.html and run it yourself! 😀