

Photo by Thought Catalog on Unsplash
This blog post is a hands-on guide to connecting LangChain with Vespa streaming mode to build cost-efficient RAG applications over naturally sharded data.
You can read more about Vespa vector streaming search in these blog posts:
- Announcing vector streaming search: AI assistants at scale without breaking the bank
- Yahoo Mail turns to Vespa to do RAG at scale
- Hands-On RAG guide for personal data with Vespa and LLamaIndex
This blog post is also available as a runnable notebook where you can have this app up and running on
Vespa Cloud in minutes
(
![]() )
)
TLDR; Vespa streaming mode for partitioned data
Vespa’s streaming search solution enables you to integrate a user ID (or any sharding key) into the Vespa document ID. This setup allows Vespa to efficiently group each user’s data on a small set of nodes and the same disk chunk. Streaming mode enables low latency searches on a user’s data without keeping data in memory.
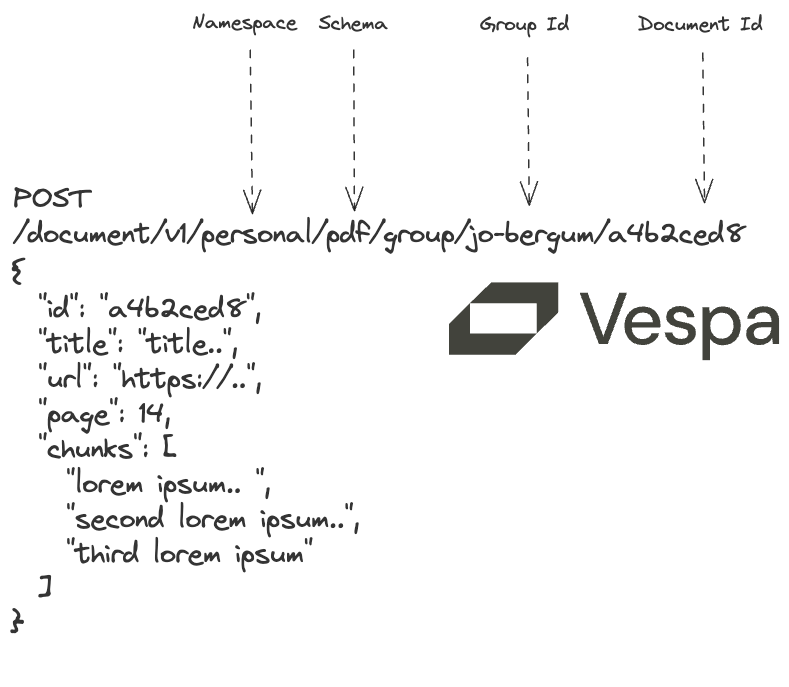
The key benefits of Vespa streaming mode:
- Eliminating compromises in precision introduced by approximate algorithms
- Achieve significantly higher write throughput, thanks to the absence of index builds required for supporting approximate search.
- Optimize efficiency by storing documents, including tensors and data, on disk, benefiting from the cost-effective economics of storage tiers.
- Storage cost is the primary cost driver of Vespa streaming mode; no data is in memory. Avoiding memory usage lowers deployment costs significantly.
Connecting LangChain Retriever with Vespa for Context Retrieval from PDF Documents
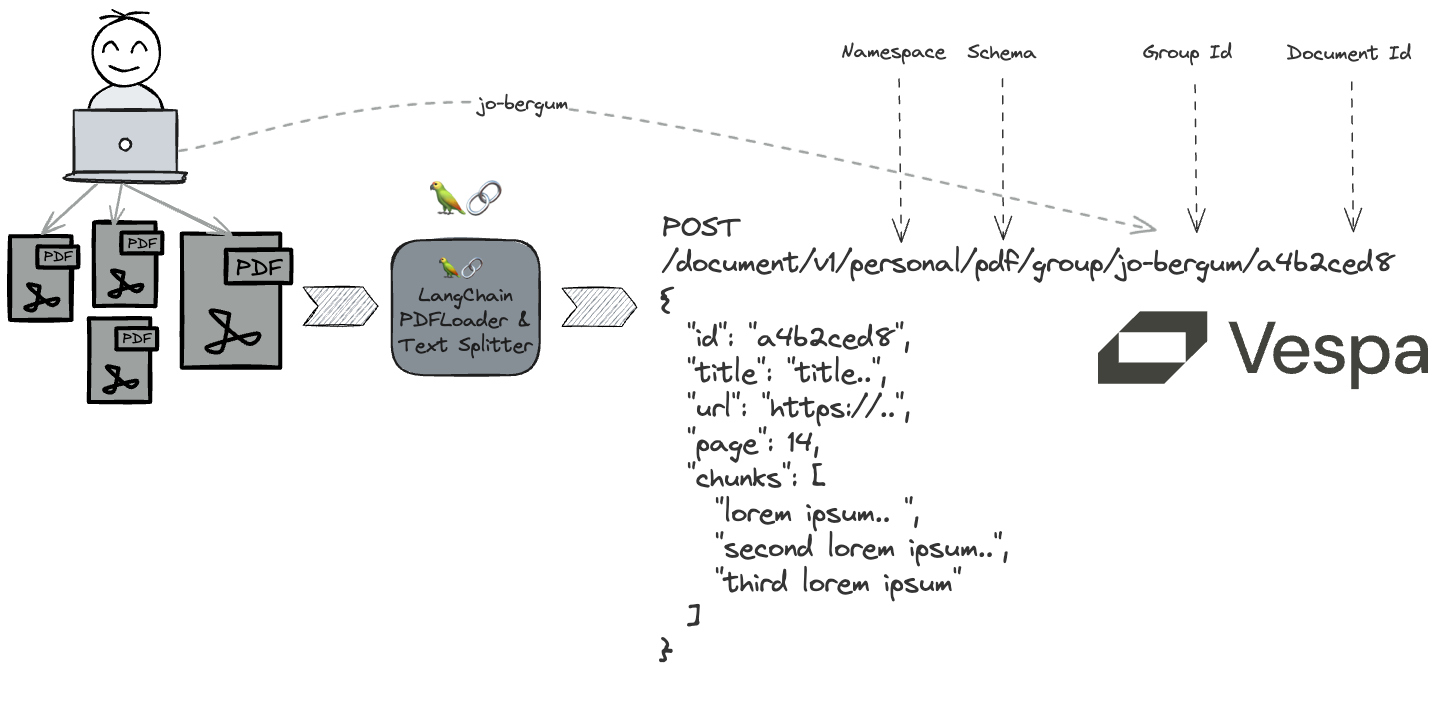
In this blog post, we seamlessly integrate a custom LangChain retriever with a Vespa app, leveraging Vespa’s streaming mode to extract meaningful context from PDF documents.
The workflow:
- Define and deploy a Vespa application package using PyVespa.
- Utilize LangChain PDF Loaders to download and parse PDF files.
- Leverage LangChain Document Transformers to convert each PDF page into multiple text chunks.
- Feed the transformer representation to the running Vespa instance
- Employ Vespa’s built-in embedder functionality (using an open-source embedding model) for embedding the text chunks per page, resulting in a multi-vector representation.
- Develop a custom Retriever to enable seamless retrieval for any unstructured text query.
Let’s get started! First, install dependencies:
!pip3 install -U pyvespa langchain pypdf openai
Sample data
We love ColBERT, so we will use a few COlBERT-related papers as examples of PDFs:
def sample_pdfs():
return [
{
"title": "ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction",
"url": "https://arxiv.org/pdf/2112.01488.pdf",
"authors": "Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, Matei Zaharia"
},
{
"title": "ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT",
"url": "https://arxiv.org/pdf/2004.12832.pdf",
"authors": "Omar Khattab, Matei Zaharia"
},
{
"title": "On Approximate Nearest Neighbour Selection for Multi-Stage Dense Retrieval",
"url": "https://arxiv.org/pdf/2108.11480.pdf",
"authors": "Craig Macdonald, Nicola Tonellotto"
},
{
"title": "A Study on Token Pruning for ColBERT",
"url": "https://arxiv.org/pdf/2112.06540.pdf",
"authors": "Carlos Lassance, Maroua Maachou, Joohee Park, Stéphane Clinchant"
},
{
"title": "Pseudo-Relevance Feedback for Multiple Representation Dense Retrieval",
"url": "https://arxiv.org/pdf/2106.11251.pdf",
"authors": "Xiao Wang, Craig Macdonald, Nicola Tonellotto, Iadh Ounis"
}
]
Definining the Vespa application
PyVespa helps us build the Vespa application package. A Vespa application package consists of configuration files, schemas, models, and code (plugins).
First, we define a Vespa schema with the fields we want to store and their type.
from vespa.package import Schema, Document, Field, FieldSet, HNSW
pdf_schema = Schema(
name="pdf",
mode="streaming",
document=Document(
fields=[
Field(name="id", type="string", indexing=["summary", "index"]),
Field(name="title", type="string", indexing=["summary", "index"]),
Field(name="url", type="string", indexing=["summary", "index"]),
Field(name="authors", type="array<string>", indexing=["summary", "index"]),
Field(name="page", type="int", indexing=["summary", "index"]),
Field(name="metadata", type="map<string,string>", indexing=["summary", "index"]),
Field(name="chunks", type="array<string>", indexing=["summary", "index"]),
Field(name="embedding", type="tensor<bfloat16>(chunk{}, x[384])",
indexing=["input chunks", "embed e5", "attribute", "index"],
ann=HNSW(distance_metric="angular"),
is_document_field=False
)
],
),
fieldsets=[
FieldSet(name = "default", fields = ["chunks", "title"])
]
)
The above defines our pdf schema using mode streaming. Most fields are straightforward, but take notes of:
metadatausingmap<string,string>- here we can store and match over page-level metadata extracted by the PDF parser.chunksusingarray<string>, these are the text chunks that we use LangChain document transformers for- The
embeddingfield of typetensor<bfloat16>(chunk{},x[384])allows us to store and search the 384-dimensional embeddings per chunk in the same Vespa document
The observant reader might have noticed the e5 argument to the embed expression in the above embedding field.
The e5 argument references a component of the type hugging-face-embedder.
We configure the application package and its name with the pdf schema and the e5 embedder component.
from vespa.package import ApplicationPackage, Component, Parameter
vespa_app_name = "pdfs"
vespa_application_package = ApplicationPackage(
name=vespa_app_name,
schema=[pdf_schema],
components=[Component(id="e5", type="hugging-face-embedder",
parameters=[
Parameter("transformer-model", {"url": "https://github.com/vespa-engine/sample-apps/raw/master/simple-semantic-search/model/e5-small-v2-int8.onnx"}),
Parameter("tokenizer-model", {"url": "https://raw.githubusercontent.com/vespa-engine/sample-apps/master/simple-semantic-search/model/tokenizer.json"})
]
)]
)
In the last step, we configure ranking by adding rank-profile’s to the schema. Vespa supports phased ranking and has a rich set of built-in rank-features, including many text-matching features such as:
- BM25.
- nativeRank and many more.
Users can also define custom functions using ranking expressions. The following defines a hybrid Vespa ranking profile.
from vespa.package import RankProfile, Function, FirstPhaseRanking
semantic = RankProfile(
name="hybrid",
inputs=[("query(q)", "tensor<float>(x[384])")],
functions=[Function(
name="similarities",
expression="cosine_similarity(query(q), attribute(embedding),x)"
)],
first_phase=FirstPhaseRanking(
expression="nativeRank(title) + nativeRank(chunks) + reduce(similarities, max, chunk)",
rank_score_drop_limit=0.0
),
match_features=["closest(embedding)", "similarities", "nativeRank(chunks)", "nativeRank(title)", "elementSimilarity(chunks)"]
)
pdf_schema.add_rank_profile(semantic)
The hybrid rank-profile above defines the query input embedding type and a similarities function that
uses a Vespa tensor compute function that calculates
the cosine similarity between all the chunk embeddings and the query embedding. The profile only defines a single ranking phase using a linear combination of multiple features.
Using match-features, Vespa returns selected features along with the returned hits for a query.
Deploy the application to Vespa Cloud
With the configured application, we can deploy it to Vespa Cloud. It is also possible to deploy the app using docker; see the Hybrid Search - Quickstart guide for an example of deploying it to a local docker container.
Deploy to Vespa
PyVespa supports deploying apps to the development zone,
see the notebook for details on credentials and onboarding.
from vespa.deployment import VespaCloud
def read_secret():
"""Read the API key from the environment variable. This is
only used for CI/CD purposes."""
t = os.getenv("VESPA_TEAM_API_KEY")
if t:
return t.replace(r"\n", "\n")
else:
return t
vespa_cloud = VespaCloud(
tenant=os.environ["TENANT_NAME"],
application=vespa_app_name,
key_content=read_secret() if read_secret() else None,
key_location=api_key_path,
application_package=vespa_application_package)
Now deploy the app to the Vespa dev zone.
The first deployment of a new application typically takes 2 minutes until the endpoint is up:
from vespa.application import Vespa
app:Vespa = vespa_cloud.deploy()
Deployment started in run 1 of dev-aws-us-east-1c for samples.pdfs. This may take a few minutes the first time.
INFO [10:44:23] Deploying platform version 8.268.18 and application dev build 1 for dev-aws-us-east-1c of default ...
INFO [10:46:21] Found endpoints:
INFO [10:46:21] - dev.aws-us-east-1c
INFO [10:46:21] |-- https://eb49e7c6.bfbdb4fd.z.vespa-app.cloud/ (cluster 'pdfs_container')
INFO [10:46:22] Installation succeeded!
Using mTLS (key,cert) Authentication against endpoint https://eb49e7c6.bfbdb4fd.z.vespa-app.cloud//ApplicationStatus
Processing PDFs with LangChain
LangChain has a rich set of [document loaders]https://python.langchain.com/v0.1/docs/modules/data_connection/document_loaders/) that can be used to load and process various file formats. This guide uses the PyPDFLoader.
We also want to split the extracted text into chunks using a text splitter. Most text embedding models have limited input lengths (typically less than 512 language model tokens), so splitting the text into multiple chunks that fit into the context limit of the embedding model is a common technique to overcome length limitations (and also improve the effectiveness).
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1024, #chars, not llm tokens
chunk_overlap = 0,
length_function = len,
is_separator_regex = False,
)
The following iterates over the sample_pdfs and performs the following:
- Load the URL and extract the text into pages. A page is the retrievable unit we will use in Vespa
- For each page, use the text splitter to split the text into chunks. The chunks are represented as an
array<string>in the Vespa schema - Create the page-level Vespa
fields
import hashlib
import unicodedata
def remove_control_characters(s):
return "".join(ch for ch in s if unicodedata.category(ch)[0]!="C")
my_docs_to_feed = []
for pdf in sample_pdfs():
url = pdf['url']
loader = PyPDFLoader(url)
pages = loader.load_and_split()
for index, page in enumerate(pages):
source = page.metadata['source']
chunks = text_splitter.transform_documents([page])
text_chunks = [chunk.page_content for chunk in chunks]
text_chunks = [remove_control_characters(chunk) for chunk in text_chunks]
page_number = index + 1
vespa_id = f"{url}#{page_number}"
hash_value = hashlib.sha1(vespa_id.encode()).hexdigest()
fields = {
"title" : pdf['title'],
"url" : url,
"page": page_number,
"id": hash_value,
"authors": [a.strip() for a in pdf['authors'].split(",")],
"chunks": text_chunks,
"metadata": page.metadata
}
my_docs_to_feed.append(fields)
Now that we have parsed the input PDFs and created a list of pages that we want to add to Vespa, we must format the
list into the format that PyVespa accepts. Notice the fields, id and groupname keys. The groupname is the
key that is used to shard and co-locate the data and is only relevant when using Vespa with streaming mode.
from typing import Iterable
def vespa_feed(user:str) -> Iterable[dict]:
for doc in my_docs_to_feed:
yield {
"fields": doc,
"id": doc["id"],
"groupname": user
}
Now, we can feed to the Vespa instance (app) using the feed_iterable API, using the generator function above as input
with a custom callback function. Vespa also performs embedding inference during this step using the built-in Vespa embedding functionality.
from vespa.io import VespaResponse
def callback(response:VespaResponse, id:str):
if not response.is_successful():
print(f"Document {id} failed to feed with status code {response.status_code}, url={response.url} response={response.json}")
app.feed_iterable(schema="pdf", iter=vespa_feed("jo-bergum"), namespace="personal", callback=callback)
Notice the schema and namespace - PyVespa translates these to Vespa document API
requests, illustrated below.
Querying data
Now, we can also query our data. With streaming mode,
we must pass the groupname parameter, or the request will fail with an error.
The query request uses the Vespa Query API and the Vespa.query() function
supports passing any of the Vespa query API parameters.
Read more about querying Vespa in:
Sample query request for why is colbert effective? for the user jo-bergum:
from vespa.io import VespaQueryResponse
import json
response:VespaQueryResponse = app.query(
yql="select id,title,page,chunks from pdf where userQuery() or ({targetHits:10}nearestNeighbor(embedding,q))",
groupname="jo-bergum",
ranking="hybrid",
query="why is colbert effective?",
body={
"presentation.format.tensors": "short-value",
"input.query(q)": "embed(e5, \"why is colbert effective?\")",
}
)
assert(response.is_successful())
print(json.dumps(response.hits[0], indent=2))
{
"id": "id:personal:pdf:g=jo-bergum:a4b2ced87807ee9cb0325b7a1c64a070d05a31f7",
"relevance": 1.1412738851962692,
"source": "pdfs_content.pdf",
"fields": {
"matchfeatures": {
"closest(embedding)": {
"0": 1.0
},
"elementSimilarity(chunks)": 0.5006379585326953,
"nativeRank(chunks)": 0.15642522855051508,
"nativeRank(title)": 0.1341324233922751,
"similarities": {
"1": 0.7731813192367554,
"2": 0.8196794986724854,
"3": 0.796222984790802,
"4": 0.7699441909790039,
"0": 0.850716233253479
}
},
"id": "a4b2ced87807ee9cb0325b7a1c64a070d05a31f7",
"title": "ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT",
"page": 9,
"chunks": [
"Sq,d:=\u00d5i\u2208[|Eq|]maxj\u2208[|Ed|]Eqi\u00b7ETdj(3)ColBERT is di\ufb00erentiable end-to-end. We /f_ine-tune the BERTencoders and train from scratch the additional parameters (i.e., thelinear layer and the [Q] and [D] markers\u2019 embeddings) using theAdam [ 16] optimizer. Notice that our interaction mechanism hasno trainable parameters. Given a triple \u27e8q,d+,d\u2212\u27e9with query q,positive document d+and negative document d\u2212, ColBERT is usedto produce a score for each document individually and is optimizedvia pairwise so/f_tmax cross-entropy loss over the computed scoresofd+andd\u2212.3.4 O\ufb00line Indexing: Computing & StoringDocument EmbeddingsBy design, ColBERT isolates almost all of the computations betweenqueries and documents, largely to enable pre-computing documentrepresentations o\ufb04ine. At a high level, our indexing procedure isstraight-forward: we proceed over the documents in the collectionin batches, running our document encoder fDon each batch andstoring the output embeddings per document. Although indexing",
"a set of documents is an o\ufb04ine process, we incorporate a fewsimple optimizations for enhancing the throughput of indexing. Aswe show in \u00a74.5, these optimizations can considerably reduce theo\ufb04ine cost of indexing.To begin with, we exploit multiple GPUs, if available, for fasterencoding of batches of documents in parallel. When batching, wepad all documents to the maximum length of a document withinthe batch.3To make capping the sequence length on a per-batchbasis more e\ufb00ective, our indexer proceeds through documents ingroups of B(e.g., B=100,000) documents. It sorts these documentsby length and then feeds batches of b(e.g., b=128) documents ofcomparable length through our encoder. /T_his length-based bucket-ing is sometimes refered to as a BucketIterator in some libraries(e.g., allenNLP). Lastly, while most computations occur on the GPU,we found that a non-trivial portion of the indexing time is spent onpre-processing the text sequences, primarily BERT\u2019s WordPiece to-",
"kenization. Exploiting that these operations are independent acrossdocuments in a batch, we parallelize the pre-processing across theavailable CPU cores.Once the document representations are produced, they are savedto disk using 32-bit or 16-bit values to represent each dimension.As we describe in \u00a73.5 and 3.6, these representations are eithersimply loaded from disk for ranking or are subsequently indexedfor vector-similarity search, respectively.3.5 Top- kRe-ranking with ColBERTRecall that ColBERT can be used for re-ranking the output of an-other retrieval model, typically a term-based model, or directlyfor end-to-end retrieval from a document collection. In this sec-tion, we discuss how we use ColBERT for ranking a small set ofk(e.g., k=1000) documents given a query q. Since kis small, werely on batch computations to exhaustively score each document",
"3/T_he public BERT implementations we saw simply pad to a pre-de/f_ined length.(unlike our approach in \u00a73.6). To begin with, our query serving sub-system loads the indexed documents representations into memory,representing each document as a matrix of embeddings.Given a query q, we compute its bag of contextualized embed-dings Eq(Equation 1) and, concurrently, gather the document repre-sentations into a 3-dimensional tensor Dconsisting of kdocumentmatrices. We pad the kdocuments to their maximum length tofacilitate batched operations, and move the tensor Dto the GPU\u2019smemory. On the GPU, we compute a batch dot-product of EqandD, possibly over multiple mini-batches. /T_he output materializes a3-dimensional tensor that is a collection of cross-match matricesbetween qand each document. To compute the score of each docu-ment, we reduce its matrix across document terms via a max-pool(i.e., representing an exhaustive implementation of our MaxSim",
"computation) and reduce across query terms via a summation. Fi-nally, we sort the kdocuments by their total scores."
]
}
}
Notice the returned matchfeatures field, which returns the features we asked for in the hybrid rank-profile. This includes
the similarities features, that returns all the cosine similarities for all the chunks in the retrieved page.
LangChain Retriever
We use the LangChain Retriever interface so that we can connect our Vespa app with the flexibility and power of the LangChain LLM framework.
A retriever is an interface that returns documents given an unstructured query. It is more general than a vector store. A retriever does not need to be able to store documents, only to return (or retrieve) them. Vector stores can be used as the backbone of a retriever, but there are other types of retrievers as well.
The retriever interface fits perfectly with Vespa, as Vespa can support a wide range of features and ways to retrieve and
rank content. The following implements a custom retriever VespaStreamingHybridRetriever, that takes the following arguments:
app:VespaThe Vespa application. This could be a Vespa Cloud instance or a local instance.user:strThe user that that we want to retrieve for, this argument maps to the Vespa query request groupname parameterpages:intThe target number of PDF pages we want to retrieve for a given querychunks_per_page:intThe is the target number of relevant text chunks from a page used for context to the LLM stepchunk_similarity_threshold:float- The chunk similarity threshold, only chunks with a similarity above this threshold are used for context
The core idea is to retrieve pages using maximum chunk similarity as the initial scoring function, then consider other chunks on the same page as potentially relevant input to the generative step. We use the returned matchfeatures and the similarity threshold to accomplish the filtering.
from langchain_core.documents import Document
from langchain_core.retrievers import BaseRetriever
from typing import List
class VespaStreamingHybridRetriever(BaseRetriever):
app: Vespa
user:str
pages: int = 5
chunks_per_page: int = 3
chunk_similarity_threshold: float = 0.8
def _get_relevant_documents(self, query: str) -> List[Document]:
targetHits = self.pages * self.chunks_per_page
response:VespaQueryResponse = self.app.query(
yql=f"select id, url, title, page, authors, chunks from pdf where userQuery() or ({targetHits:{targetHits}}nearestNeighbor(embedding,q))",
groupname=self.user,
ranking="hybrid",
query=query,
hits = self.pages,
body={
"presentation.format.tensors": "short-value",
"input.query(q)": f"embed(e5, \"query: {query} \")"
}
)
if not response.is_successful():
raise ValueError(f"Query failed with status code {response.status_code}, url={response.url} response={response.json}")
return self._parse_response(response)
def _parse_response(self, response: VespaQueryResponse) -> List[Document]:
documents: List[Document] = []
for hit in response.hits:
fields = hit['fields']
chunks_with_scores = self._get_chunk_similarities(fields)
## Best k chunks from each page
best_chunks_on_page = " ### ".join(
[chunk for chunk, score in
chunks_with_scores[0:self.chunks_per_page] if score > self.chunk_similarity_threshold])
documents.append(
Document(
id=fields['id'],
page_content=best_chunks_on_page,
title=fields['title'],
metadata={
"title": fields['title'],
"url": fields['url'],
"page": fields['page'],
"authors": fields['authors'],
"features": fields['matchfeatures']
}
)
)
return documents
def _get_chunk_similarities(self, hit_fields: dict) -> List[tuple]:
match_features = hit_fields['matchfeatures']
similarities = match_features['similarities']
chunk_scores = []
for i in range(0,len(similarities)):
chunk_scores.append(similarities.get(str(i), 0))
chunks = hit_fields['chunks']
chunks_with_scores = list(zip(chunks, chunk_scores))
return sorted(chunks_with_scores, key=lambda x: x[1], reverse=True)
That’s it! We can give our newborn custom retriever a spin for the user jo-bergum by
vespa_hybrid_retriever = VespaStreamingHybridRetriever(app=app, user="jo-bergum", pages=1, chunks_per_page=1)
vespa_hybrid_retriever.get_relevant_documents("what is the maxsim operator in colbert?")
[Document(page_content='ture that precisely does so. As illustrated, every query embeddinginteracts with all document embeddings via a MaxSim operator,which computes maximum similarity (e.g., cosine similarity), andthe scalar outputs of these operators are summed across queryterms. /T_his paradigm allows ColBERT to exploit deep LM-basedrepresentations while shi/f_ting the cost of encoding documents of-/f_line and amortizing the cost of encoding the query once acrossall ranked documents. Additionally, it enables ColBERT to lever-age vector-similarity search indexes (e.g., [ 1,15]) to retrieve thetop-kresults directly from a large document collection, substan-tially improving recall over models that only re-rank the output ofterm-based retrieval.As Figure 1 illustrates, ColBERT can serve queries in tens orfew hundreds of milliseconds. For instance, when used for re-ranking as in “ColBERT (re-rank)”, it delivers over 170 ×speedup(and requires 14,000 ×fewer FLOPs) relative to existing BERT-based', metadata={'title': 'ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT', 'url': 'https://arxiv.org/pdf/2004.12832.pdf', 'page': 4, 'authors': ['Omar Khattab', 'Matei Zaharia'], 'features': {'closest(embedding)': {'0': 1.0}, 'elementSimilarity(chunks)': 0.41768707482993195, 'nativeRank(chunks)': 0.1401101487033024, 'nativeRank(title)': 0.0520403737720047, 'similarities': {'1': 0.8369992971420288, '0': 0.8730311393737793}}})]
RAG
Finally, we can connect our custom retriever with the complete flexibility and power of the LangChain LLM framework. The following uses LangChain Expression Language, or LCEL, a declarative way to compose chains.
We have several steps composed into a chain:
- The prompt template and LLM model, in this case using OpenAI
- The retriever that provides the retrieved context for the question
- The formatting of the retrieved context
vespa_hybrid_retriever = VespaStreamingHybridRetriever(app=app, user="jo-bergum", pages=3, chunks_per_page=3)
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
prompt_template = """
Answer the question based only on the following context.
Cite the page number and the url of the document you are citing.
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(prompt_template)
model = ChatOpenAI()
def format_prompt_context(docs) -> str:
context = []
for d in docs:
context.append(f"{d.metadata['title']} by {d.metadata['authors']}\n")
context.append(f"url: {d.metadata['url']}\n")
context.append(f"page: {d.metadata['page']}\n")
context.append(f"{d.page_content}\n\n")
return "".join(context)
chain = (
{"context": vespa_hybrid_retriever | format_prompt_context, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
Interact with the LLM chain
Now, we can start asking questions using the chain defined above.
chain.invoke("what is colbert?")
'ColBERT is a ranking model that adapts deep language models, specifically BERT, for efficient retrieval. It introduces a late interaction architecture that independently encodes queries and documents using BERT and then uses a cheap yet powerful interaction step to model their fine-grained similarity. This allows ColBERT to leverage the expressiveness of deep language models while also being able to pre-compute document representations offline, significantly speeding up query processing. ColBERT can be used for re-ranking documents retrieved by a traditional model or for end-to-end retrieval directly from a large document collection. It has been shown to be effective and efficient compared to existing models. (source: ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT by Omar Khattab, Matei Zaharia, page 1, url: https://arxiv.org/pdf/2004.12832.pdf)'
chain.invoke("what is the colbert maxsim operator")
"The ColBERT model utilizes the MaxSim operator, which computes the maximum similarity (e.g., cosine similarity) between query embeddings and document embeddings. The scalar outputs of these operators are summed across query terms, allowing ColBERT to exploit deep LM-based representations while reducing the cost of encoding documents offline and amortizing the cost of encoding the query once across all ranked documents.\n\nSource: \nColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT by ['Omar Khattab', 'Matei Zaharia']\nURL: https://arxiv.org/pdf/2004.12832.pdf\nPage: 4"
chain.invoke("What is the difference between colbert and single vector representational models?")
'The difference between ColBERT and single vector representational models is that ColBERT utilizes a late interaction architecture that independently encodes the query and the document using BERT, while single vector models use a single embedding vector for both the query and the document. This late interaction mechanism in ColBERT allows for fine-grained similarity estimation, which leads to more effective retrieval. (Source: ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT by Omar Khattab and Matei Zaharia, page 17, url: https://arxiv.org/pdf/2004.12832.pdf)'
Summary
Vespa’s streaming mode is a game-changer, enabling the creation of highly cost-effective RAG applications for naturally partitioned data.
In this tutorial, we delved into the hands-on application of LangChain, leveraging document loaders and transformers. Finally, we showcased a custom LangChain retriever that connected all the functionality of LangChain with Vespa.
For those interested in learning more about Vespa, join the Vespa community on Slack to exchange ideas, seek assistance, or stay in the loop on the latest Vespa developments.