
First, we are happy to announce the improved search UI at search.vespa.ai! AI-generated suggestions, paragraph indexing with hybrid ranking, results-based AI-generated abstract (RAG), and original formatting in search results. We hope this lets you find the right answer quicker and explore the rich Vespa feature space more easily - please let us know and get started with queries, like how to configure two-phased ranking. And even better; the application itself is open source, so you can see for yourself how you could do something similar - read more in the blog post.
In the previous update, we mentioned multilingual models, more control over ANN queries, mapped tensors in queries, and multiple new features in pyvespa and the Vespa CLI. Today, we’re excited to share the following updates:
Vespa.ai is its own company!
We have spun out the Vespa.ai team as a separate company. This will let us provide the community with more features even faster, and help more companies run their Vespa applications cost-effectively and with high quality on Vespa Cloud - read more in the announcement. Join us at slack.vespa.ai, and please let us know what you want from us in the future.
Vespa Cloud Enclave - Bring your own cloud
Vespa Cloud Enclave lets Vespa Cloud applications in AWS and GCP run in your cloud account/project while everything is still fully managed by Vespa Cloud’s automation with access to all Vespa Cloud features. While this adds some administration overhead, it lets you keep all data within resources controlled by your company at all times, which is often a requirement for enterprises dealing with sensitive data. Read more.
Lucene Linguistics integration
The Lucene Linguistics component, added in #27929, lets you replace the default linguistics module in Vespa with Lucene’s, supporting 40 languages. This can make it easier to migrate existing text search applications from Lucene-based engines to Vespa by keeping the linguistics treatment unchanged.
Lucene Linguistics is a contribution to Vespa from Dainius Jocas in the Vinted team - read the announcement in the blog post for more details. Also, see their own blog post for how they adopted Vespa for serving personalized second-hand fashion recommendations at Vinted.
Much faster fuzzy matching
Fuzzy matching lets you match attribute field values within a given edit distance from the value given in a query:
select * from music where myArtistAttribute contains
({maxEditDistance: 1}fuzzy("the weekend"))
In Vespa 8.238 we made optimizations to our fuzzy search implementation when matching with maxEditDistance of 1 or 2. Fuzzy searching would previously run a linear scan of all dictionary terms. We now use Deterministic Finite Automata (DFA) to generate the next possible successor term to any mismatching candidate term, allowing us to skip all terms between the two immediately. This enables sublinear dictionary matching. To avoid having to build a DFA for each query term explicitly, we use a custom lookup table-oriented implementation based on the paper Fast string correction with Levenshtein automata (2002) by Klaus U. Schulz and Stoyan Mihov.
Internal performance testing on a dataset derived from English Wikipedia (approx 250K unique terms) shows improvements for pure fuzzy searches between 10x-40x. For fuzzy searches combined with filters, we have seen up to 180x speedup.
Cluster-specific model-serving settings
You can deploy machine-learned models for ranking and inference both in container and content clusters, and container clusters optionally let you run models on GPUs. In larger applications, you often want to set up multiple clusters to be able to size for different workloads separately.

From Vespa 8.220, you can configure GPU model inference settings per container cluster:
<container id="c1" version="1.0">
<model-evaluation>
<onnx>
<models>
<model name="mul">
<intraop-threads>2</intraop-threads>
Instrumenting indexing performance
We have made it easier to find bottlenecks in the write path with a new set of metrics:
content.proton.executor.field_writer.utilization
content.proton.executor.field_writer.saturation
If .saturation is close to 1.0 and higher than .utilization, it indicates that worker threads are a bottleneck. You can then use the Vespa Cloud Console searchnode API and the documentation to spot the limiting factor in fully utilizing the CPU when feeding:
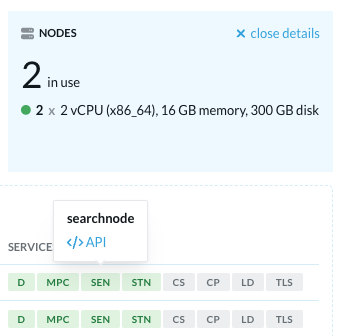
Automated BM25 reconfiguration
Vespa has had BM25 ranking for a long time:
field content type string {
indexing: index | summary
index: enable-bm25
}
However, setting enable-bm25 on a field with already indexed data required a manual procedure for the index setting to take effect. Since Vespa 8.241.13, this will happen as automated reindexing in the background like with other schema changes; see the example for how to observe the reindexing progress after enabling the field.
Minor feature improvements
- The deploy feature in the Vespa CLI is improved with better deployment status tracking, as well as other minor changes for ease-of-use.
- Nested grouping in query results, when grouping over an array of struct or maps, is scoped to preserve structure/order in the lower level from Vespa 8.223.
- Document summaries can now inherit multiple other summary classes - since Vespa 8.250.
Performance improvements
- In Vespa 8.220 we have changed how small allocations (under 128 kB) are handled for paged attributes (attributes on disk). Instead of mmapping each allocation, they share mmapped areas of 1 MB. This greatly reduces the number of mmapped areas used by vespa-proton-bin.
- Vespa uses ONNXRuntime for model inference. Since Vespa 8.250, this supports bfloat16 and float16 as datatypes for ONNX models.
- Custom components deployed to the Vespa container can use URLs to point to resources to be loaded at configuration time. From Vespa 8.216, the content will be cached on the nodes that need it. The cache saves bandwidth on subsequent deployments - see adding-files-to-the-component-configuration.
Did you know: Production deployment with code diff details
Tracking changes to the application through deployment is easy using the Vespa Cloud Console. The source link is linked to the repository if added in the deploy command:
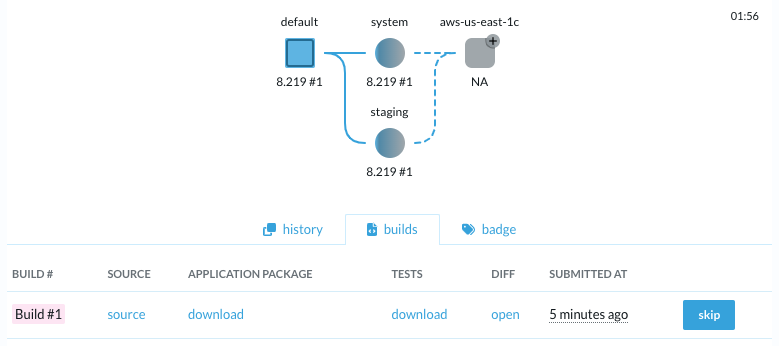
Add the link of the code diff deploy-time using source-url:
vespa prod deploy --source-url https://github.com/vespa-engine/sample-apps/commit/aa2d125229c4811771028525915a4779a8a7be6f
Find more details and how to automate in source-code-repository-integration.
Blog posts since last newsletter
- Introducing Lucene Linguistics
- HTTP/2 Rapid Reset (CVE-2023-44487)
- Vespa is becoming a company
- Announcing search.vespa.ai
Thanks for reading! Try out Vespa by deploying an application for free to Vespa Cloud or install and run it yourself.