
The rise of Large Language Models (LLMs) has transformed search and information retrieval. LLMs improve query understanding, expand search terms, reframe queries, synthesize information from multiple documents, and even generate content during document ingestion - and much more.
One exciting application is retrieval-augmented generation (RAG), which combines retrieval with the generative power of LLMs. This approach enables effective summarization using up-to-date information while reducing hallucinations.
Vespa’s robust text, vector, and hybrid search capabilities make it perfect for RAG. But there are other ways Vespa can benefit from LLMs. For instance, LLMs can enhance query understanding or summarize results during searches. They can generate additional content like keywords during document ingestion. Offline, they can even improve the machine-learned models used for ranking.
In this post, we introduce how we are integrating LLMs into Vespa. Vespa can now use LLMs directly during both query and document processing. This can be done by calling external LLM services like ChatGPT or running smaller, specialized models directly within Vespa. This integration simplifies the deployment of RAG-like applications, eliminating the need for additional software to handle interactions between Vespa and other services.
This integration shines on Vespa Cloud, which supports secure secret storage for LLM API keys and GPU inference for local LLMs.
Let’s explore how Vespa’s LLM integration stands out, especially in RAG use cases. We’ll show how Vespa offers seamless integration with external LLM services while also supporting local execution, ensuring flexibility, data security, and model customization.
RAG in Vespa
Retrieval-augmented generation (RAG) enhances LLM responses by incorporating real-time data retrieval. It starts with the user’s input, fetches relevant info from various sources, and enriches the LLM’s response with up-to-date data.
Vespa is ideal for RAG due to its strong retrieval capabilities. As a full-featured search engine and vector database, Vespa supports a range of retrieval techniques like vector search (ANN), lexical search, and hybrid search. This means Vespa can efficiently retrieve the most relevant data based on the user’s query. Vespa’s advanced indexing and ranking capabilities further enhance the relevance and accuracy of the retrieved data.
Here are some use cases for RAG in Vespa:
- Chatbots and virtual assistants: Provide accurate, up-to-date responses by retrieving info from knowledge bases or documentation.
- E-commerce platforms: Enhance product recommendations and search results by fetching customer data, product info, and user reviews in real-time.
- Content platforms: Surface the most relevant articles, videos, or posts based on user queries, considering freshness and popularity.
The RAG sample app, which we discuss below, demonstrates how to implement retrieval-augmented generation using both external LLM services and local LLMs. It’s a great starting point for developers looking to build their own RAG applications using Vespa’s retrieval and serving capabilities.
Large language models in Vespa
To see how LLMs are integrated into Vespa, let’s take a look at query and document processing.
In Vespa, queries pass through a sequence of processors called “searchers” within the Vespa search container. This sequence is called a search chain. Each searcher processes the query in sequence, performing tasks like filtering, ranking, and modifying the query. The last searcher generates a result, which is then passed back up the chain. Each searcher can modify or add to the result. Once processed by all searchers, the result is translated into a client-friendly response format.
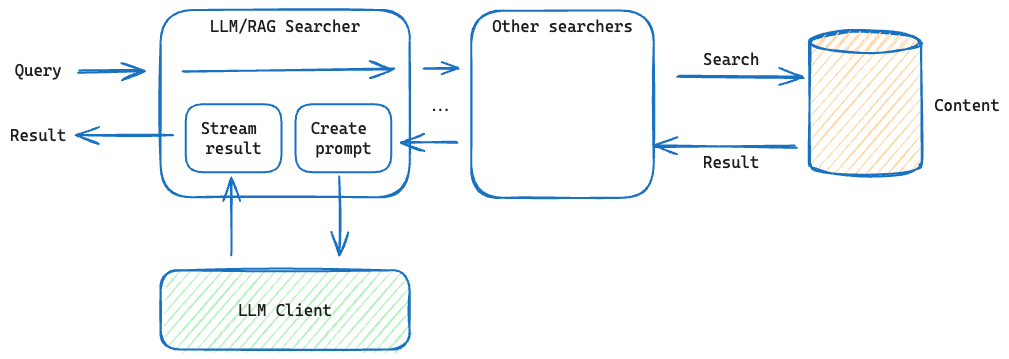
Document processing during feeding follows a similar flow with document processors.
Searchers are configured within the application’s services.xml. Here’s an example of setting up a simple RAG application:
<services version="1.0">
<container id="default" version="1.0">
...
<component id="openai" class="ai.vespa.llm.clients.OpenAI">
<!-- Configure as required -->
</component>
<search>
<chain id="rag" inherits="vespa">
<searcher id="ai.vespa.search.llm.RAGSearcher">
<config name="ai.vespa.search.llm.llm-searcher">
<providerId>openai</providerId>
</config>
</searcher>
</chain>
</search>
...
</container>
</services>
Key elements here are the search chain, the RAG searcher, and the OpenAI provider component.
The rag search chain inherits from the standard vespa search chain, which
performs standard query processing. We’ve added a searcher called RAGSearcher
to this chain. This passes the query through without modification, however when
the results from the query are returned, the searcher builds a prompt using the
search results as context.
The RAGSearcher sends this prompt to a configured LLM service, like the OpenAI
provider (ChatGPT by default). Vespa supports any OpenAI API-compatible
endpoint and local inference of LLM models, which we’ll cover below.
Using the Vespa CLI, you can query this application like this:
vespa query \
query="what was the manhattan project?" \
searchChain=rag \
format=sse
This invokes the rag search chain. Setting the format to sse returns
Server-Sent Events, streaming each token as received from the LLM service.
That’s all you need to set up a basic RAG application in Vespa.
Vespa’s flexibility allows developers to integrate LLMs in the processing flow where it makes sense, giving them fine-grained control. This enables the creation of advanced applications that leverage the strengths of both Vespa and LLMs.
For more information, please refer to LLMs in Vespa.
Connecting to external LLM providers
Setting up connections to external LLM services like OpenAI’s ChatGPT is a straightforward process. In the services.xml configuration file, you can define a component that specifies the connection details to the LLM service. This involves setting the options:
- An optional API endpoint. By default, OpenAI’s ChatGPT endpoint is used, but can be set to any endpoint that is
- OpenAI API-compatible</a>.
- An optional secret store key. If you have stored your API key securely in Vespa, you can set the name of the secret which contains the API key.
These are optional. If neither of these are set, you can pass the API key as a header in your query to Vespa:
vespa query \
--header="X-LLM-API-KEY:..." \
query="what was the manhattan project?" \
searchChain=rag \
format=sse
External LLM services offer several advantages: leveraging state-of-the-art language models without hosting them yourself, and handling infrastructure and scaling. However, there are some considerations to keep in mind when using external LLM services. One key aspect is data privacy and security. Since the data is sent to the external service for processing, it’s important to ensure that sensitive information is handled appropriately.
Local LLM inference
Vespa offers a unique capability to run large language models (LLMs) directly within the application. As LLMs become smaller and possibly specialized to various tasks, such as summarization, this becomes increasingly more interesting.
By running LLMs locally, Vespa eliminates the need for external dependencies as the LLM is managed by the Vespa container. Data remains secure and under the control of the application owner. Additionally, local LLMs enable model customization and fine-tuning to specific domain requirements, as the models can be trained and optimized using the application’s own data.
To set up a local LLM, we simply set up a local LLM component:
<component id="local" class="ai.vespa.llm.clients.LocalLLM">
<config name="ai.vespa.llm.clients.llm-local-client">
<model url="..." />
</config>
</component>
This setup downloads the model from a URL during application startup. For more info on supported models and customization options, refer to Vespa’s local LLM documentation.
We’ll share more about running LLMs locally in future posts.
Consuming results
By default, Vespa returns a full JSON structure containing the results.
However, this means one would have to wait until the entire response is
generated from the underlying LLM before Vespa can return its result. To stream
the tokens as they arrive, invoke the sse (Server-Sent
Events)
renderer by adding the format query parameter format=sse. This format is
text-based, where each token is an event.
For instance, the following could be produced for the query What was the
Manhattan project?:
event: token
data: {"token":"The"}
event: token
data: {"token":" Manhattan"}
event: token
data: {"token":" Project"}
event: token
data: {"token":" was"}
event: token
data: {"token":" a"}
...
These events can be consumed by using an EventSource as described in the
HTML
specification,
or however you see fit as the format is fairly simple. Each data element
contains a small JSON object which must be parsed, and contains a single token
element containing the actual token.
The RAG sample app
The RAG sample app is a great starting point for understanding how to implement retrieval-augmented generation using Vespa. It demonstrates an end-to-end RAG application in Vespa, where all the steps are run entirely within Vespa. No other systems are required. Three versions of the application is shown:
- Using an external LLM service to generate the final response.
- Using local LLM inference to generate the final response.
- Deploying to Vespa Cloud and using GPU accelerated LLM inference to generate the final response.
One of the key takeaways from the RAG sample app is the flexibility it provides in terms of LLM integration. The generation is agnostic of how results are retrieved. Thus all the power of Vespa can be used to retrieve accurate context for the text generation, whether it be text search, vector search, or hybrid search with additional machine learned ranking models.
The sample application can be found here: Retrieval Augmented Generation (RAG) in Vespa.
Conclusion and further work
We explored Vespa’s integration with large language models (LLMs), focusing on retrieval-augmented generation (RAG). Vespa’s comprehensive search and retrieval capabilities make it an ideal platform for RAG applications. Its ability to run LLMs both externally and locally provides flexibility, data security, and model customization.
For more information on running LLMs and RAG in Vespa, please refer to:
- LLMs in Vespa documentation
- Retrieval-augmented generation (RAG) in Vespa documentation
- Perspectives on R in RAG
- Yahoo Mail turns to Vespa to do RAG at scale
- Announcing search.vespa.ai
Looking ahead, the combination of Vespa and LLMs holds great potential. In the next part of this series, we’ll delve into the search pipeline at search.vespa.ai and how each step is executed entirely within Vespa.
