
In the previous update, we mentioned a new SPLADE embedder, float16 support for ONNX models, new Cohere guides, and support for using ColBERT with long texts. Today we’re excited to share the following updates:
RAG in Vespa
Vespa is now providing LLM inference support, so you can implement your RAG application entirely as a Vespa application.
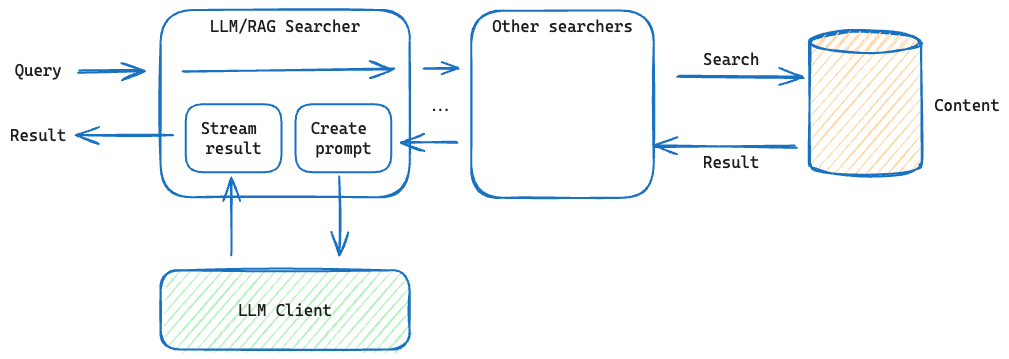
We have added a new sample application demonstrating Retrieval-augmented generation (RAG) end-to-end on Vespa. This sample application shows how to build upon the search results from Vespa and use an LLM to generate a final response:
- Generation using an external LLM like OpenAI
- Running an LLM locally inside the Vespa application on CPU
- Running an LLM inside the Vespa application on Vespa Cloud on GPU
Read more in the Vespa and LLMs blogpost.
An order of magnitude cheaper vector search
Vespa supports creating embeddings when feeding documents and making queries - see embedding. Since Vespa 8.337, the huggingface-embedder can now be configured with text to prepend for documents and queries, see the reference - this is useful for models that have been trained with specific prompt instructions. See the ColBERT and Long-Context ColBERT sample applications for practical examples.
Embedding data can be a computationally intensive operation. With multi-phase ranking, one can reduce cost by an order of magnitude or more by using lower-resolution vectors during retrieval and phase 1 ranking, and higher-resolution embeddings from an on-disk (paged) attribute in later ranking phases. Since Vespa 8.329, embedding the data once for multiple resolutions is supported. See the blog post on combining Matryoshka with binary quantization for how to use embeddings in multiple representations.
New Pyvespa features
- With #757, one can now install the Vespa CLI by just
pip3 install vespacli. As the Vespa CLI manages secrets, this simplifies the Python code required to interface with vespa Cloud using Python, see getting started with Pyvespa for an example. - Thanks to Fed0rah, Pyvespa now supports the mutate operation in rank profiles (see #775). This is a great feature for rank phase statistics. To evaluate how well the document corpus matches the queries, use mutable attributes to track how often each document survives each match- and ranking-phase. This is aggregated per document and makes it easy to analyse using the query and grouping APIs in Vespa - and no other processing/storage is required.
- Thanks to olaughter, Pyvespa now supports visiting - see #776.
- Vespa supports many kinds of updates to a field, including arithmetic and set operations - see update. Since #738, these operations are supported in Pyvespa.
- We added a notebook that demonstrates how the mixedbread.ai rerank models (cross encoders) can be used for global phase reranking in Vespa.
Fuzzy Search with Prefix Match
A common use case for interactive search experiences is type-ahead searching. Here results start appearing immediately as the user types, getting more and more refined as the user keeps typing. One way to solve this is by using prefix matching; a user searching for the prefix “Edvard Gr” will get back documents matching “Edvard Grieg”. However, prefix matching requires the query and the document prefixes to match exactly; searching for “Edward Gr” or “Eddvard Gr” will not return anything at all. This may fail to surface many potential completions.
Vespa has supported “typo-friendly” fuzzy matching of terms for years, where a string matches if it can be transformed to the query within a query-specified maximum number of edits (inserts, deletions, or substitutions), but this matches entire strings and therefore cannot be used for prefixes. E.g. “Edward Gr” will not fuzzy-match “Edvard Grieg” with max edits of 1 because matching would require both replacing “w” with “v” as well as inserting “ieg” to the end, which is 4 edits in total.
Vespa 8.337 and beyond add support for fuzzy prefix matching, which combines the best of both worlds. A string is considered a match if its prefix can be transformed to the query within a specified maximum number of edits. This means “Edward Gr” and “Eddvard Gr” will match “Edvard Grieg”, “Mettal” will match “Metallica” and so on.
Data copy performance improvements
Migrating data from one Vespa instance to another is as easy as:
vespa visit | vespa feed
In Vespa, data is organized in buckets (think of micro-shards). A moderately sized vespa cluster can have millions of buckets. This makes for a uniform data distribution with smooth and automated elasticity functions and no need for manual re-sharding. Using an algorithm inspired by RUSH (replication under scalable hashing), Vespa has minimal data redistribution at planned and unplanned cluster resizing.
Vespa iterates over data in bucket order, so a subsequent feed inserts data in the same order. Since Vespa 8.349, the insertion throughput where the data source is another Vespa instance is optimized to approximately 10x of the original by transparently micro-batching writes to the same bucket.
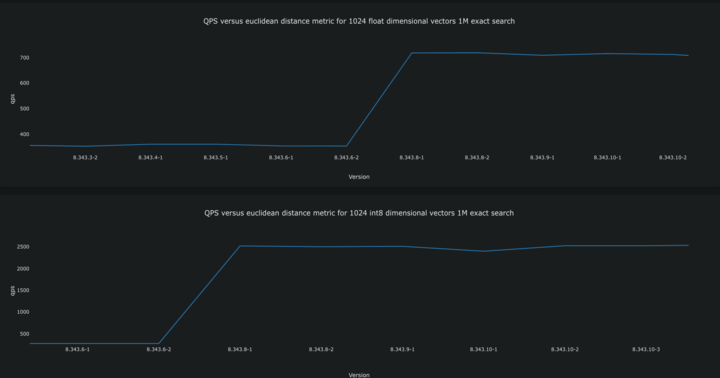
Distance calculation performance improvements
Vespa supports both exact and approximate nearest neighbor search using vectors with bit, int8, bfloat16, float, and double value types. On 8.344 we released new optimizations to speed up value type conversions and distance computations, resulting in the following improvements in x86-64 CPU architectures (the effect on arm64 is likely somewhat smaller).
- Bit vectors with hamming distance:
- Up to 40% increase in QPS for exact nearestNeighbor queries.
- Bfloat16 vectors with HNSW index:
- Up to 50% increase in feed throughput.
- Up to 40% increase in QPS for approximate nearestNeighbor queries.
- Float vectors with euclidean distance:
- Up to 2x increase in QPS for exact nearestNeighbor queries.
- Int8 vectors:
- angular distance: Up to 30% increase in QPS for exact nearestNeighbor queries.
- dotproduct distance: Up to 5x increase in QPS for exact nearestNeighbor queries.
- euclidean distance: Up to 9x increase in QPS for exact nearestNeighbor queries.
- Note: Some improvements are also expected in QPS for approximate nearestNeighbor queries.
Other new features
- LlamaIndex and Vespa: Get started using Vespa with LlamaIndex! Check out the new Vespa Vector Store demo notebook, also see the announcement.
- Very long tokens: Care should be taken when feeding unstructured/unknown data. If clients feed very long tokens or long text in fields without tokenization (match:exact/word), Vespa will produce an index containing them, which is wasteful. Since Vespa 8.342, the default max token length is 1000 characters. Longer tokens are silently ignored and will not be part of the index. This is configurable per field; see max-token-length.
- Rank debugging: Rank functions can become arbitrarily complex, which makes ranking analysis challenging. Vespa supports multi-phase ranking, and the firstPhase rank score is available for rank analysis. From Vespa 8.344, the secondPhase rank score is available in the output too - see the reference documentation.
Blog posts since last newsletter
Events
Meet us at the AI Engineer World’s Fair in San Francisco, June 25-27!
Thanks for joining us in exploring the frontiers of AI with Vespa. Ready to take your projects to the next level? Deploy your application for free on Vespa Cloud today.