

This blog post deep dives into “ColPali: Efficient Document Retrieval with Vision Language Models” which introduces a novel approach to document retrieval that leverages the power of vision language models (VLMs).
Introduction
Imagine a world where search engines could understand documents the way humans do – not just by reading the words, but by truly seeing and interpreting the visual information. This is the vision behind ColPali, a refreshing document retrieval model that leverages the power of vision language models (VLMs) to unlock the potential of visual information in Retrieval-Augmented Generation (RAG) pipelines.
Just as our brains integrate visual and textual cues when we read a document, ColPali goes beyond traditional text-based retrieval methods. It uses a vision-capable language model (PaliGemma) to “see” the text, but also the visual elements of a document, including figures, tables and infographics. This enables a richer understanding of the content, leading to more accurate and relevant retrieval results.
ColPali is short for Contextualized Late Interaction over PaliGemma and builds on two key concepts:
-
Contextualized Vision Embeddings from a VLM: ColPali generates contextualized embeddings directly from images of document pages, using PaliGemma, a powerful VLM with built-in OCR capabilities (visual text understanding). This allows ColPali to capture the full richness of both text and visual information in documents. This is the same approach as for text-only retrieval with ColBERT. Instead of pooling the visual embeddings for a page into a single embedding representation, ColPali uses a grid to represent the image of a page where each grid cell is represented as an embedding.
-
Late Interaction ColPali uses a late interaction similarity mechanism to compare query and document embeddings at query time, allowing for interaction between all the image grid cell vector representations and all the query text token vector representations. This enables ColPali to effectively match user queries to relevant documents based on both textual and visual content. In other words, the late interaction is a way to compare all the image grid cell vector representations with all the query text token vector representations. Traditionally, with a VLM, like PaliGemma, one would input both the image and the text into the model at the same time. This is computationally expensive and inefficient for most use cases. Instead, ColPali uses a late interaction mechanism to compare the image and text embeddings at query time, which is more efficient and effective for document retrieval tasks and allows for offline precomputation of the contextualized grid embeddings.
The Problem with Traditional Document Retrieval
Document retrieval is a fundamental task in many applications, including search engines, information extraction, and retrieval-augmented generation (RAG). Traditional document retrieval systems primarily rely on text-based representations, often struggling to effectively utilize the rich visual information present in documents.
-
Extraction: The process of indexing a standard PDF document involves multiple steps, including PDF parsing, optical character recognition (OCR), layout detection, chunking, and captioning. These steps are time-consuming and can introduce errors that impact the overall retrieval performance. Beyond PDF, other document formats like images, web pages, and handwritten notes pose additional challenges, requiring specialized processing pipelines to extract and index the content effectively. Even after the text is extracted, one still needs to chunk the text into meaningful chunks for use with traditional single-vector text embedding models that are typically based on context-length limited encoder-styled transformer architectures like BERT or RoBERTa.
-
Text-Centric Approach: Most systems focus on text-based representations, neglecting the valuable visual information present in documents, such as figures, tables, and layouts. This can limit the system’s ability to retrieve relevant documents, especially in scenarios where visual elements are crucial for understanding the content.
The ColPali model addresses these problems by leveraging VLMs (in this case: PaliGemma – Google’s Cutting-Edge Open Vision Language Model) to generate high-quality contextualized embeddings directly from images of PDF pages. No text extraction, OCR, or layout analysis is required. Furthermore, there is no need for chunking or text embedding inference as the model directly uses the image representation of the page.
Essentially, the ColPali approach is the WYSIWYG (What You See Is What You Get) for document retrieval. In other words; WYSIWYS (What You See Is What You Search).
ColPali: A Vision Language Model for Document Retrieval
Vision Language Models (VLMs) have gained popularity for their ability to understand and generate text based on combined text and visual inputs. These models combine the power of computer vision and natural language processing to process multimodal data effectively. The Pali in ColPali is short for PaliGemma as the contextual image embeddings come from the PaliGemma model from Google.
PaliGemma is a family of vision-language models with an architecture consisting of SigLIP-So400m as the image encoder and Gemma-2B as text decoder. SigLIP is a state-of-the-art model that can understand both images and text. Like CLIP, it consists of an image and text encoder trained jointly.
Quote from PaliGemma model from Google.
 For a deeper introduction to Vision Language Models (VLMs), check out Vision Language Models Explained.
For a deeper introduction to Vision Language Models (VLMs), check out Vision Language Models Explained.
VLMs display enhanced capabilities in Visual Question Answering 1, captioning, and document understanding tasks. The ColPali model builds on this foundation to tackle the challenge of document retrieval, where the goal is to find the most relevant documents based on a user query.
To implement retrieval with a VLM, one could add the pages as images into the context window of a frontier VLM (Like Gemini Flash or GPT-4o), but this would be computationally expensive and inefficient for most (not all) use cases. In addition to computing, latency would be high when searching large collections.
ColPali is designed to be more efficient and effective for document retrieval tasks by generating contextualized embeddings directly from images of document pages. Then the retrieved pages could be used as input to a downstream VLM model. This type of serving architecture could be described as a retrieve and read pipeline or in the case of ColPali, a retrieve and see pipeline.
Note that the ColPali model is not a full VLM like GPT-4o or Gemini Flash, but rather a specialized model for document retrieval. The model is trained to generate embeddings from images of document pages and compare them with query embeddings to retrieve the most relevant documents.
ColPali architecture
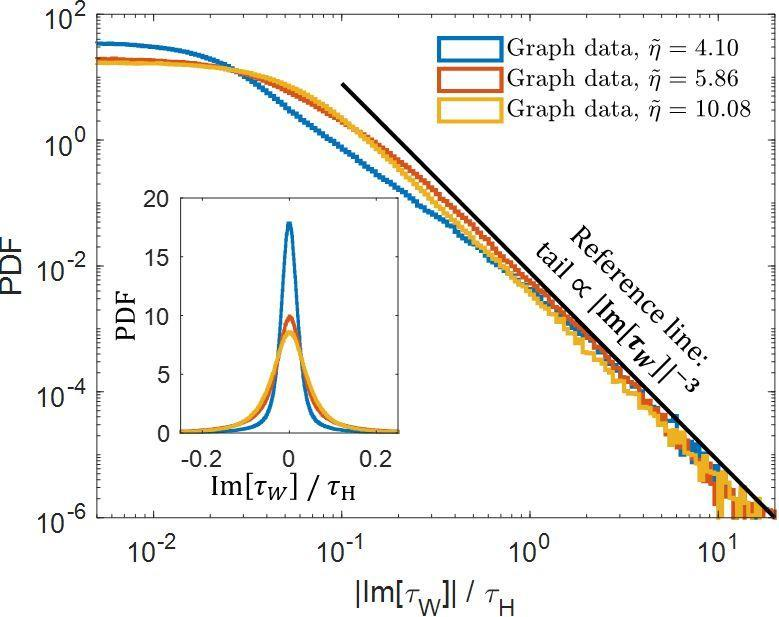
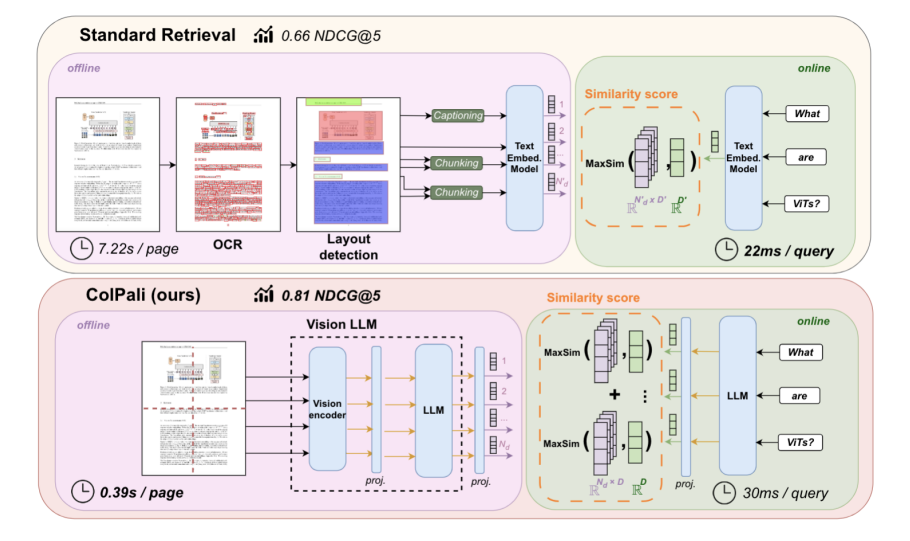 Comparing standard retrieval methods which use parsing, text extraction, OCR and layout detection with ColPali. Illustration from 2. Notice
that the simpler pipeline achieves better accuracy on the ViDoRe benchmark than the more complex traditional pipeline. 0.81 NDCG@5 for ColPali vs 0.66 NDCG@5 for the traditional pipeline.
Comparing standard retrieval methods which use parsing, text extraction, OCR and layout detection with ColPali. Illustration from 2. Notice
that the simpler pipeline achieves better accuracy on the ViDoRe benchmark than the more complex traditional pipeline. 0.81 NDCG@5 for ColPali vs 0.66 NDCG@5 for the traditional pipeline.
- Image-Based Page Embeddings: ColPali generates contextualized embeddings solely from images of document pages, bypassing the need for text extraction and layout analysis. Each page is represented as a 32x32 image grid (patch), where each patch is represented as a 128-dimensional vector.
- Query Text Embeddings: The query text is tokenized and each token is represented as a 128-dimensional vector.
- Late Interaction Matching: ColPali employs a so-called late interaction similarity mechanism, where query and document embeddings are compared at query time (dotproduct), allowing for interaction between all the image patch vector representations and all the query text token vector representations. See our previous work on ColBERT, ColBERT long-context for more details on the late interaction (MaxSiM) similarity mechanisms. The Col in ColPali is short for the interaction mechanism introduced in ColBERT where Col stands for Contextualized Late Interaction.
 Illustration of a 32x32 image grid (patch) representation of a document page. Each patch is a 128-dimensional vector. This image
is from the vidore/docvqa_test_subsampled test set.
Illustration of a 32x32 image grid (patch) representation of a document page. Each patch is a 128-dimensional vector. This image
is from the vidore/docvqa_test_subsampled test set.
The above figure illustrates the patch grid representation of a document page. Each patch is a 128-dimensional vector, and the entire page is represented as a 32x32 grid of patches. This grid is then used to generate contextualized embeddings for the document page.
The Problem with Traditional Document Retrieval Benchmarks
Most Information Retrieval (IR) and Natural Language Processing (NLP) benchmarks are only concerned with clean and preprocessed texts. For example, MS MARCO and BEIR.
The problem is that real-world retrieval use cases don’t have the luxury of preprocessed clean text data. These real-world systems need to handle the raw data as it is, with all its complexity and noise. This is where the need for a new benchmark arises. The ColPali paper 2 introduces a new and challenging benchmark: ViDoRe: A Comprehensive Benchmark for Visual Document Retrieval (ViDoRe). This benchmark is designed to evaluate the ability of retrieval systems to match user queries to relevant documents at the page level, considering both textual and visual information.
ViDoRe features:
-
Multiple Domains: It covers various domains, including industrial, scientific, medical, and administrative.
-
Academic: It uses existing visual question-answering benchmarks like DocVQA (Document Visual Question Answering), InfoVQA (Infographic Visual Question Answering) and TAT-DQA. These visual question-answering datasets focus on specific modalities like figures, tables, and infographics.
-
Practical: It introduces new benchmarks based on real-world documents, covering topics like energy, government, healthcare, and AI. These benchmarks are designed to be more realistic and challenging than repurposed academic datasets. Most of the queries for real-world documents are generated by frontier VLMs.
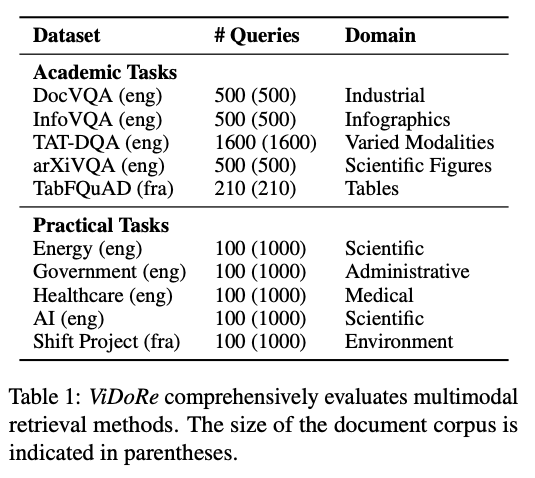
ViDoRe: A Comprehensive Benchmark for Visual Document Retrieval (ViDoRe)
ViDoRe provides a robust and realistic benchmark for evaluating the performance of document retrieval systems that can effectively leverage both textual and visual information. The full details of the ViDoRe benchmark can be found in the ColPali paper 2 and the dataset is hosted as a collection on Hugging Face Datasets. One can view some of the examples using the dataset viewer:infovqa test.
The paper 2 evaluates ColPali against several baseline methods, including traditional text-based retrieval methods, captioning-based approaches, and contrastive VLMs. The results demonstrate that ColPali outperforms all other systems on ViDoRe, achieving the highest NDCG@5 scores across all datasets.
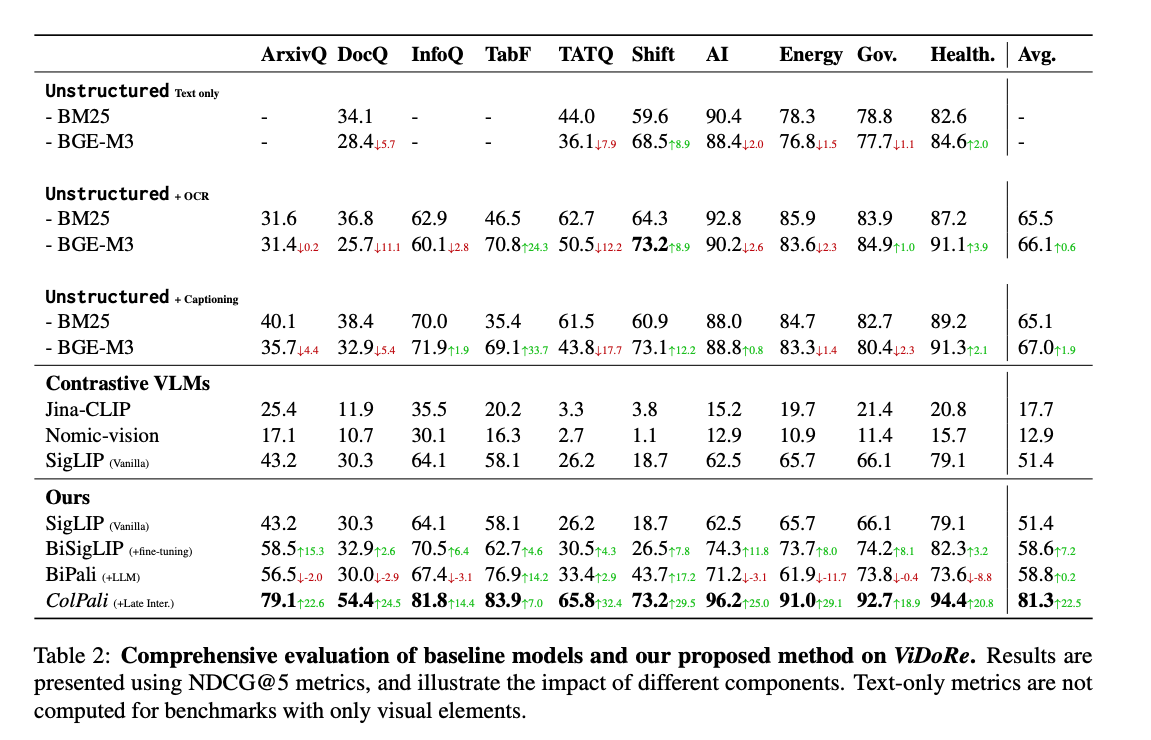
Looking at the result table we can observe that:
-
Visually Rich Datasets: ColPali significantly outperforms all other methods on datasets with complex visual elements, like ArXivQ, and TabF. These datasets require OCR for text-based retrieval methods. This demonstrates its ability to effectively leverage visual information for retrieval.
-
Overall Performance: ColPali achieves the highest NDCG@5 scores across all datasets, including those with primarily textual content where also simple text extraction and BM25 work well (AI, Energy, Gov, Health). Even on these datasets, ColPali’s performance is better, indicating that PaliGemma has strong OCR capabilities.
Examples from the ViDoRe benchmark




Examples of documents in the ViDoRe benchmark. These documents contain a mix of text and visual elements, including figures, tables, and infographics. The ColPali model is designed to effectively retrieve documents based on both textual and visual information.
Limitations
While ColPali is a powerful tool for document retrieval, it does have limitations:
-
Focus on PDF-like Documents: ColPali was primarily trained and evaluated on documents similar to PDFs, which often have structured layouts and contain images, tables, and figures. Its performance on other types of documents, like handwritten notes or web page screenshots, might be less impressive.
-
Limited Multilingual Support: Although ColPali shows promise in handling non-English languages (TabQuAD dataset which is French), it was mainly trained on English data, so its performance with other languages may be less consistent.
-
Limited Domain-Specific Knowledge: While ColPali achieves strong results on various benchmarks, it might not generalize as well to highly specialized domains requiring specialized knowledge. Fine-tuning the model for specific domains might be necessary for optimal performance.
We consider the architecture of ColPali to be more important than the underlying VLM model or the exact training data used to train the model checkpoint. The ColPali approach generalizes to other VLMs as they become available, and we expect to see more models and model checkpoints trained on more data. Similarly, for text-only, we have seen that the ColBERT architecture is used to train new model checkpoints, 4 years after its introduction. We expect to see the same with the ColPali architecture in the future.
ColPali’s role in RAG Pipelines
The primary function of the RAG pipeline is to generate answers based on the retrieved documents. The retriever’s role is to find the most relevant documents, and the generator then extracts and synthesizes information from those documents to create a coherent answer.
Therefore, if ColPali is effectively retrieving the most relevant documents based on both text and visual cues, the generative phase in the RAG pipeline can focus on processing and summarizing the retrieved results from ColPali.
ColPali already incorporates visual information directly into its retrieval process and for optimal results, one should consider feeding the retrieved image data into the VLM for the generative phase. This would allow the model to leverage both textual and visual information when generating answers.
Summary
ColPali is a groundbreaking document retrieval model, probably one of the most significant advancements in the field of document retrieval in recent years. By leveraging the power of vision language models, ColPali can effectively retrieve documents based on both textual and visual information. This approach has the potential to revolutionize the way we search and retrieve information, making it more intuitive and efficient. Not only does ColPali outperform traditional text-based retrieval methods, but it also opens up new possibilities for integrating visual information into retrieval-augmented generation pipelines.
As this wasn’t enough, it also greatly simplifies the document retrieval pipeline by eliminating the need for text extraction, OCR, and layout analysis. This makes it easier to implement and deploy in real-world applications with minimal preprocessing and extraction steps during indexing.
If you want to learn more about ColPali, and how to represent ColPali in Vespa, check out our previous post on PDF Retrieval with Vision Language Models.
Other useful resources on ColPali:
For those interested in learning more about Vespa or ColPali, feel free to join the Vespa community on Slack or Discord to exchange ideas, seek assistance from the community, or stay in the loop on the latest Vespa developments.
