
Much of the excitement (and business value) around Large Language Models (LLMs) is associated with building RAG (Retrieval Augmented Generation) solutions, connecting the power of LLMs with retrieval models over proprietary knowledge databases. A key challenge for developers working with RAG is to convert various document formats (such as PDFs, HTML, etc.) into a format that can be used by text models.
A typical real-world RAG pipeline for PDFs (or other complex formats) involves steps like:
- Extracting text and metadata
- OCR (Optical Character Recognition)
- Layout analysis, extracting tables, charts, pie charts etc
Then, after all that processing to obtain text representations, one can use the text as input for retrieval systems like Vespa. With Vespa one can chunk and embed the text using text embedding models like Cohere, ColBERT etc, or hybrid combinations using traditional BM25.
Each of these “extract and embed” steps can be complex and time-consuming and greatly impact the retrieval quality. Garbage in, garbage out. For example, there are already years’ worth of YouTube videos dedicated solely to the topic of chunking text data for embeddings.
But, what if we could skip the complex “extract, chunk, and embed” steps and directly embed the entire rendered document (including images, charts, tables) into vector representations useful for retrieval?

Screenshots of complex (and information-rich) PDF pages. Source
From OCR to Vision Language Models
Vision Language Models (VLMs)1 are a new class of models that combine vision (image) and text capabilities. Unlike traditional text-only models, VLMs can process and read both visual and textual data. This integration allows VLMs to handle tasks that require an understanding of visual content in conjunction with text, such as interpreting images, generating descriptions for visual inputs, and even answering questions based on visual context. See, visual language models isn’t just about photos of cute cats; they are also about complex documents like PDFs, where the visual content is as important as the text.
ColPali - Just embed the screenshot using a vision language model
ColPali 2 offers a refreshing alternative to the complex extract and embed pipelines usually involved for complex document formats; ColPali directly embeds the screenshot of a PDF page (including images, charts, tables) into vector representations useful for retrieval (and ranking). No need for OCR, layout analysis, or any other complex preprocessing steps. Also, there is no text chunking.
All you need is the screenshot image of the page.
The Col in ColPali is inspired by ColBERT where text is represented as multiple vectors, instead of a single vector representation. The Pali in ColPali is PaliGemma which is a powerful visual language model.
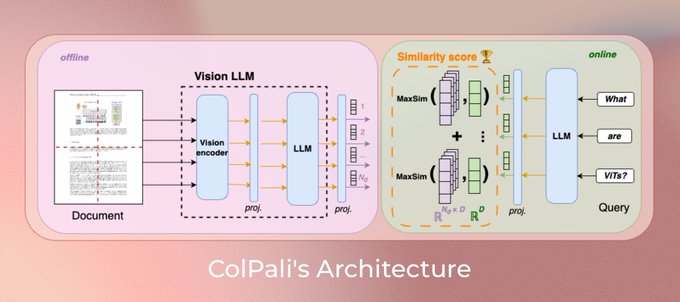
Overview of the ColPali model architecture Source
ColPali builds on two observations:
- Multi-vector representations and late-interaction scoring improve retrieval performance. 2
- Vision language models have demonstrated extraordinary capabilities in understanding visual content. 3
Understanding documents with rich layouts and multi-modal components is a long-standing and practical task. Recent Large Vision-Language Models (LVLMs) have made remarkable strides in various tasks, particularly in single-page document understanding (DU).
Quote from 3.
The ColPali model is trained end-to-end to optimize the page retrieval task. It projects the grid cell (patch) into a 128-dimensional embedding. The textual query representation is also projected into the same 128-dimensional space, one per vector per text token. Then, similar to ColBERT, the model uses a late-interaction scoring mechanism (MaxSim) to compute the similarity score between the query token vectors and the page image’s patch vectors.
How does ColPali compare with other retrieval models?
Most Information Retrieval(IR) benchmarks (like BEIR) do not include complex document formats, developers are given clean and preprocessed texts. This poorly reflects real-world scenarios, where documents often contain complex elements like images, tables and charts.
To overcome this and to benchmark ColPali against other retrieval methods, the ColPali authors introduce the Visual Document Retrieval (ViDoRe) Benchmark.
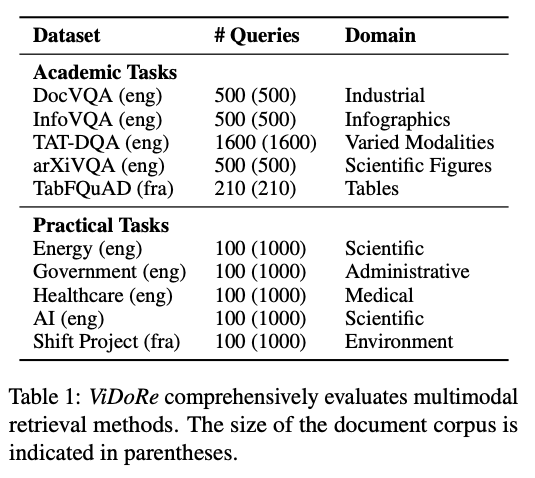
Composition of the Visual Document Retrieval (ViDoRe) benchmark. Screenshot from the paper2
 Sample of queries and document pages from ViDoRe. Screenshot from the paper2
Sample of queries and document pages from ViDoRe. Screenshot from the paper2
The ColPali model achieves remarkable retrieval performance on the introduced ViDoRe benchmark. Beating complex pipelines that involve OCR, layout analysis, captioning with large VLMs, and text embedding models.
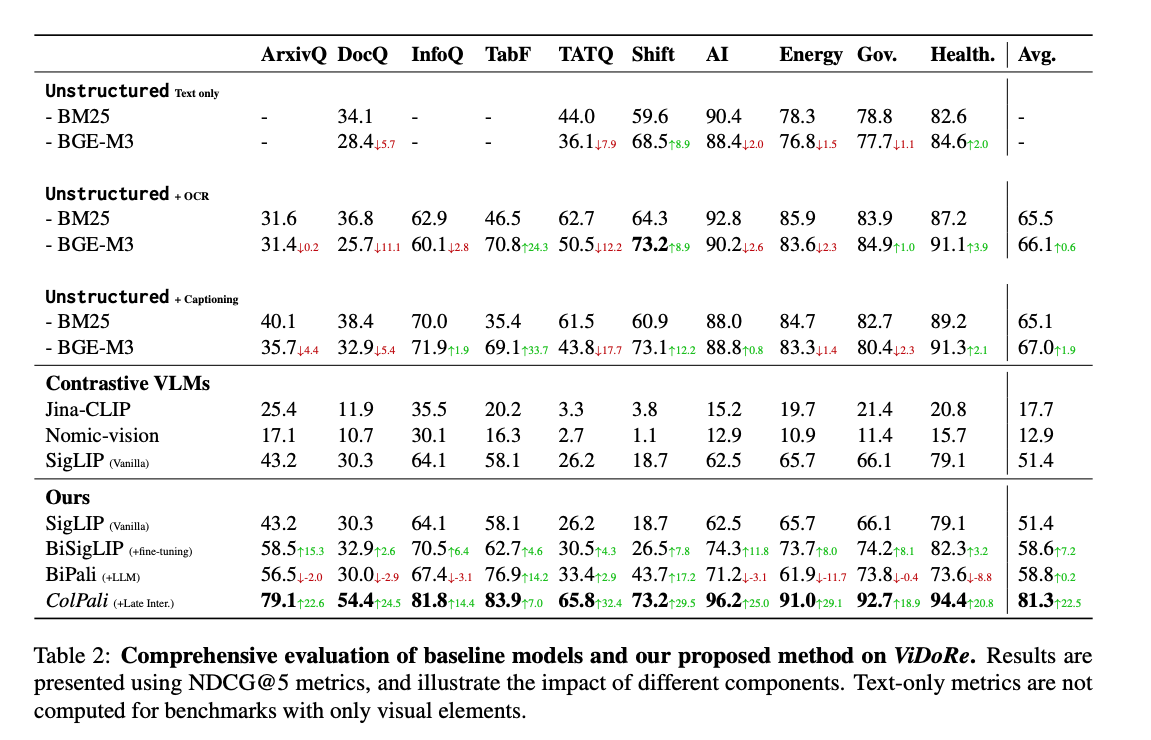
Retrieval methods evaluated on the Visual Document Retrieval Benchmark (ViDoRe), screenshot from the paper2
The authors compare ColPali with other retrieval models:
- BM25 (baseline) using text representations obtained from industry-strength pipelines (unstructured.io)
- BGE-M3 (Mother of all embeddings) using chunked representations of the text
Both BM25 and BGE-M3 are text-based retrieval models. ColPali outperforms both models, nDCG@5 81.3 versus 65-75. The authors also compare with contrastive single-vector vision models like Jina-CLIP and Nomic-vision, but these models have not been trained on this task and perform poorly.
The large gain in effectiveness is one nice aspect, but most important is the simplicity of the ColPali model; just embed the image of the page.
Representing ColPali embeddings in Vespa
We have created a complete notebook that demonstrates how to use ColPali embeddings in Vespa if you want to jump into it right away.
With Vespa’s tensor framework and compute engine we can represent the ColPali embeddings and express the late-interaction scoring in Vespa ranking expressions just like with ColBERT.
There are two primary ways we can represent ColPali embeddings for a PDF document in Vespa:
- Store each page of the PDF as a document. In this case, we will need to duplicate document-level metadata as title, author, etc. for each page. This type of meta information could
be useful for filtering, but also in ranking. The ColPali embeddings are then expressed as a mixed tensor
tensor<float>(patch{}, v[128])where the first dimension is the patch id, and the second is the dense vector embedding. - Store a PDF as a single Vespa document and use another tensor dimension to represent the page,
tensor<float>(page{}, patch{}, v[128]).
Using binarization, we can also use tensor<int8>(page{}, patch{}, v[16]), see colbert for details on
binarization of colbert-like embeddings. Binarization reduces the storage footprint by 32x compared to float, and 16x compared to half-precision bfloat16.
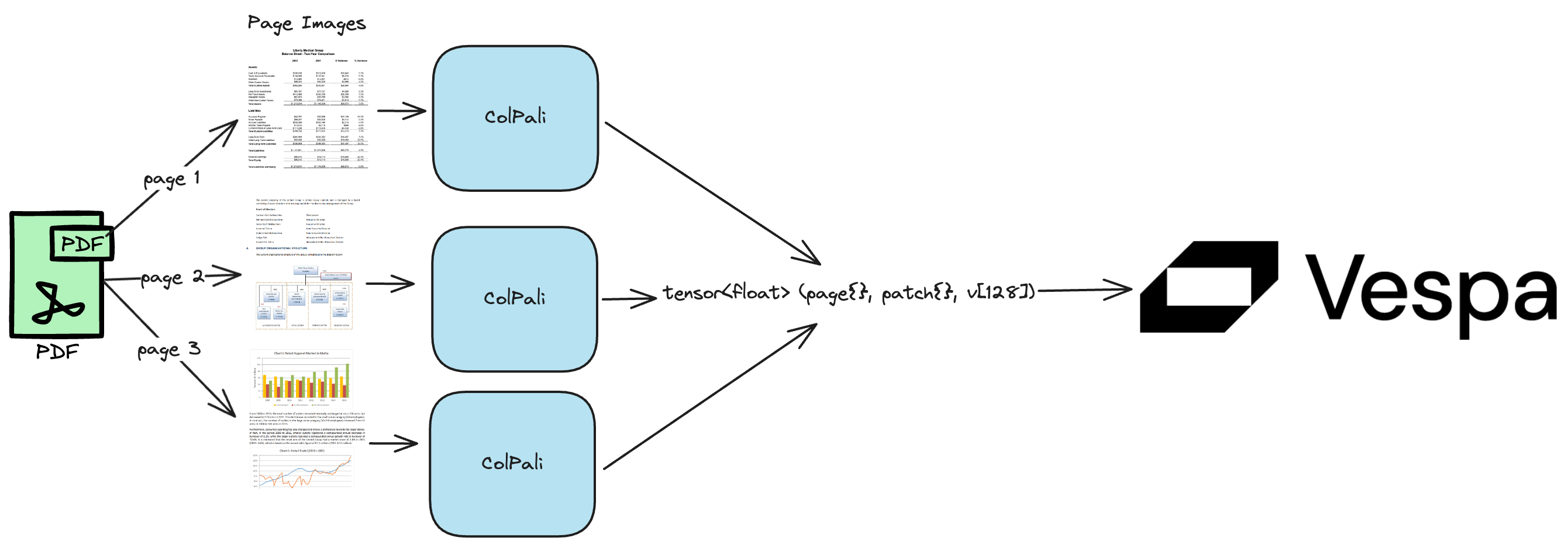 Overview of ColPali + Vespa for PDF retrieval
Overview of ColPali + Vespa for PDF retrieval
In the example notebook, we use the latter approach, one PDF document per Vespa document. For each PDF, extract the screenshot of each page, then for each page obtain the visual ColPali embeddings, finally add the page number as another mapped tensor dimension. With this type of modeling, we do not have to replicate the document-level metadata for each page. In addition, we can also get page level scores for the query, so that we can feed multiple pages into a reader, or display the top-k pages for each document.
PyVespa helps us build the Vespa application package. A Vespa application package consists of configuration files, schemas, models, and code (plugins). The following is an example of a Vespa schema , declared using PyVespa.
from vespa.package import Schema, Document, Field, FieldSet
colbert_schema = Schema(
name="doc", document=Document(
fields=[
Field(name="url", type="string", indexing=["summary"]),
Field(
name="title", type="string", indexing=["summary",
"index"], index="enable-bm25",
), Field(
name="texts", type="array<string>", indexing=["index"],
index="enable-bm25",
), Field(
name="images", type="array<string>", indexing=["summary"],
), Field(
name="colbert", type="tensor<int8>(page{}, patch{},
v[16])", indexing=["attribute"],
)
]
), fieldsets=[FieldSet(name="default", fields=["title", "texts"])]
)
Notice the colbert field is a tensor field with the type
tensor(page{}, patch, v[16]). This is the field where we store the embeddings generated by ColPali.
Ranking
In the demo notebook, we use the following ranking profile, using
phased ranking with BM25 as the first phase (on the entire PDF contents)
and ColPali embeddings as the second phase (on the page-level embeddings). The ColPali embeddings for the query is named
query(qt) and the embeddings for the document is named attribute(colbert). The ColPali query embeddings is obtained by feeding
the query text into the ColPali model, and we name the dimension querytoken{}. Notice that the input is using the full float precision, and
that the unpacking of the binary patch embedding bits is done in the ranking expression.
from vespa.package import RankProfile, Function, FirstPhaseRanking, SecondPhaseRanking
colbert_profile = RankProfile(
name="default",
inputs=[("query(qt)", "tensor<float>(querytoken{}, v[128])")],
functions=[
Function(
name="max_sim_per_page",
expression="""
sum(
reduce(
sum(
query(qt) * unpack_bits(attribute(colbert)) , v
),
max, patch
),
querytoken
)
""",
),
Function(
name="max_sim", expression="reduce(max_sim_per_page, max, page)"
),
Function(
name="bm25_score", expression="bm25(title) + bm25(texts)"
)
],
first_phase=FirstPhaseRanking(expression="bm25_score"),
second_phase=SecondPhaseRanking(expression="max_sim", rerank_count=10),
match_features=["max_sim_per_page", "bm25_score"],
)
colbert_schema.add_rank_profile(colbert_profile)
The PDF documents are ranked by the maximum page score. But, we have access to all the page-level scores using match-features.
The match features allow us to display the top k-pages for each PDF document (or feed them into a reader VLM, or both).
This representation is similar to what we did with Vespa Long-Context ColBERT, and also allows scoring across multiple pages. We named those approaches for context-level MaxSim and cross-context MaxSim. In this case, where we have a page-level visual representation, we could call it page-level MaxSim and cross-page MaxSim using ColPali vector embeddings.
The G in RAG
The demo notebook also demonstrates how we can take the top-k retrieved screenshots and feed those into a powerful Vision LLM, in our case, we use Gemini Flash
import google.generativeai as genai
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])
model = genai.GenerativeModel(model_name="gemini-1.5-flash")
response = model.generate_content([queries[0], image])
With ColPali and Vespa, we can build a complete RAG pipeline for complex document formats like PDFs, using only the visual representation of the document pages.
Conclusion
Using Visual LLMs to represent document texts is a powerful way to simplify the retrieval pipeline for complex document formats. ColPali is a great example of how to leverage the power of Vision LLMs for document retrieval. By directly embedding screenshots of documents, ColPali eliminates the need for complex preprocessing steps and allows for efficient document retrieval. The results on the ViDoRe benchmark demonstrate the effectiveness of ColPali in comparison to traditional text-based retrieval models.
By combining ColPali with Vespa, developers can build powerful RAG pipelines for complex document formats like PDFs, using only the visual representation of the document pages. Also, if we extract text from the PDFs, like we do in the demo notebook, developers can filter and rank based on the text content, for example filtering by date, author, or other metadata. Features, that come out of the box with Vespa.
A nice property of Vespa is the tensor framework with its optimized tensor compute engine, allowing representing more complex models like ColPali in Vespa without custom plugins, extensions or development time.
FAQ
What about other complex formats like HTML, Word, etc?
The ColPali model was trained on portraiture PDFs, but the model can be fine-tuned on other complex document formats like HTML, Word, etc. By training the model on a diverse range of documents, you can ensure that it performs well on documents in multiple formats. We can see this as a promising direction for retrieval over complex document formats.
Can ColPali handle documents in languages other than English?
Like other Vision LLMs, ColPali can be fine-tuned on documents in any language. By training the model on a diverse range of documents, you can ensure that it performs well on documents in multiple languages.
Can the model adapt to new tasks? Contrary to more complex multi-step retrieval pipelines, ColPali can be trained end-to-end, directly optimizing the downstream retrieval task which greatly facilitates fine-tuning to boost performance on specialized domains, multilingual retrieval, or specific visual elements the model struggles with. To demonstrate, we add 1552 samples representing French tables and associated queries to the training set. This represents the only French data in the training set, with all other examples being kept unchanged.
Quote from 2.
How does ColPali handle documents with multiple pages?
ColPali does not handle multi-page documents, it’s trained on the page level image. As we demonstrate, we can adapt this by
using another tensor dimension to represent the page, tensor<float>(page{}, patch{}, v[128]).
Can ColPali be used with other retrieval models?
Yes, ColPali can be combined with other retrieval models to enhance performance. By using ColPali embeddings as an additional feature in your retrieval pipeline, you can improve the accuracy of your document retrieval system. This also includes using the ColPali embeddings as “just a feature” in GBDT or other models.
What is a patch?
A patch is a grid cell in the image.
What about the size of the embeddings?
The model produces 1030 patch embeddings per image, with 128-dimensional embedding per patch. With bfloat16 this is 256KB of data. Using binarization, we can reduce this to 8KB.
What about the size of the ColPali model and inference complexity
The model has about 3B parameters, less than many popular text embedding models. Encoding a short query is much faster than encoding the image page.
What is the base model?
The base model is PaliGemma 3, a powerful visual language model, released by Google. The model is gated and has resource usage limitations.
What about interpretability of the model?
One nice property of MaxSim is that one can compare the query token vector representation with the patch embeddings and find which areas (grid cells or patches) of the page screenshot that contribute most to the score (per query term vector).
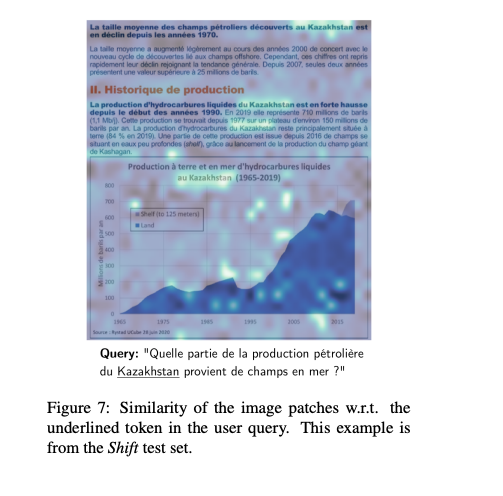
Interpretability analysis. Screenshot from paper 2
How can I evaluate the model on my data?
Like any other retrieval model, you can build your own evaluation dataset. This is the only way you can say if something works better than something else for your own data. As in the benchmark, they compare text-only models with ColPali, you can do the same with your data.
How do you store the image data in Vespa?
We use base64 encoding to store the image data as a string field in Vespa. This allows us to store the image data directly in the Vespa document. This field is only used for summary purposes, and the actual embeddings are stored in the tensor field.
In the demo notebook, you use BM25 for first-phase retrieval, why?
Because BM25 is a strong baseline model that is cheap to compute and can be used as a first phase in a phased ranking pipeline. Additionally, we do not need to build index structures for efficient retrieval over ColPali embeddings, but can still use them in ranking phases (and without moving vector data around).
I really do not want to use text extraction for BM25
You can use the ColPali embeddings for end-to-end retrieval and ranking as well, see this notebook for inspiration of how to use ColBERT embeddings for end-to-end retrieval and ranking in Vespa.
I really want to try this out, where can I find the demo notebook?
It’s available here, also checkout other resources:
I have more questions; I want to learn more!
For those interested in learning more about Vespa or ColBERT, join the Vespa community on Slack or Discord to exchange ideas, seek assistance from the community, or stay in the loop on the latest Vespa developments.
