


Photo by Simon Connellan on Unsplash
HTTP/2 support was recently added to Vespa, and makes this new and improved protocol available for both search and feed endpoints, as well as custom endpoints implemented by users. This blog post covers what you need to know about configuring and getting started with HTTP/2, and gives an example of how this enables efficient feeding over HTTP from any client runtime.
Why HTTP/2
The HTTP/2 specification was primarily motivated by performance limitations in HTTP/1.1. HTTP/2 allows more efficient network usage, with features like header compression, which reduces overall traffic and latency; and multiple, concurrent requests over the same TCP connection, which solves the infamous head-of-line-blocking problem of HTTP/1.1.
Security is another aspect improved upon in HTTP/2. The specification requires implementations to only allow Transport Layer Security (TLS) version 1.2 or newer. Less secure features and weaker cipher suites from TLSv1.2 are not allowed. Most browser vendors have taken an aggressive stance on security by supporting HTTP/2 over TLS only.
Adding HTTP/2 support to Vespa
Update 2022-02-16: HTTP/2 without TLS is supported since 7.462.20
Jetty 9.4 is the HTTP stack powering the Vespa Container. As Jetty 9.4 has supported HTTP/2 for many years already, implementing HTTP/2 support for Vespa Container was more or less straightforward, with high performance out of the box. Like for most web browsers, we decided to adopt HTTP/2 over TLS only, although for slightly different reasons:
- Firstly, Vespa at Verizon Media and Vespa Cloud is required to implement all Vespa protocols—both container HTTP handlers, and all internal Vespa protocols—on top of mutually authenticated TLS.
- Secondly, the TLS Application-Layer Protocol Negotiation Extension (ALPN) provides a solid mechanism for a client and server to negotiate a compatible application protocol, allowing the Vespa Container to serve both HTTP/1.1 and HTTP/2 from the same port.
HTTP/2’s TLSv1.2 cipher suite blocklist posed no problem, as Vespa by default disallows all of those ciphers.
Vespa HTTP/2 performance
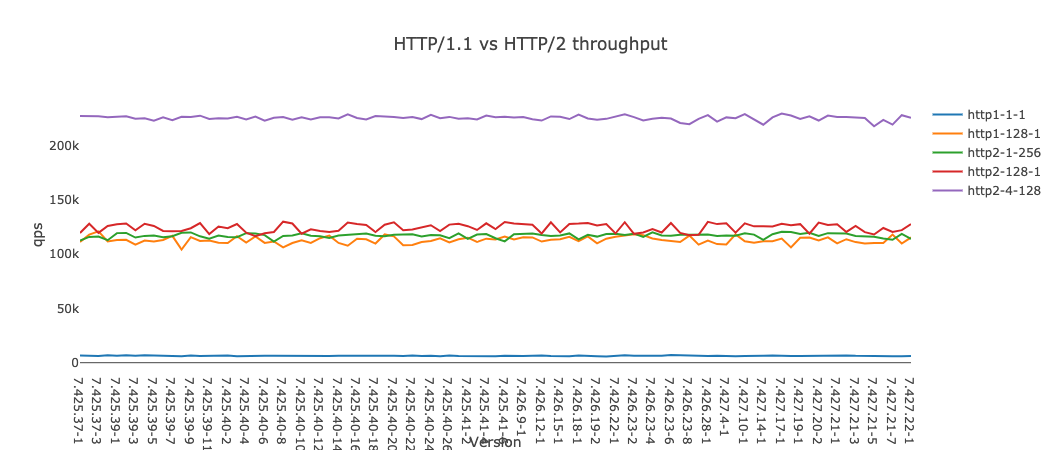
To compare the throughput of HTTP/1.1 vs HTTP/2 in the Vespa container, we measured the rate of HTTP requests (QPS) we could obtain on a single node with 48 CPU cores and 256GB RAM, using h2load as a benchmarking tool. As expected, single connection throughput increased significantly with HTTP/2. HTTP/2 with 256 concurrent streams gave a throughput of 115 000 requests per seconds compared to 6 500 for HTTP/1.1. Increasing the number of connections from 1 to 128 increased throughput to 115 000 for HTTP/1.1, while HTTP/2 gave 125 000 with the same setup (without request multiplexing). HTTP/2 was also more efficient, with lower CPU utilization—a consequence of its compact protocol representation and header compression. The highest throughput for HTTP/2 was observed with 4 clients and 256 concurrent streams. This configuration resulted in 225 000 requests per seconds—roughly double the best case for HTTP/1 (128 connections). The h2load tool was CPU constrained for the single connection benchmark as it could only utilize a single CPU core per connection. Having 4 connections removed the CPU bottleneck. Increasing beyond 4 connections resulted in gradually more overhead and degraded throughput.
Simple, yet effective feeding over HTTP/2 against /document/v1
/document/v1 is a REST-ified
HTTP API which exposes the Vespa Document API to
the outside of the application’s Java containers. The design of this API is simple: each feed operation
is modelled as a single HTTP request, and its result as a single HTTP response. While it was previously
not possible to achieve comparable throughput using /document/v1 to what the
Vespa HTTP Client could achieve against the internal,
custom-protocol /feedapi, this changed with HTTP/2 support in Vespa, and /document/v1 is
the recommended choice for anyone who wishes to implement their own feed client over HTTP.
High throughput requires many in-flight operations
While the /search API typically needs to serve low-latency results,
feeding is often instead optimized for throughput. This may require a large number of feed operations to be
processed concurrently, particularly when doing
asynchronous document processing.
/document/v1 is backed by an asynchronous HTTP handler, and allows thousands of concurrent feed operations,
when paired with an asynchronous HTTP client; however, having a large number of in-flight HTTP requests used
to also require many connections:
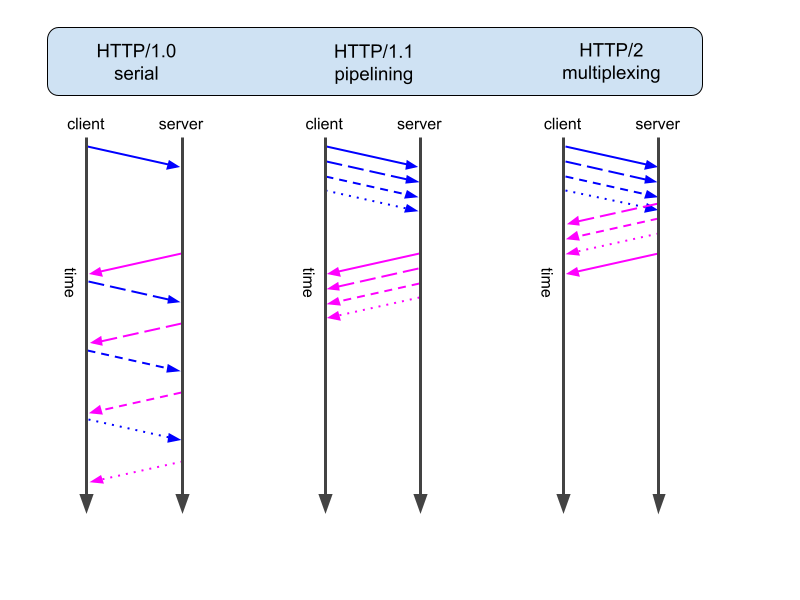
- The HTTP/1.0 protocol allows a single HTTP request and HTTP response to be in transit over one TCP connection at any time. This means each in-flight feed operation requires a separate TCP connection, which becomes inefficient once the number of concurrent operations reaches into the hundreds.
- HTTP/1.1 allows for several requests to be fired off in sequence, before any responses arrive on the same connection, but this requires the responses to arrive in precisely the same order as the requests. If a single response is delayed for any reason—perhaps the feed operation hits a bad content node, or it just takes a long time to process asynchronously—all subsequent responses on that connection are delayed by the same amount, as they have to wait for that slow response to be sent first. Under ideal circumstances, HTTP pipelining may allow for a decent number of concurrent feed operations per connection; alas, the world is not always ideal.
- HTTP/2 improves upon the pipelining of HTTP/1.1 by providing true request and response multiplexing across each TCP connection, i.e., any (sane) number of requests and responses may be in flight at the same time, independently of each other.
Thus, HTTP/2 efficiently allows hundreds, or even thousands, of feed operations concurrently over each TCP connection, making it possible to saturate the Vespa cluster without too many connections. Additionally, HTTP/2 is just a more efficient protocol than HTTP/1, which also gives some CPU and latency savings.
Implementing an asynchronous feed client
This section demonstrates how a feed client could be implemented, for any readers interested in contributing to the vespa.ai project.
Ordering feed operations for correctness
When issuing multiple operations against a single document, it may be required that these be applied in the order they are issued. The Java Document API (in the container) guarantees this for operations with a common document ID, when these are sent through a single client; however, this is of little help when feeding from the outside of the feed container cluster, as:
- a request may hit any container, i.e., hit any document API client;
- it may be throttled and retried, thus arriving after a feed operation which was later in the feed sequence; or
- it may even be overtaken in the HTTP layer (client, transport, handler), by later requests.
Thus, feed operations to a common document must be serialised by (the single) feed client, by waiting for the (final) result of each operation before sending the next. This must include waiting for retries.
An asynchronous example
Let http be an asynchronous HTTP/2 client, which returns a future for each request. A future will
complete some time in the future, at which point dependent computations will trigger. A future is obtained
from a promise, and completes when the promise is completed. An efficient feed client is then:
inflight = map<document_id, promise>()
func dispatch(operation: request, result: promise, attempt: int): void
http.send(operation).when_complete(response => handle(operation, response, result, attempt))
func handle(operation: request, response: response, result: promise, attempt: int): void
if retry(response, attempt):
dispatch(operation, result, attempt + 1)
else:
result.complete(response)
func enqueue(operation): future
result_promise = promise()
result = result_promise.get_future()
previous = inflight.put(document.id, result) # store result under id and obtain previous mapping
if previous == NULL:
while inflight.size >= max_inflight(): wait()
dispatch(operation, result, 1)
else:
previous.when_complete(ignored => dispatch(operation, result, 1))
result.when_complete(ignored => inflight.remove_value(result)) # remove mapping unless already replaced
return result
Apply synchronization as necessary. The inflight map is used to serialise multiple operations to the same
document id: the mapped entry for each id is the tail of a linked queue where new dependents may be added,
while the queue is emptied from the head one entry at a time, whenever a dependency (previous) completes
computation. enqueue blocks until there is room in the client.
Our Java implementation
The above design, with added dynamic throttling for optimal performance, is the one used in the new Java feed client. The below figure shows feed throughput for a single-node Vespa installation, using this feed client.
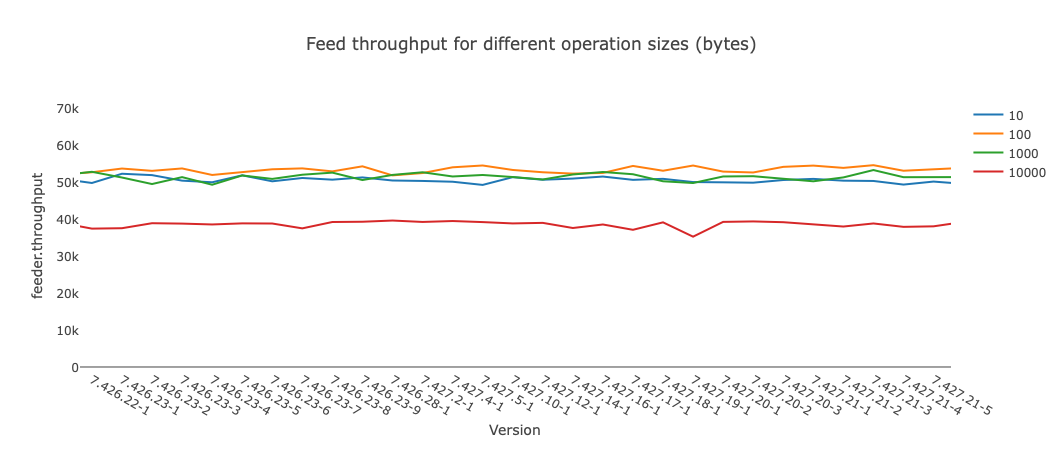
Unsurprisingly, each HTTP request has some overhead, which limits the throughput when operation size falls below a given threshold. More surprisingly, we find by far most of the overhead to be on the client side. Our implementation uses the Apache HTTP client, and we can hope that this overhead is reduced as the library’s HTTP/2 support matures.
Getting started with HTTP/2
Vespa enables HTTP/2 by default - consult our HTTP/2 documentation for details.
- Upgrade your Vespa installation to 7.425 or newer.
- Add a
serverelement in services.xml with HTTPS/TLS.- Make sure TLS version or cipher suites are HTTP/2 compatible if specified.
<?xml version="1.0" encoding="utf-8" ?>
<services version="1.0">
<container version="1.0" id="default">
<http>
<server id="default" port="8080"/>
<server id="tls" port="443">
<ssl>
<private-key-file>/path/to/private-key.pem</private-key-file>
<certificate-file>/path/to/certificate.pem</certificate-file>
<ca-certificates-file>/path/to/ca-certificates.pem</ca-certificates-file>
</ssl>
</server>
</http>
<document-api/>
</container>
</services>
Verify that HTTP/2 is enabled with for instance curl or nghttp:
$ nghttp --verbose https://localhost:443/
$ curl --http2 --verbose https://localhost:443/
Feeding with vespa-feed-client
The new Java feed client is available as both as a Java library and command line utility. Consult the vespa-feed-client documentation for details.
$ vespa-feed-client --file /path/to/json/file --endpoint https://localhost:443/ --connections 4
try (FeedClient client = FeedClientBuilder.create(URI.create("https://localhost:443/")).build()) {
DocumentId id = DocumentId.of("namespace", "documenttype", "1");
String json = "{\"fields\": {\"title\": \"hello world\"}}";
CompletableFuture<Result> promise = client.put(id, json, OperationParameters.empty());
promise.whenComplete(((result, error) -> {
if (error != null) {
error.printStackTrace();
} else {
System.out.printf("'%s' for document '%s': %s%n", result.type(), result.documentId(), result.resultMessage());
}
}));
}
So, upgrade your Vespa installation to 7.425+ and try out HTTP/2 with the new feed client, or even write one yourself! We would be most delighted to receive your feedback!