
In the previous update, we mentioned features for high-quality Generative AI retrieval (including integrated chunking), elementwise rank features, facet filtering in Vespa Grouping, and Pyvespa Match Evaluator. Today, we’re excited to share the following updates:
- Approximate Nearest Neighbor (ANN) Tuning Parameters
- Binary Data Detection in String Fields
- Filtering in Grouping
- Geo Filtering using geoBoundingBox
- Global Ranking: relevanceScore
- Layered Ranking: Working with Chunks
- Pyvespa Enhancements
- Summary-Features: Multiple Inheritance
- Vespa Cloud: Automatic Instance Migration
Approximate Nearest Neighbor (ANN) Tuning Parameters
As part of the ongoing improvements to Vespa’s HNSW implementation for vector search, we’ve introduced three new (ACORN-1 and Adaptive Beam Search) parameters:
- filterFirstThreshold: Specifies the threshold for applying a filter before computing vector distances when searching the HNSW graph. If the condition is met, filters are applied before distance calculations, which reduces unnecessary computations and improves performance in ANN queries with strong filters.
- filterFirstExploration: Specifies how much of the graph is traversed before applying the filter, helping tune recall vs. performance trade-offs.
- explorationSlack – Defines the slack factor for HNSW search termination. A higher value allows the search to continue exploring beyond the first “good enough” candidates, which can improve recall (especially with filters), while a lower value stops earlier for lower latency.
These parameters can be set both at query time and inside a rank profile, giving you precise control over how Vespa balances recall, latency, and cost in ANN queries, which is particularly important when combining vector search with structured filters.
Read more in A Short Guide to Tweaking Vespa’s ANN Parameters and Additions to HNSW in Vespa: ACORN-1 and Adaptive Beam Search Also, we encourage you to test these parameters in your workloads and share feedback in the Vespa Slack community.
Binary Data Detection in String Fields
Feeding messy or corrupted data into GenAI pipelines can cause performance issues and unpredictable errors. Vespa now automatically detects and rejects binary data hidden inside string fields, helping to keep your applications stable, secure, and reliable.
What it means for you:
- Cleaner inputs: Prevents corrupted or malformed strings from slipping through.
- Enterprise-ready: Designed for real-world GenAI workloads where “anything” might be fed into the system.
- Better reliability: Avoids costly out-of-memory errors and reduces downtime risks.
This is enabled by default in Vespa Cloud and Vespa OSS. To disable the feature, set the system environment variable VESPA_DISABLE_LINGUISTICS_BINARY_CHECK to “false”.
Filtering in Grouping
In the last newsletter, we announced the filtering feature in grouping (a.k.a. faceting). Since Vespa 8.569, you can now apply filters directly inside grouping expressions using logical predicates (and, not, etc.) and range filters. For example, you can group purchases by customer while excluding specific sales reps or price ranges, all in a single query.
all(group(customer)
filter(
regex("Bonn.*", attributes{"sales_rep"})
and not range(0, 1000, price) )
each(output(sum(price)) each(output(summary()))))
You can also set a timezone when using time functions, using the timezone parameter, so analytics like “purchases by hour” reflect the correct business context.
$ vespa query "select * from purchase where true | \
all( group(time.hourofday(date)) each(output(count()))" \
"timezone=America/Los_Angeles"
What it means for you:
- Simpler syntax: Grouping and filtering are expressed together.
- Fewer queries: No need to nest multiple aggregations and filters.
- Faster at scale: Less overhead and lower latency for real-time faceting.
Geo Filtering using geoBoundingBox
Vespa 8.568 introduced the geoBoundingBox operator, letting you filter results to a rectangular region on a map. It works alongside existing point + radius geo filters and integrates seamlessly with Vespa’s ranking features.
The following image displays filtering results by region. Refer to the closeness(name) and distance(name) rank features to rank results by distance, including an optional logarithmic fall-off.
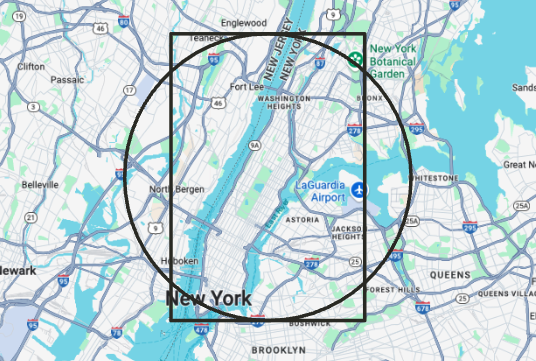
What it means for you:
- Filter by rectangle: Perfect for map views, delivery zones, or neighborhood searches.
- Rank by distance: Combine with closeness or distance rank features to order results by proximity, with optional fall-off.
- Do it all in one query: Unlike other platforms that separate filtering and distance ranking, Vespa lets you handle both together for simpler queries, less overhead, and faster results.
Global Ranking: relevanceScore
In Vespa 8.559, we introduced relevanceScore, which captures the score assigned to each document during first- or second-phase ranking. You can now access this value in the global ranking phase (e.g., for cross-node reordering or reranking). Note that it cannot be referenced inside the first- or second-phase ranking expressions themselves.
Thanks to dainiusjocas for submitting #34525!
Layered Ranking: Working with Chunks
In June, we introduced layered ranking for RAG applications, a powerful way to break documents into smaller chunks and retrieve only the most relevant parts. This improves both accuracy and efficiency by focusing on the pieces of content that actually matter to the query.
To help you get started, we’ve published a new Working with Chunks guide, covering everything from schema setup and vector embedding creation to searching, ranking, and selecting the right chunks to return.
Pyvespa Enhancements
We’re continuing to enhance Pyvespa, making it easier to build, deploy, and experiment with Vespa applications directly from Python.
Since our last newsletter, here are the key improvements:
- VespaFeatureCollector: A new convenience class to quickly collect training data from your Vespa application. (See it in action in The RAG Blueprint).
- Fetch application packages from Vespa Cloud: You can now get your full application package or just the schemas from an existing Vespa Cloud app.
- Deploy to performance environments: Added support for deploying directly to Vespa Cloud’s perf-environment for easier testing.
- Schema & config improvements: Pyvespa now supports expressing any `indexing`-statement in a schema, as well as any `deployment.xml`-configuration configuration.
We’re steadily moving toward the goal of being able to define any Vespa application entirely in Python code. If you run into areas where Pyvespa doesn’t yet support your use case, let us know by creating a GitHub issue.
Summary-Features: Multiple Inheritance
You can now inherit summary-features from multiple rank profiles, making ranking setups more flexible and reusable. Summary features are rank features computed during ranking and returned in query results. This is useful for debugging (by exposing intermediate values) or for powering application logic that depends on more than just the final rank score. With this update, when you inherit from multiple rank profiles, Vespa now also carries over their summary-features, giving you more flexibility and consistency in building complex ranking strategies without redundant definitions.
What it means for you:
- For developers: Less duplication and easier debugging—no need to redefine summary-features when combining profiles.
- For businesses: Faster iteration on ranking strategies and more consistent relevance across applications.
- For applications: Access to richer signals (beyond the final rank score) to improve personalization, explainability, and user experience.
Vespa Cloud: Automatic Instance Migration
Cloud providers (AWS, GCP, Azure) regularly release new instance types and CPU generations that deliver better price-to-performance. Starting June 2025, Vespa Cloud will automatically migrate your nodes to newer generations as they become available, with no manual intervention required.
What this means for you:
- Better performance: Take advantage of the latest hardware without lifting a finger.
- Cost efficiency: Newer instance types often deliver more compute for the same or lower price.
- Zero disruption: Migrations happen seamlessly, keeping your applications online.
New Content
Examples and notebooks:
- Vespa Quickstart - How to build an application with Vespa
Videos, Webinars, and Podcasts
- Video: Vespa Architecture Overview
- Video Podcast: From Legacy to Leading Edge: Vinted’s Journey to Data Modernisation
- Webinar: Leveraging Data Beyond Text: Multi-Modal AI at Scale
- Demo: Real-Time AI for Smarter Product Discovery
Blogs and Ebooks
- A Short Guide to Tweaking Vespa’s ANN Parameters
- Additions to HNSW in Vespa: ACORN-1 and Adaptive Beam Search
- Case study: Using Vespa Cloud Resource Suggestions to optimize costs
- Exploring Hierarchical Navigable Small World
- Introducing Private Embedding Models in Vespa Cloud
- Building the Next-Gen Diligence Engine: Why 8byte is Partnering with Vespa
- The secret to Perplexity’s lead in AI Search
- Vespa Implementation Services: From Migration to Production Scale
- Unlocking Next-Gen RAG Applications for the Enterprise: Connecting Snowflake and Vespa.ai
Upcoming Events
- AI in Financial Services London: September 9–10, 2025
- (Webinar) Lessons on Making AI Work in Life Sciences and breaking the Chatbot Mirage: September 10, 2025 10:00am ET
- AWS Summit Los Angeles: September 17, 2025
- AICamp - Data and model interaction - how GenAI apps are built:
- London Oct 1
- Berlin Oct 8
- Paris Oct 9
- Boston Oct 15
- New York City Oct 16
- San Francisco Oct 23
👉 Follow us on LinkedIn to stay in the loop on upcoming events, blog posts, and announcements.
Thanks for joining us in exploring the frontiers of AI with Vespa. Ready to take your projects to the next level? Deploy your application for free on Vespa Cloud today.