
In the previous update, we mentioned Pyvespa and Vespa CLI improvements, Improved multi-threading performance with text matching, Chinese segmentation, improved English stemming, and new ranking features. Today, we’re excited to share the following updates:
- Optimized MaxSim with Hamming distance for multivector documents
- Pyvespa
- IDE support
Optimized MaxSim with Hamming distance for multivector documents
The Vespa Tensor Ranking framework lets users write arbitrarily complex ranking functions. Multi-vector MaxSim is increasingly important for many use cases, see scaling-colpali-to-billions for an example:
model max_sim {
inputs {
query(qt) tensor<float>(q{}, v[128])
}
function max_sim(query, page) {
expression {
sum(
reduce(
sum(
query * page , v
),
max,
p
),
q
)
}
}
first-phase {
expression: max_sim(query(qt), attribute(embedding))
}
}
From Vespa 8.404, this operation is optimized with Hamming distance using int8, to support bit-resolution embeddings - this is a 32x reduction in memory usage compared to floats. Tests show a 30x reduction in latency:
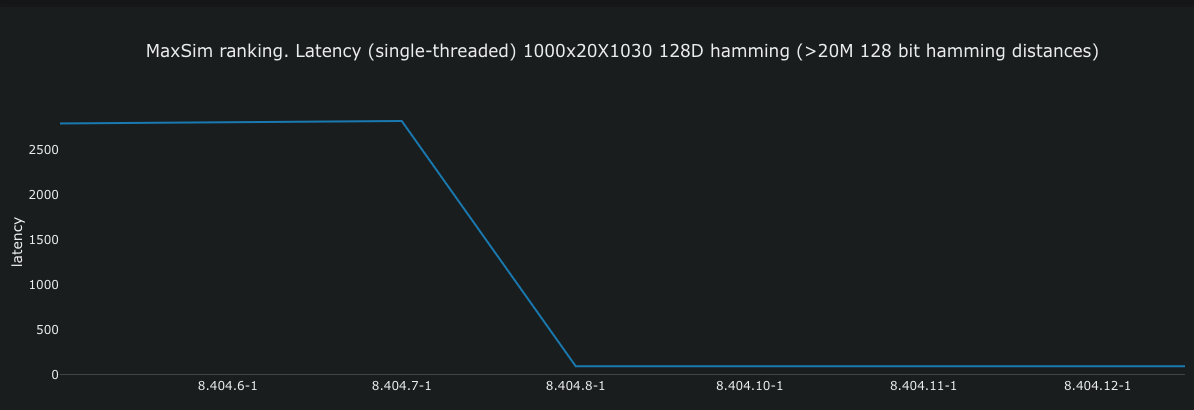
In Vespa, the Multivector MaxSim similarity is a dot product between all the query token embeddings and all the chunk/patch embeddings, followed by a max reduce operation over the chunk/patch dimension, followed by a sum reduce operation over the query tokens. Read more in #32232 Optimize MaxSim with hamming (sum of max inverted hamming distances).
Pyvespa
Pyvespa 0.49 has been released, highlights:
- Pyvespa query performance to Vespa Cloud is improved by eliminating redundant authentication calls - see #894 infer auth method without request.
- With the new compress argument (defaults to “auto”), Pyvespa will compress feed and query operations if the body is larger than 1024 bytes - see #914 expose “compress” argument.
- Add rank to StructField in #913 Add rank to StructField.
We have also revamped and added to the notebooks, particularly new ones about ColPali! We also recommend the original paper at ColPali: Efficient Document Retrieval with Vision Language Models.
For those interested in full release details, check out github.com/vespa-engine/pyvespa/releases. Thanks to these external contributors for adding to Pyvespa since the last newsletter!
IDE support
Vespa provides plugins for working with schemas and rank profiles in IDE’s:
- VSCode: VS Code extension
- IntelliJ, PyCharm or WebStorm: Jetbrains plugin
- Vim: neovim
See the documentation for details, and read the blog post for how our 2024 summer interns created them!
Other
From Vespa 8.411, Vespa uses ONNX Runtime 1.19.2
New posts from our blog
- AI Needs More Than a Vector Database
- Scaling ColPali to billions of PDFs with Vespa
- Parsing Through the Summer: A Tale of Schemas, Syntax, and Shenanigans
Other companies blogging about how and why they build on Vespa
- From Vinted Engineering by Ernestas Poškus: Vinted Search Scaling Chapter 8: Goodbye Elasticsearch, Hello Vespa Search Engine. “The migration was a roaring success. We managed to cut the number of servers we use in half (down to 60). The consistency of search results has improved since we’re now using just one deployment (or cluster, in Vespa terms) to handle all traffic. Search latency has improved by 2.5x and indexing latency by 3x. The time it takes for a change to be visible in search has dropped from 300 seconds (Elasticsearch’s refresh interval) to just 5 seconds. Our search traffic is stable, the query load is deterministic, and we’re ready to scale even further.”
- Guest blog post by Yuhong Sun, CoFounder/CoCEO Danswer: Why Danswer - the biggest open source project in Enterprise Search - uses Vespa. “We chose Vespa because of its richness of features, the amazing team behind it, and their commitment to staying up to date on every innovation in the search and NLP space. We look forward to the exciting features that the Vespa team is building and are excited to finalize our own migration to Vespa Cloud.”
Events
- Haystack EU 2024 Berlin, September 30, Jo Kristian Bergum: What You See Is What You Search: Vision Language Models for PDF Retrieval
- MLCon, New York, October 8, Kristian Aune: Retrieval and Adaptive In-Context Learning - the fastest flywheel
- Data Science Connect, COLLIDE 2024, Atlanta, October 10, Kristian Aune: Using In-Context Learning to Get Started With AI, Safely
- GenAI Summit Silicon Valley 2024, Santa Clara, November 1, Jon Bratseth
- DataScienceSalon, San Francisco, November 7, Jon Bratseth: Roundtable
Thanks for joining us in exploring the frontiers of AI with Vespa. Ready to take your projects to the next level? Deploy your application for free on Vespa Cloud today.