
In the previous update, we mentioned Vespa 8, pre/post ANN filtering support, fuzzy matching, pyvespa experimental ranking module, embedding support and new tensor features Today, we’re excited to share the following updates:
Rank-phase statistics
With rank-phase statistics it is easy to measure relative query performance on a per-document-level, like “Which documents appear most often in results, which ones never do?”. The statistics are written in configurable attributes per document, for analysis using the Vespa query- and aggregation APIs. Use this feature for real-time tracking of ranking performance, and combine with real-time updates for tuning.
Schema feeding flexibility
Since Vespa 8.20, a document feed can contain unknown fields using ignore-undefined-fields. While the default behavior is to reject feeds with unknown fields, this can make it easier to optimize or evolve the schema to new use cases, with less need to coordinate with client feeds.
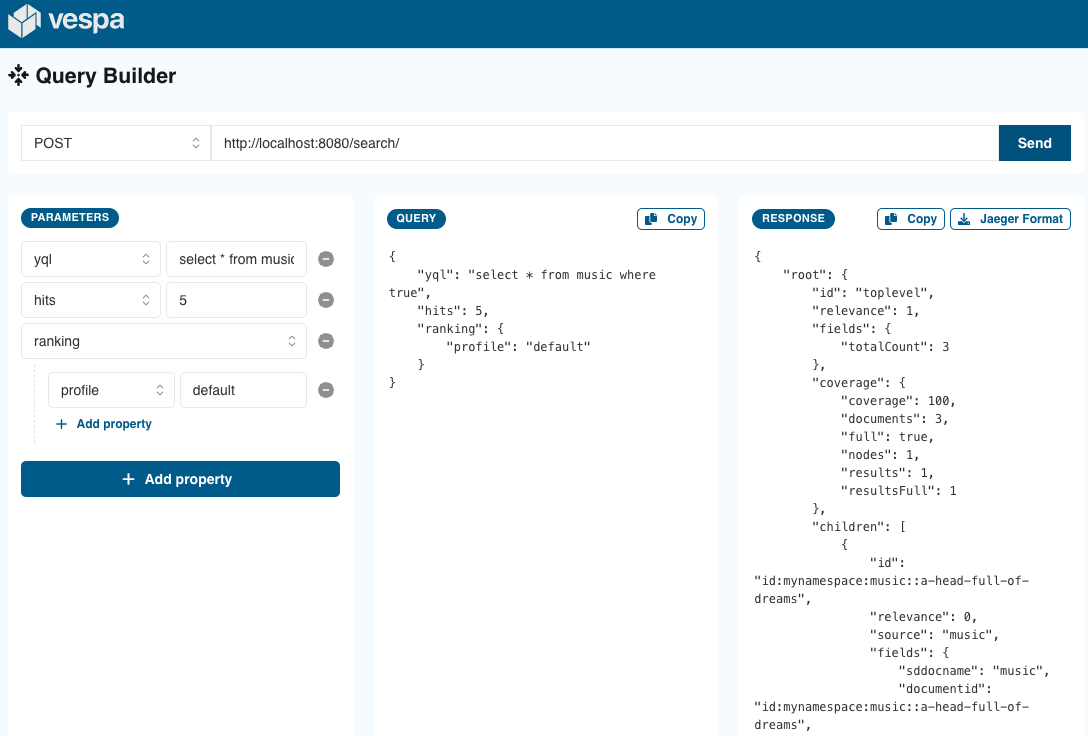
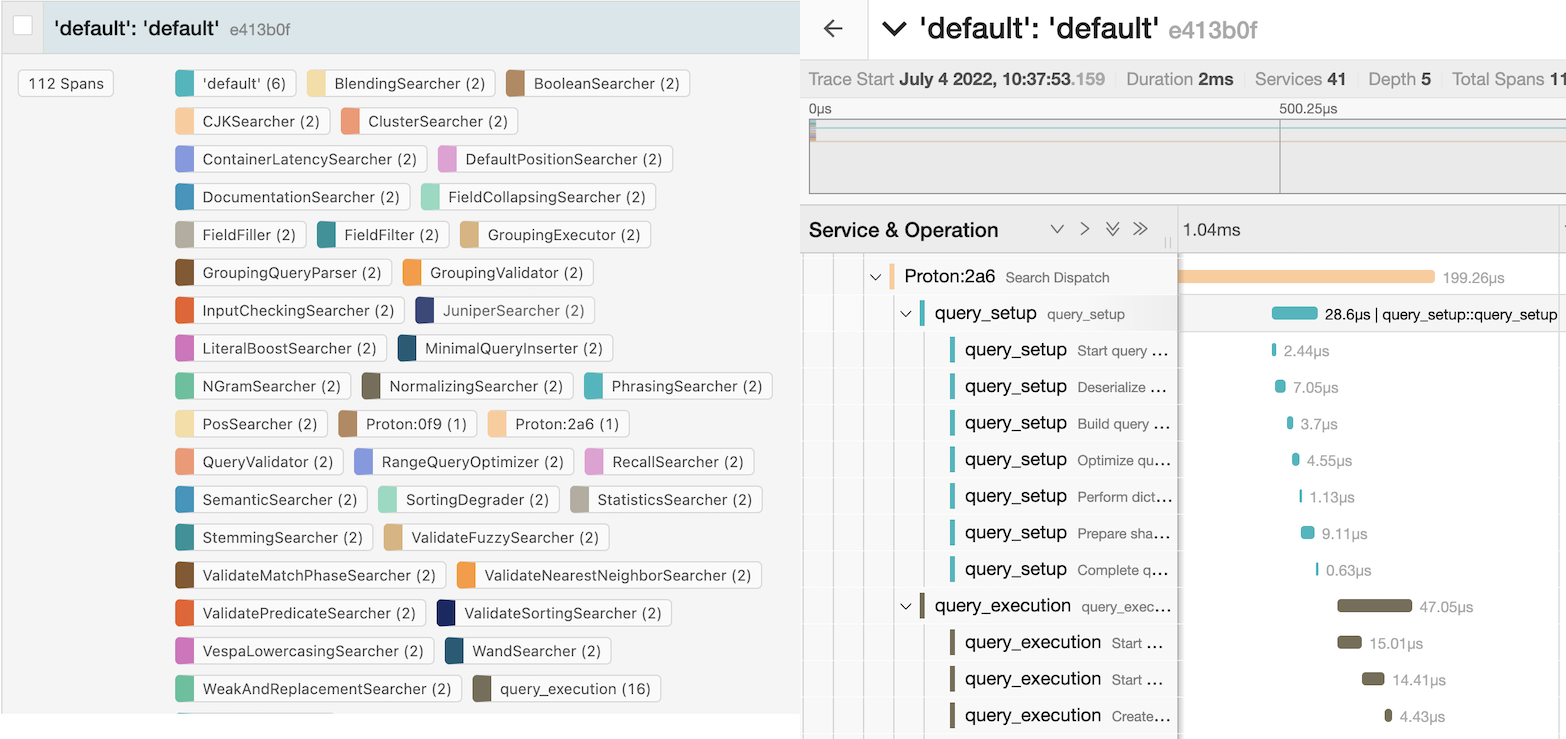
Beta: Query Builder and Trace Visualizer
New beta applications for building queries and analyzing query traces available at github.com/vespa-engine/vespa/tree/master/client/js/app. This is the first step towards helping users experiment easily with queries, and the Trace Visualizer can be used to help pinpoint query latency bottlenecks.
Rank trace profiling
Use rank trace profiling to expose information about how time spent on ranking is distributed between individual
rank features.
Available since Vespa 8.48,
use trace.profileDepth
as a query parameter, e.g. &tracelevel=1&trace.profileDepth=10.
This feature can be used for content node rank performance analysis.
Feeding bandwidth test
When doing feeding throughput tests, it can often be hard to distinguish latency inside your Vespa application
vs. validating the available bandwidth between client and server.
Since Vespa 8.35, the vespa-feed-client
supports the --speed-test parameter for bandwidth testing.
Note that both client and server Vespa must be on 8.35 or higher.
Training video
Vespa allows plugging in your own Java code in both the document- and query-flows, to implement advanced use cases. Using query tracing and a debugger can be very useful in developing and troubleshooting this custom code. For an introduction, see Debugging a Vespa Searcher:
