
In the previous update, we mentioned Optimized MaxSim with Hamming distance, new Pyvespa features, and improved IDE Support with plugins. Today, we’re excited to share the following updates:
- Vespa Open Source Virtual Meetup
- Global significance models
- Nearest Neighbor Search with multiple sparse tensor dimensions
- New Pyvespa features
- Application metrics dashboard
Inaugural Vespa Open Source Virtual Meetup
👏 Welcome to the first Vespa Community webinar! Items on the agenda are Roadmap, Key Features, and Cloud - use this to learn about the future of Vespa, and post your questions in the Q&A section to tell the Vespa team what is important to you! This session will be hosted by Jon Bratseth, Vespa’s Co-Founder and CEO, making it an excellent opportunity to connect and get answers directly from the source. November 19 - use vespa.ai/events to register.
Global significance models
We are excited to announce support for global significance models in Vespa 8.426.8. This feature improves ranking for streaming mode* and ensures deterministic results in multi-node deployments using indexed mode.
Significance measures how rare a term is in a collection of documents. Rare terms, like “neurotransmitter”, are weighted higher in ranking than common terms, such as “body”. Significance is used in rank features such as BM25 and nativeRank.
By default, Vespa calculates significance values locally on each content node, based on the documents stored on that node. This makes ranking non-deterministic as the same query may be processed by different node groups or when documents are redistributed due to scaling or failure recovery. In addition, local significance is not supported in streaming search.
To address these scenarios, we introduce support for global significance models that share significance values across all content nodes, which also works in streaming search. Read more in the announcement.
*Streaming mode / streaming search is a feature optimized for applications searching a fraction of the total space, like personal search (your data only). As this feature is index-free, it is optimized for cost and write performance.
Nearest Neighbor Search with multiple sparse tensor dimensions
The nearestNeighbor query operator (NN)
matches the top-k nearest neighbors in a multidimensional vector space.
Points in the vector space are specified as tensors with one indexed dimension.
Since Vespa 8.417.13, multiple sparse dimensions are supported.
Before you could index e.g. tensor<float>(chunk{}, x[16]),
now you can also index tensor<float>(page{},section{},chunk{}, x[16]).
This lets you model the structure of your data in indexed tensor so that you can filter and rank depending on matches in these dimensions, see the example in #29587.
New Pyvespa features
Since 0.50, Pyvespa supports ServiceConfiguration - use this to configure any option also found in Vespa’s services.xml. Example:
services_config = ServicesConfiguration(
application_name=application_name,
services_config=services(
container(
search(),
document_api(),
document_processing(),
id=f"{application_name}_container",
version="1.0",
),
content(
redundancy("1"),
documents(
document(
type=application_name,
mode="index",
selection="music.timestamp > now() - 86400",
),
garbage_collection="true",
),
nodes(node(distribution_key="0", hostalias="node1")),
id=f"{application_name}_content",
version="1.0",
),
),
)
Read more in advanced configuration.
v0.50.0 has the complete list of features and bug fixes. Thanks to @velaia (#940) and @ulyanin (#952) for making their first contributions to Pyvespa!
We also recommend trying out PDF-Retrieval using ColQWen2 (ColPali) with Vespa - this notebook gets you started with Visual Language Models!
Application metrics dashboard in the Vespa Cloud console
We have launched a new metrics dashboard for tenant users in the Vespa Cloud console. Grafana Cloud powers the dashboard and is available through the Metrics tab for any application instance in the applications view in the console:
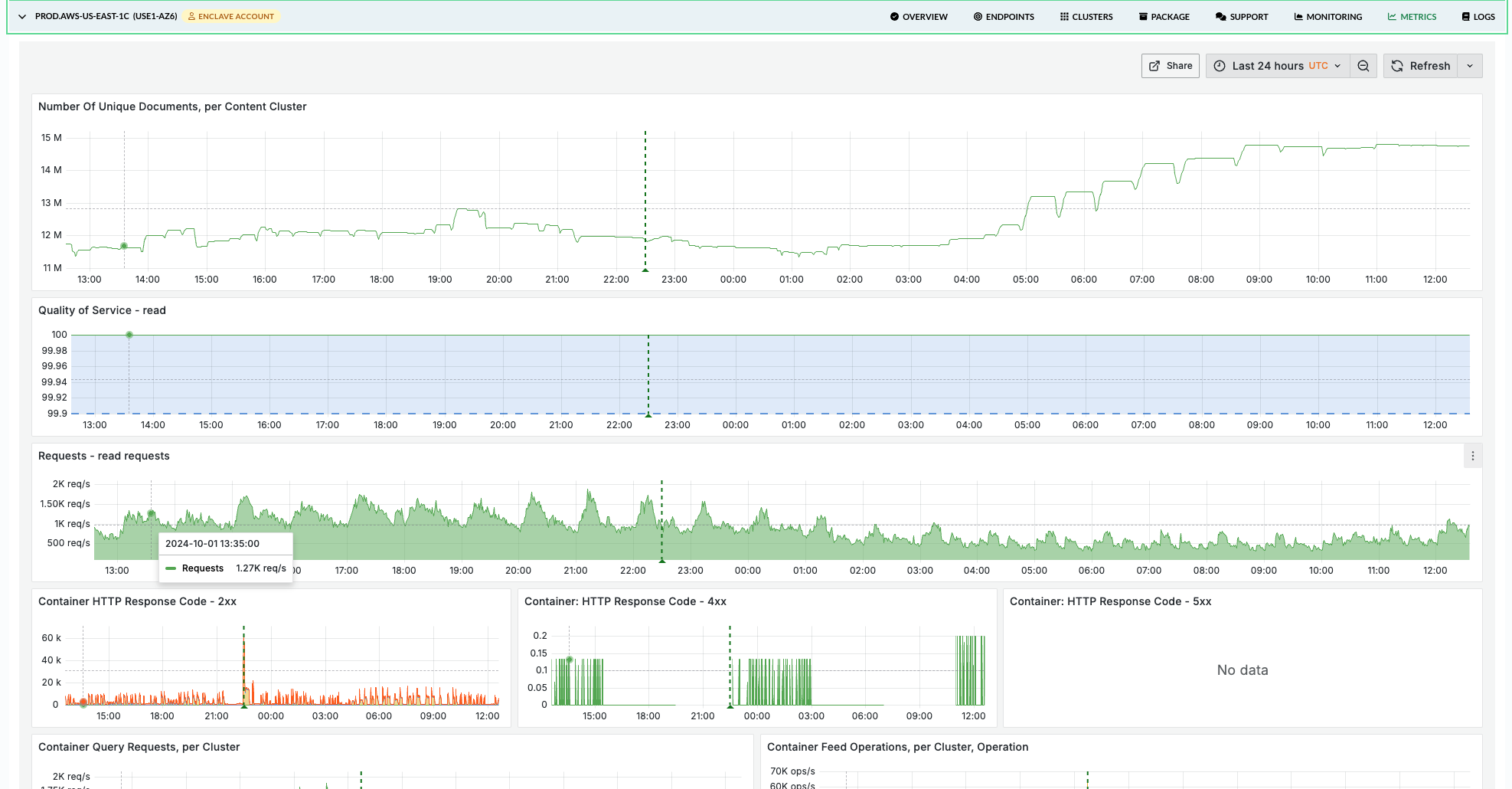
For more information, see Vespa Cloud monitoring.
New posts from our blog
- Vinted moves from Elasticsearch to Vespa
- Announcing support for global significance models
- Deploying RAG at Scale: Key Questions for Vendors
- Vespa.ai: The “Sleeping Giant” Powering Next-Gen Search and Recommendations
Scaling RAG: Beyond vectors conversation
Don’t miss the conversation between Aakarsh Ramchandani, chief strategy officer at Ravenpack, the company behind BigData.com, and Jon Bratseth from Vespa.ai on Scaling AI Beyond Vectors: Building Smarter, Faster Systems For RAG. Watch the recording here.
Events
- GenAI Summit Silicon Valley 2024, Santa Clara, November 1, Jon Bratseth
- DataScienceSalon, San Francisco, November 7, Jon Bratseth: Roundtable
- KM World 2024, Washington DC, November 18-12 - meet us in the Expo area!
- Vespa Open Source Virtual Meetup, November 19, Jon Bratseth
- AI in Financial Services Forum, London, November 21 - meet us in the Expo area!
- The AI Summit New York, December 11-12 - meet us in the Expo area!
- AICamp, New York, December 12, Thomas Thoresen
👉 Follow us on LinkedIn to stay in the loop on upcoming events, blog posts, and announcements.
UPDATED 2024-11-01 with link to webinar recording + minor typos/text fixes
Thanks for joining us in exploring the frontiers of AI with Vespa. Ready to take your projects to the next level? Deploy your application for free on Vespa Cloud today.