
Welcome to the latest edition of the Vespa newsletter. In the previous update, we introduced several new features and improvements, including Approximate Nearest Neighbor (ANN) tuning parameters, binary data detection in string fields, filtering in grouping, geo filtering with geoBoundingBox, global ranking with relevanceScore, layered ranking for working with chunks, Pyvespa enhancements, multiple inheritance for summary-features, and automatic instance migration in Vespa Cloud.
This month, we’re announcing several updates focused on retrieval quality, ranking flexibility, and developer productivity. Each feature is designed to help engineering teams build faster, more accurate, and more maintainable retrieval and ranking systems, while giving businesses better relevance, lower operational overhead, and more predictable performance at scale:
What’s New in Vespa
- Automated ANN Tuning for Faster, More Accurate Retrieval
- Accelerated Exact Vector Distance with Google Highway
- Precise Chunk-Level Matching for Higher Retrieval Quality
- More Expressive Proximity Queries with Enhanced NEAR Operator
- On-the-Fly Tensor Creation from Structs for Ranking
- Simpler Rank-Profile Management with Inner Profiles
- Quantile Computation in Grouping for Instant Distribution Insights
- JSONL Support in Streaming Visiting for Scalable Data Processing
Let’s dive in!
Automated ANN Tuning for Faster, More Accurate Retrieval
Tuning ANN is essential for balancing recall and latency, but doing it manually can be time-consuming and difficult. As a continuation of Vespa’s expansion of ANN tuning parameters, Vespa now includes a new ANN autotune tool in pyVespa that helps you quickly identify the optimal parameters for your workload. Try it out by opening the optimizer notebook.
This tool recommends parameter values and provides visualizations that show the tradeoffs between speed and recall, making it much easier to determine the optimal configuration for your application as can be seen in the image below.
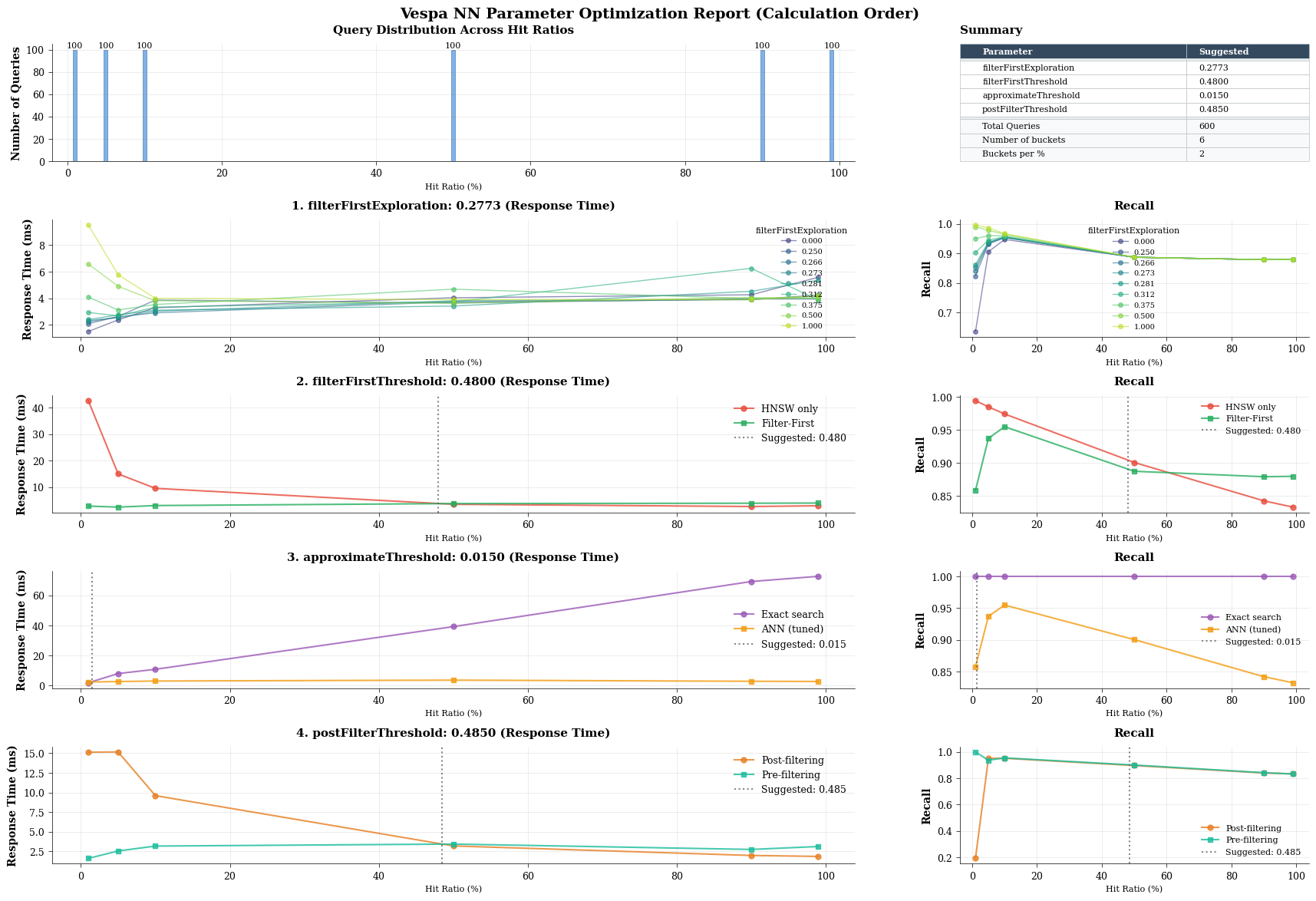
Additionally, to support production monitoring of ANN and exact search performance, we also added new metrics:
- matching.exact_nns_distances_computed
- matching.approximate_nns_distances_computed
- matching.approximate_nns_nodes_visited
Why this matters:
Tuning ANN search has a significant effect on application quality and infrastructure efficiency. The autotune tool enables teams to achieve higher recall and lower latency while using fewer resources, without relying on trial-and-error experimentation. The new metrics also give engineering teams clearer visibility into ANN and exact search behavior in production, making it easier to optimize performance, detect regressions, and scale confidently as datasets grow.
Accelerated Exact Vector Distance with Google Highway
Exact vector distance matters more than most realize. Semantic Search is often implemented using vector distance in nearest neighbor (NN) calculations. For large datasets, systems often use approximate nearest neighbor (ANN) calculations to keep queries fast while still returning relevant results. This approach is efficient, but it requires careful ANN parameter tuning to balance accuracy and performance.
Most applications combine (A)NN search and filtering (geo, price, inventory). Under heavy filtering, exact NN calculations can actually run faster than ANN. That’s why the speed of exact distance calculation is so important. Vespa now accelerates these calculations using Google Highway, a high-performance SIMD library, to accelerate these calculations. This results in faster ANN (HNSW) search, faster exact search, and higher feed throughput across both Graviton and Intel CPUs.
Sample Performance Improvements:
The following x86-64 benchmarks were run on Intel Xeon 8375C (Ice Lake) CPUs, and the AArch64 benchmarks were run on AWS Graviton 3. These results represent only a subset, while Vespa supports multiple tensor cell types.
AArch64 (Graviton 3):
- SIFT 1M BFloat16 squared Euclidean distance:
- 6% increased feed throughput
- 3-6% lower latency for HNSW search
- 27% lower latency for exact search
- No changes in QPS
- Exact binary Hamming:
- 59% increase in QPS with SVE CPU support, 39% increase otherwise
X86-64 (Ice Lake):
- SIFT 1M BFloat16 squared Euclidean distance:
- 30-35% increased feed throughput for puts and updates
- 20% lower latency for HNSW search
- 8-27% increase in HNSW QPS depending on how many additional hits are explored (better relative perf with increased explored hits)
- 20-25% lower latency for exact search
- Exact binary Hamming:
- 30% increase in QPS
Vespa Cloud customers automatically receive these improvements, while self-managed users should upgrade to a recent Vespa release to take full advantage of the performance gains.
Why this matters:
These enhancements reduce latency, boost throughput, and improve retrieval accuracy without requiring schema or tuning changes. For businesses, this means faster applications, lower compute costs, and more predictable performance at scale.
Precise Chunk-Level Matching for Higher Retrieval Quality
When working with chunked text, you often want to ensure that multiple query terms appear in the same chunk, not spread across different ones. Vespa already supports this through the sameElement query operator, which lets you apply conditions to the same array or map element. The following example shows how you can represent text chunks that you want to search with precise positioning.
field chunks type array<string> {
indexing: index | summary
}
Vespa’s updated sameElement operator now supports full nested query sub-trees with operators such as and, equiv, near, onear, or, rank, phrase, and not (!), giving developers fine-grained control over what “same chunk” means.
Example patterns:
where chunks contains sameElement("one" and "two")
where chunks contains sameElement("one" and equiv("two","three"))
where chunks contains sameElement("one" and ({distance: 5}near("two","three",!"four")))
where chunks contains sameElement("one" and phrase("two","three"))
where chunks contains sameElement("one" and !"two")
where chunks contains sameElement("one" or "two")
where chunks contains sameElement(rank("one" and "two", "three"))
This feature is especially important for semantic retrieval, RAG pipelines, compliance search, and situations where the relationships between terms matter.
Tip: If you still want matching across chunks but with lower relevance when terms appear in different places, you can configure element-gap to manage that behavior.
Why this matters:
Teams get more accurate chunk-level matching with less custom logic. This improves RAG grounding, reduces false positives, increases trust in results, and lowers long-term maintenance costs.
More Expressive Proximity Queries with Enhanced NEAR Operator
Vespa’s NEAR() and ONEAR() (“ordered near”) query operators now support nested equiv, phrases, and negative terms inside NEAR to define complex proximity conditions directly in your queries.
Term alternatives inside NEAR, using equiv
This lets you specify multiple acceptable terms within the same proximity window:
where field contains near(term1, term2, equiv(terma, termb))
Phrase proximity inside NEAR, using phrases
You can also require that a phrase appears within the distance window:
where field contains near(term1, term2, phrase(terma, termb))
Negative proximity with exclusion distance
Since Vespa 8.605, you can exclude results where negative terms appear within a specified distance (prefixed with “!”).
where field contains near("sql", "database", !"nosql")
where field contains near("sql", "database", !{exclusionDistance:5}equiv("postgresql","mysql"))
Combined logic
You can mix alternatives, phrases, and negative terms for highly targeted retrieval. For example: “Find docs that there is at least one instance of one or many of a,b,c being at the same 10 term window, but none of e,f.”
where field contains {distance: 10}near("a", "b", "c", !{exclusionDistance:10}equiv("e", "f"))
Why this matters
This enhancement lets engineers express nuanced semantic relationships without external text processing. Businesses benefit from more accurate search, fewer irrelevant results, and higher-quality answers in knowledge and RAG applications.
On-the-Fly Tensor Creation from Structs for Ranking
Vespa allows you to model complex data using arrays of structs, which can already be used for matching, grouping and sorting. In many cases, you may also want to run numerical computations over the data in struct arrays during ranking.
With Vespa 8.606, you can now do this directly by creating a tensor on the fly from data in a struct array using the new tensorFromStructs function.
For example: Suppose you have an attribute items defined as array<struct> with fields name (string) and price (float). You can generate a tensor from this data in a ranking expression as follows:
tensorFromStructs(attribute(items), name, price, float)
to produce a tensor shaped like:
tensor<float>(name{}):{
{name:apple}:1.5,
{name:banana}:0.75,
{name:cherry}:2.25
}
This enables you to use structured data directly inside ranking formulas without preprocessing or restructuring your schema.
Note: The temporary tensor creation costs some performance, see note.
Why this matters
For engineering teams, this feature provides a more flexible and expressive way to use structured data in ranking. It eliminates the need to denormalize or duplicate data, reduces custom preprocessing, and simplifies ranking logic by letting you compute directly on struct values. Businesses gain more accurate and dynamic ranking, better personalization, and faster iteration on relevance improvements.
Simpler Rank-Profile Management with Inner Profiles
Many applications that depend on high retrieval quality use multiple rank profiles to support different ranking needs, like production ranking, sampling, training, or experimentation. When these profiles grow in number, managing the schema files can be cumbersome.
To avoid overly long schema files, these can be put in their own “.profile” files in the application package. Sometimes such profiles form groups that go together, as in:
mySchema.sd
mySchema/myProfile.profile
mySchema/myProfile-sampling.profile
mySchema/myProfile-training.profile
With Vespa 8.601, you can now group related rank profiles inside a single file using inner profiles. This makes it easier to keep related logic together.
Using the example above, you can now simplify the structure to two files:
mySchema.sd
mySchema/myProfile.profile
Where myProfile.profile contains:
rank-profile myProfile {
...
rank-profile sampling inherits myProfile {
...
}
rank-profile training inherits myProfile {
...
}
}
Vespa will automatically expose these as three usable profiles: myProfile, myProfile.sampling, myProfile.training.
Why this matters
Inner profiles make rank-profile management significantly cleaner and more maintainable. Related profiles can be defined, inherited, and versioned together in one place, reducing duplication and making it easier to evolve ranking logic over time. This improves clarity, shortens onboarding time for new team members, and prevents configuration drift across environments. Businesses benefit from faster relevance iteration, fewer ranking mistakes, and smoother deployment windows.
Quantile Computation in Grouping for Instant Distribution Insights
With Vespa 8.582, the grouping language supports computing quantiles, making it easier to analyze distributions directly within queries. You can calculate any quantile by listing the values you want. For example:
all( group(city) each(output(quantiles([0.5, 0.9], delivery_days))) )
This computes the median (p50) and 90th percentile (p90) time to delivery in days per city. Quantiles are computed using KLL Sketch, so they are approximate.
Why this matters
For engineering teams, quantiles eliminate the need for separate analytics pipelines or external post-processing, enabling faster and more efficient data analysis directly within Vespa. For the business, this means quicker visibility into performance trends such as delivery times, query latencies, or user behavior, which supports faster decisions and more responsive product improvements.
Streaming visiting with JSONL for Easier Large-Scale Processing
With Vespa 8.593, Streaming Visiting supports the application/jsonl format for returning results as JSON Lines (JSONL). This makes it easier and more efficient to process the output and track progress for large document sets.
Example output:
{"put":"id:ns:music::one","fields":{"foo":"bar"}}
{"put":"id:ns:music::two","fields":{"foo":"baz"}}
{"continuation":{"token":"...","percentFinished":40.0}}
{"put":"id:ns:music::three","fields":{"foo":"zoid"}}
{"remove":"id:ns:music::four"}
{"continuation":{"token":"...","percentFinished":50.0}}
Why this matters:
JSONL support streamlines migrations, bulk operations, and exports. Engineering teams get smoother large-scale processing, and businesses benefit from faster data workflows and reduced operational overhead.
New Content
We published several new articles and resources since our last newsletter to help teams get more out of Vespa and stay ahead of new developments in search, RAG, and large-scale AI.
Examples and notebooks:
Videos, Webinars, and Podcasts
- Webinar: Migrating from Elasticsearch to Vespa.ai
- Video: Vectors Explained (as non-technical as we could!)
- Vespa Voice:
Blogs and Ebooks
- Advent of Tensors 2025
- LLMs, Vespa, and a side of Summer Debugging
- Protein models Need a PLM Store: Turning Model Outputs into Searchable Biological Intelligence- beyond LLM’s
- How Perplexity beat Google on AI Search with Vespa.ai
- Powering the Next Era of Personalised Commerce
- RAG at Scale: Why Tensors Outperform Vectors in Real-World AI
- Ebook: Best Practices for Large-Scale RAG Applications
- Analyst Report: GigaOm Radar for Vector Databases V3
Upcoming Events
- December 9: Vespa Now: What’s New in Vespa Engineering 2025 Wrap-Up
- January 14: The Path to AI for eCommerce: The Zero Results Problem
👉 Follow us on LinkedIn to stay in the loop on upcoming events, blog posts, and announcements.
Thanks for joining us in exploring the frontiers of AI with Vespa. Ready to take your projects to the next level? Deploy your application for free on Vespa Cloud today.