
In the previous update, we mentioned Global Significance Models, Nearest Neighbor Search with multiple sparse tensor dimensions, new Pyvespa features and the Application metrics dashboard. Today, we’re excited to share the following updates:
- Elasticsearch vs Vespa Performance Comparison
- Vision RAG
- Binarizing vectors
- Secret Store
- Pyvespa 0.51
Elasticsearch vs Vespa Performance Comparison
Elasticsearch, OpenSearch and other Lucene-based engines have an architecture suitable for log analytics but less ideal for use cases with high query load or a need to update already indexed data. In our recent benchmark of Vespa vs Elasticsearch we deep dive into the consequences of this architecture mismatch and show that for a typical e-commerce use case, Vespa delivers better performance at a fifth of the cost.
Vespa’s Performance in Benchmarks:
- Hybrid Queries: 8.5x higher throughput per CPU core.
- Vector Searches: 12.9x higher throughput per CPU core.
- Lexical Searches: 6.5x better throughput per CPU core.
- Updates: 4x more efficient for in-place updates, maintaining efficiency for ongoing updates.
Find an executive summary and the full report at A Benchmark for Modernizing Elasticsearch with Vespa.
Vision RAG
Vision Language Models (VLMs) are models that can process both visual and textual information. These models can perform a wide range of tasks including
- Visual question answering, allowing the model to answer questions about images.
- Image captioning, generating descriptive text for given images.
- Text-to-image search, enabling users to find relevant images based on textual descriptions.
- Video summarization and question answering for video content.
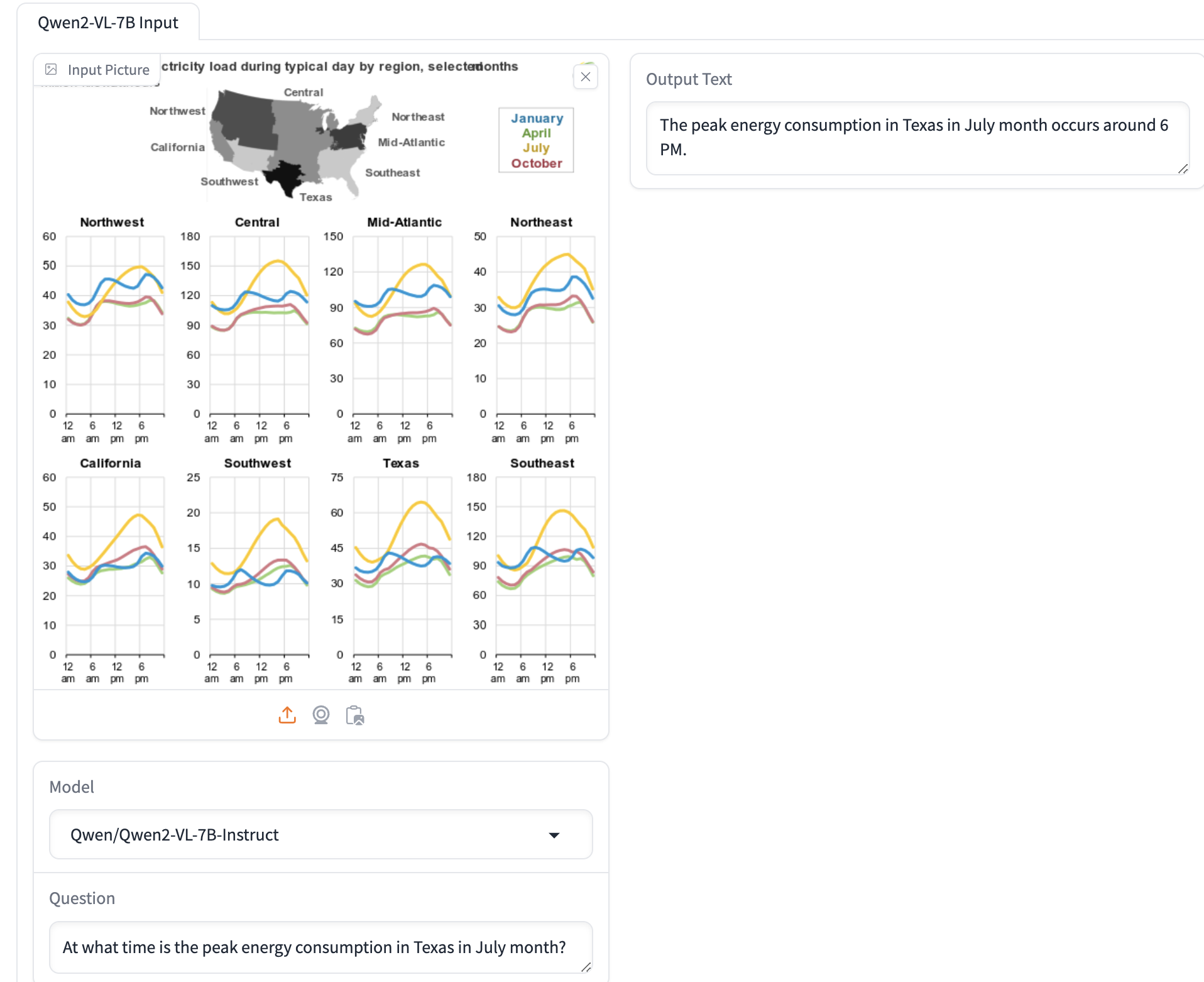 Huggingface Demo Space example.
Huggingface Demo Space example.
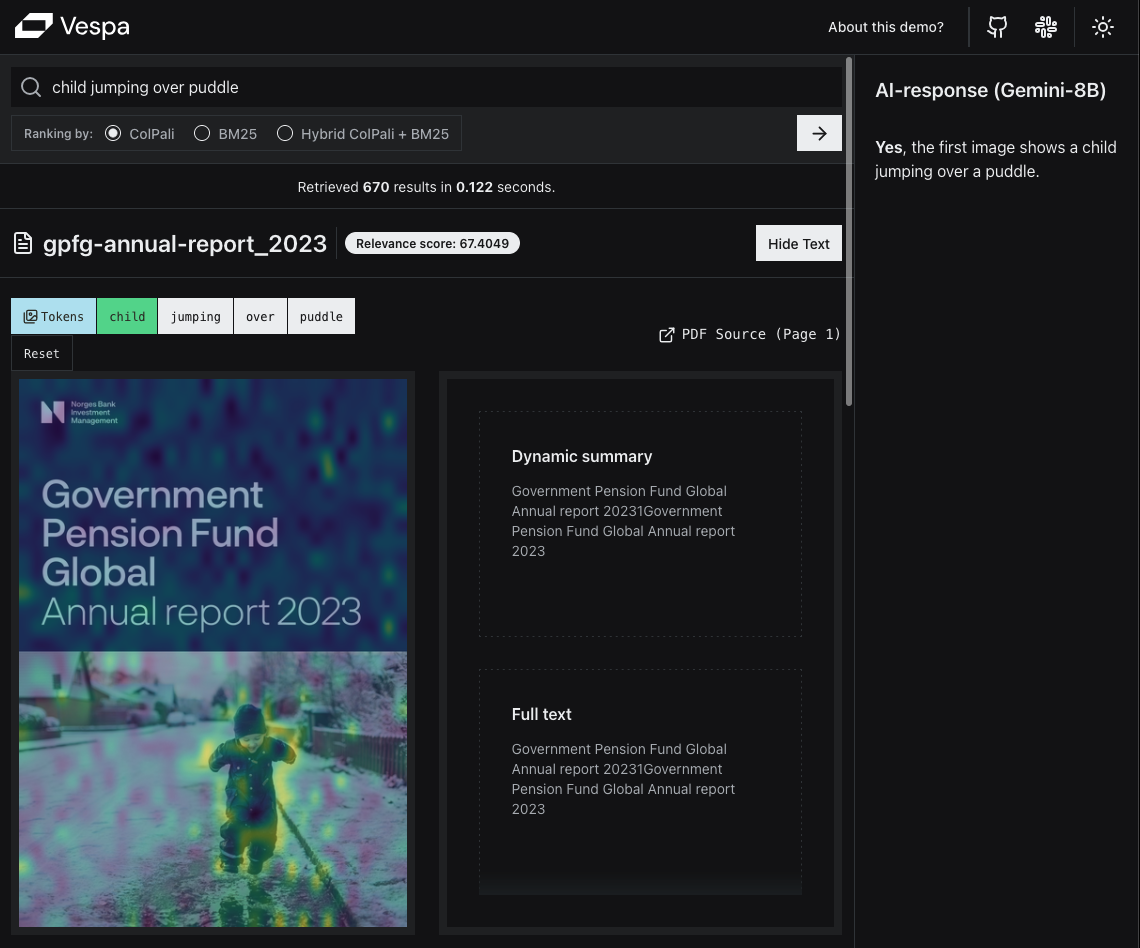
Vespa makes use of VLMs scalable and fast - read more in Scaling ColPali to billions of PDFs with Vespa. Making such applications feasible requires multivector support, ranking with MaxSim and hybrid ranking functions, as well as binarization for cost-effectiveness. It also simplifies the technology stack with fewer processing components, letting Vespa serve image embeddings and model inference online.
Get started learning the capabilities of VLMs using the new sample application at colpali-vespa-visual-retrieval and learn how we built this in visual-rag-in-practice:
Binarizing vectors
Applications add vectors to their schemas to implement semantic searches and solve recommendation use cases with hybrid search. However, adding vector data increases the cost of running the application. With Vespa’s flexible tensor framework (a vector is a tensor), one can easily balance the tradeoff between cost and quality - a vector can have any cell type from double to bit. Applications can cut costs to less than 10% by binarizing vectors and using phased ranking to preserve precision.
The transition from larger to smaller cell types is made much easier from Vespa 8.434,
using the new pack_bits and binarize converters.
These converters makes it easy to index or re-index documents to binarized cell types -
find practical examples in binarizing vectors.
Secret Store
Vespa Cloud’s secret store offers a secure, integrated solution that makes it simple and safe to manage sensitive secrets. Secrets can now be managed directly in the Vespa Cloud Console and then used in Java code or components like the LLM searcher for RAG use cases - think of it as a safe place to store your OpenAI API key.
This feature also opens up new possibilities, such as connecting to external APIs during data feeding. Read more in Secret Store and try the RAG sample application with your API key!
Pyvespa 0.51
Pyvespa 0.51 is released - v0.51.0 has the complete list of features and bug fixes, most notably improvements to notebooks and documentation.
New features and changes
- Vespa makes it easy to change configuration in running systems through
safe, automated deployments.
Some configuration changes require an index rebuild.
This is automated, but takes time.
Since Vespa 8.444, one can easily track progress by inspecting vespa.log, e.g.,
[2024-11-19 13:53:27] EVENT state/1 name="hnsw.index.rebuild.progress" value="{"name":"embedding","percent":35.53376446623553}" - More metrics are now available to track detailed disk space usage at metrics reference,
e.g.,
content.proton.index.cache.postinglist.elements, and below. - From 8.448, the Vespa CLI supports queries in JSON,
using the
–-fileoption - example:$ cat q.json { "yql": "select * from sources * where artist contains \"Diana\"", "timeout": "5s", "ranking": "default" } $ vespa query --file q.json
New posts from our blog
- Vector search beyond the database
- How Generative AI Is Changing E-commerce
- Elasticsearch vs Vespa Performance Comparison
- Navigating in the New AI-Driven E-commerce Landscape
- Visual RAG over PDFs with Vespa - A demo application in Python
- A Benchmark for Modernizing Elasticsearch with Vespa
- Vespa for Dummies
- Why Norway’s Environmental Commitment Reflects in Vespa.ai’s Values
- Securely Storing Secrets on Vespa Cloud
Events
- The AI Summit New York, December 11-12 - meet us in the Expo area, and look for the Vespa Visual RAG demo using ColPali in the demo section!
- AICamp, New York, December 12, Thomas Thoresen: Building a Visual RAG application with Vespa in Python
- AI infrastructure and architecture summit, London, January 14-15 - meet us in the Expo area!
👉 Follow us on LinkedIn to stay in the loop on upcoming events, blog posts, and announcements.
Thanks for joining us in exploring the frontiers of AI with Vespa. Ready to take your projects to the next level? Deploy your application for free on Vespa Cloud today.