
Text-to-image search is a form of search where images are retrieved based on a textual description. This form of search has, like text search, gone through a revolution in recent years. Previously, one used traditional information retrieval techniques based on a textual label associated with each image, thus not really using the image at all. In contrast, modern approaches are based on machine-learned representations of actual image content.
For instance, “a child playing football”:

Or “a dog catching a frisbee”:

Both of these are the top results from the Vespa text-image sample app. This sample application is powered by a pre-trained model, trained specifically to “understand” both text and image content. Pre-trained models have come to dominate an increasing number of fields in recent years. This is possibly best demonstrated by the popularity of BERT and relatives, which has revolutionized natural language processing. By pre-training a model on large datasets, it gains a base capability that can be fine-tuned to specific tasks using much smaller amounts of data.
This particular sample app is based on the
CLIP model from OpenAI,
which has been trained on 400 million (image, text) pairs taken from the internet. CLIP
consists of two models: one for text and one for images. During training, images are
associated with textual descriptions. Like with pre-trained language models, CLIP thus
gains a basic textual understanding of image content.
One of the exciting capabilities CLIP has shown is that this training method enables a strong capability for zero-shot learning. Most previous image classification approaches classify images into a fixed set of labels. However, CLIP can understand and label images with labels it hasn’t seen during training. Also, it generalizes very well with images it hasn’t encountered during training.
The sample application uses the Flickr8k dataset, which consists of 8000 images. These images were not explicitly used during the training of CLIP. Yet, the model handles them successfully, as seen in the examples above. This is interesting because it means that you can expect reasonable results from your own image collection.
In this blog post, we’ll describe how to use the CLIP model to set up a production-ready text-to-image search application on Vespa. Vespa is an excellent platform for this as it contains all the necessary capabilities right out of the box, such as (approximate) nearest neighbor search and machine learned model inference. We’ll start by looking closer at the CLIP model.
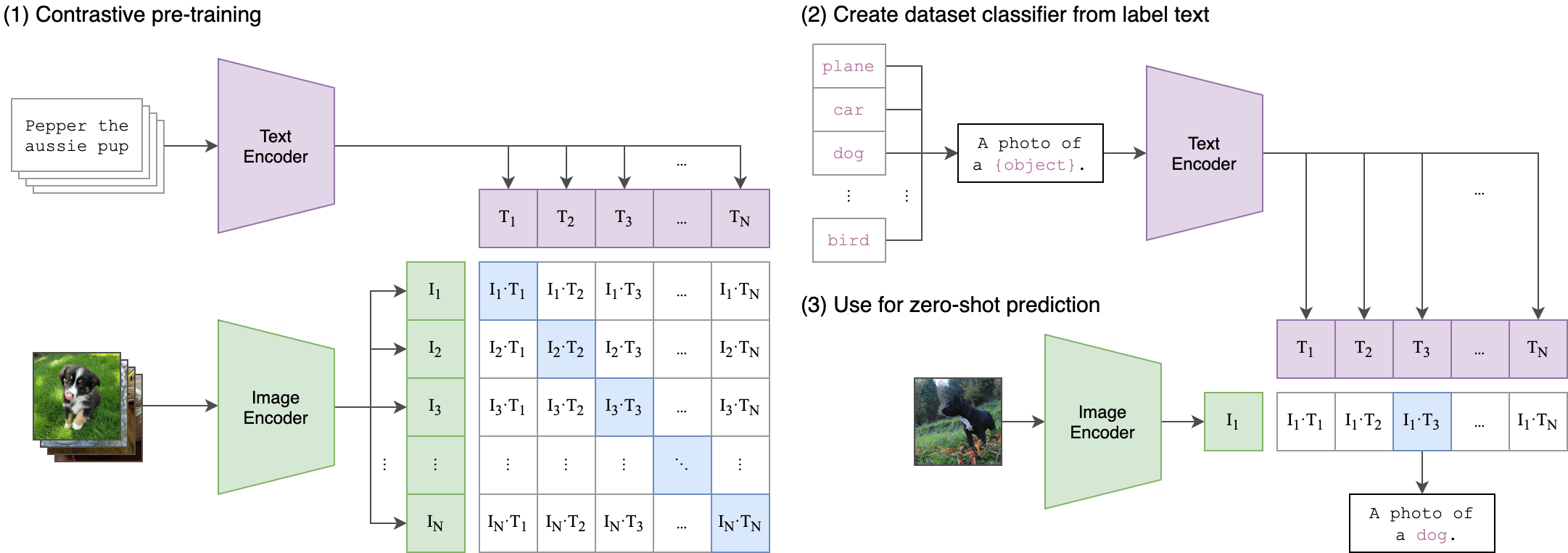
CLIP
CLIP (Contrastive Language-Image Pre-training) is a neural network that learns visual concepts from natural language supervision. By training the model from a very large set of images and captions found on the internet, CLIP learns to associate textual description with image content. The goal is to create a model with a certain capability for “understanding” image content without overfitting to any benchmark such as ImageNet. This pre-trained network can then be fine-tuned toward a more specific task if required. This is similar to how natural language understanding models such as BERT are pre-trained on large corpora and then potentially fine-tuned on much smaller amounts of data for specific tasks.
Perhaps the most significant contribution of CLIP is the large amount of data it has been trained on: 400 million image-text pairs. This enables an excellent capability for zero-shot learning, meaning:
- Images can be classified by labels the model hasn’t seen during training.
- Images not seen during training can still be classified correctly.
This is exemplified by the following code:
import torch
import clip
from PIL import Image
model, preprocess = clip.load("ViT-B/32", device="cpu")
image = preprocess(Image.open("image.png")).unsqueeze(0)
text = clip.tokenize(["a diagram", "a dog", "a cat"])
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1)
The result in this code, probs, contains the relative probabilities that the
image is described by the 3 different text labels: diagram, dog, or cat.
Indeed, any text or number of texts can be passed to the model, which estimates
the relative probabilities between them. This architecture differs from typical
image classification models that contain a fixed number of outputs, one for
each pre-defined label.
CLIP contains two models: one for text and one for images. Both models produce
a representation vector from their inputs. This is the image_features and
text_features above. The final output is the cosine distance between these
two. By training on text and image pairs, the model learns to minimize the
distance between matching text and image representations in a shared semantic
space.
For more details about CLIP, please refer to CLIP’s GitHub page.
Next, we’ll see how to use CLIP to create an image search application where the user provides a textual description, and the search system will return the best matching images.
Text-to-image search
Recall that the entire CLIP model takes a set of texts and an image to “classify” the image among the provided texts. We want to find the best matching images from a single provided text to create a search application. The key here is the representation vector generated by CLIP’s text and image sub-models.
Using the image model alone, we can generate a representation vector for each image. We can then generate a vector for a query text and perform a nearest neighbor search to find the images with the smallest cosine distance from the query vector.
Nearest neighbor search consists of calculating the distance between the query vector and the image representation. This must be done for all images. As the number of images increases, this becomes infeasible. A common solution is to create an index of the image representations. Unfortunately, there are no exact methods for finding the nearest neighbors efficiently, so we trade accuracy for efficiency in what is called approximate nearest neighbors (ANN).
Many different methods for ANN search have been proposed. Some are compatible with inverted index structures, so they can be readily implemented in existing information retrieval systems. Examples are k-means clustering, product quantization (and its relatives), and locality-sensitive hashing, where the centroids or buckets can be indexed. A method that is not compatible with inverted indexes is HNSW (hierarchical navigable small world). HNSW is based on graph structures, is efficient, and has an attractive property where the graph can be incrementally built at runtime. This is in contrast to most other methods that require offline, batch-oriented index building.
The core of our text-to-image search application is an ANN index. In the following, we’ll set this up in a Vespa application.
The Vespa text-to-image search application
It’s straightforward to set up an ANN search index in Vespa. All that is needed is a document schema:
schema image_search {
document image_search {
field image_file_name type string {
indexing: attribute | summary
}
field image_features type tensor<float>(x[512]) {
indexing: attribute | index
attribute {
distance-metric: angular
}
index {
hnsw {
max-links-per-node: 16
neighbors-to-explore-at-insert: 500
}
}
}
}
rank-profile image_similarity inherits default {
first-phase {
expression: closeness(image_features)
}
}
}
Here, the documents representing images contain two fields: one for the image
file name and one for the image representation vector. Even though we could, we
don’t store the image blob in the index. The image_features vector is
represented as a tensor with
512 elements along one dimension. These are indexed using a HNSW
index
which supports approximate retrieval.
The schema also contains a rank profile. The image documents will be ranked
using the closeness rank feature when using this rank profile. The distance
function is set to angular in the document schema, so the closeness will
use the cosine distance between the provided query vector and the
image_features vector.
Using the above, we can issue a query that performs an approximate nearest neighbor search:
{
"yql": "select image_file_name from sources * where ([{\"targetHits\": 10}]nearestNeighbor(image_features, text_features));",
"hits": 10
"ranking.features.query(text_features): [0.21,0.12,....],
"ranking.profile": "image_similarity"
}
This will return the top 10 images given the provided text_features query
vector. Note that this means you need to pass the text query’s representation
vector; thus, it needs to be calculated outside of Vespa for this particular
query.
The text-image search sample application includes a Python-based search app which uses the CLIP model for this. The app uses pyvespa and is particularly suitable for analysis and exploration. We’ll take a closer look in the next section. UPDATE 2025-01-22: The python code is removed from this app
The sample application also includes a stand-alone Vespa application. Here we move the logic and CLIP model for generating the text representation vector into Vespa itself. This enables querying directly with text. The stand-alone Vespa application is more suitable for production, and we’ll take a look later.
Pyvespa
Pyvespa is the Python API to Vespa, which provides easy ways to create, modify, deploy and interact with running Vespa instances. One of the main goals of pyvespa is to allow for faster prototyping and to facilitate machine learning experiments for Vespa applications. With pyvespa, it is easy to connect to either a local Vespa running in a Docker container or Vespa cloud, a service for running Vespa applications.
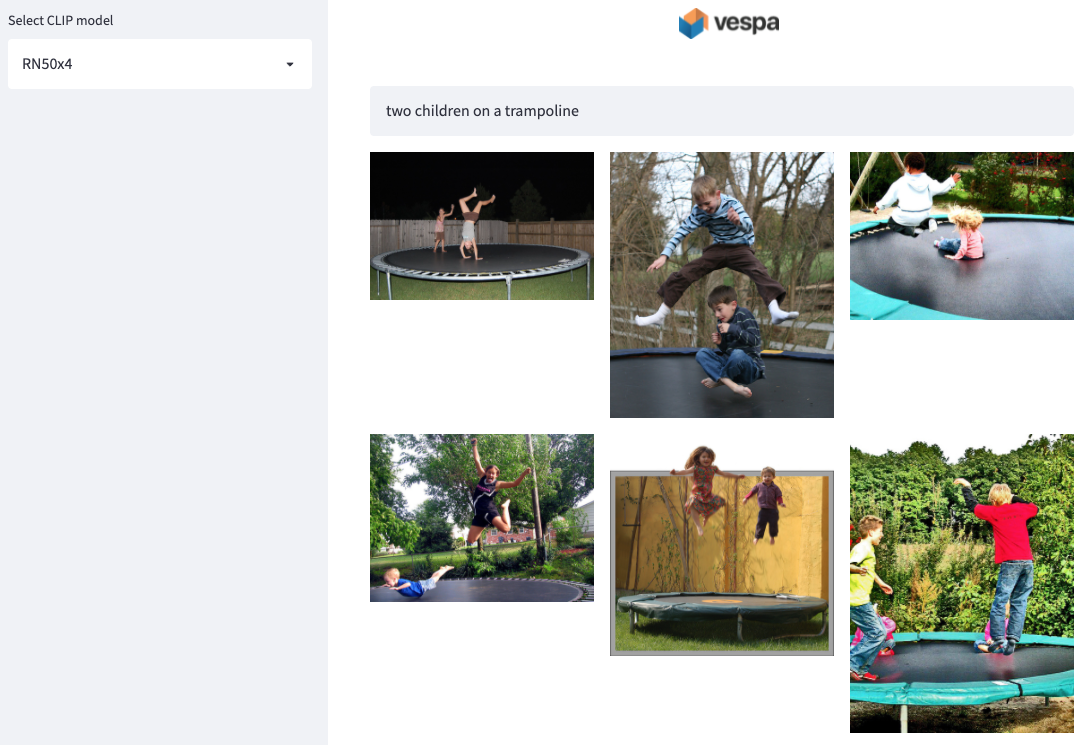
The text-image sample app
notebook
contains a full end-to-end example of setting up the application, feeding
images, and querying. This example also uses all 6 different model variants
found in CLIP and includes an evaluation analysis. As is shown there, the
ViT-B/32 model is found to be superior.
The streamlit demo app can be set up to query the python application after it is deployed and images are fed. With this application, one can visually evaluate the differences in the model variants. UPDATE 2025-01-22: The streamlit app is removed from the sample application
Native Vespa application
The Python application is fine for prototyping and running experiments. However, it contains the code to generate vectors for the text queries. For an application to run in production (which requires low latency and stability), the question arises on how we make this feature available. Vespa contains facilities to run custom code as well as evaluating machine-learned models inside custom code.
The ViT-B/32 model was superior during analysis, so this application uses
only that model. The model itself is put in the Vespa application package under
the models directory. There, it is automatically discovered and made
available to custom components, and a REST API is also provided.
The stand-alone sample application contains a searcher that modifies the query from textual input to a vector representation suitable for nearest neighbor search. This searcher first tokenizes the text using a custom byte-pair encoding tokenizer before passing the tokens to the language model. The query is then modified to an approximate nearest neighbor search using the resulting vector representation.
After deploying this, the Vespa application can take a string input directly and return the best matching images.
Summary
Pretty much anything can be represented by a vector. Text, images, even time-based entities such as sound, viewing history or purchase logs. These vectors can be thought of as points in a high-dimensional space. When similar objects (according to some metric) are close, we can call this a semantic space. Interestingly, the origin of the representation does not really matter. This means we can project entities into a shared semantic space, independent of what type of entity it is. This is called multi-modal search.
In this post, we’ve explored text-to-image search in Vespa, where users provide a textual description and Vespa retrieves a set of matching images. For this, we used the CLIP model from OpenAI, which consists of two transformer models: one for text and one for images. These models produce vector representations, and they have been trained so that the cosine distance is small when the text matches the image. First, we indexed the vector representations of a set of images. Then, we searched these using the vector representation from user-provided queries.
One of the strong points of the CLIP model is its zero-shot learning capability. While we used the Flickr8k data set here, any set of images can be used. That means it is easy to set up this application for your own collection of images. However, as with all pre-trained models, there is room for improvement using fine-tuning. The CLIP model is, however, a great baseline.
We have also created another sample application for video search. This is another example of using the CLIP model to search for videos given a textual description.
