
It really isn’t an exaggeration to claim that the field of NLP has been revolutionized in the last year or so by the introduction of the Transformer and related models such as the Bidirectional Encoder Representations from Transformers (BERT). Indeed, BERT has since it’s release dominated various leaderboards on NLP related tasks such as MS MARCO. Extending beyond research, a growing number of companies have shown considerable interest in adopting these models for production.
One of the reasons for this is the ease of getting started. This is in large part due to Hugging Face and it’s open-source Transformers library. With this library it’s easy to start with any of the thousand or so pretrained base models, and fine-tune it to a specific task such as text classification, translation, summarization, text generation or question/answering. This is an attractive proposition considering that some of these base models are immense, requiring huge amounts of data and computational resources to train. The cost of training can sometimes run into the millions of dollars. In contrast, taking a base model and fine-tuning it requires much less effort, making powerful NLP capabilities available to a larger community.
Recently it has also become easier to deploy and serve these models in production. The Transformers library has added functionality to export models to ONNX, allowing for greater flexibility in model serving since this is largely independent from whether or not the model was trained on Tensorflow or PyTorch. We’ve been working a lot lately on being able to evaluate Transformer models in Vespa, so in this blog post we thought we would share a bit on how we perceive the benefits of inference on Vespa, show how to use a transformer model in ranking with a small sample application, and discuss future directions we are working toward.
Why Vespa?
A common approach to serve machine learned models in general is to set up a model server and call out to this service from somewhere in your serving stack. This is fine for tasks that evaluate a single data point for each query, for instance classification, text generation or translation. However, for certain application types such as search and recommendation this can become a scalability bottleneck, as these applications need to evaluate the model with a potentially large number of items. One can quickly reach network saturation due to the multiplicative effect of number of queries per second, data points per query, and representation size.
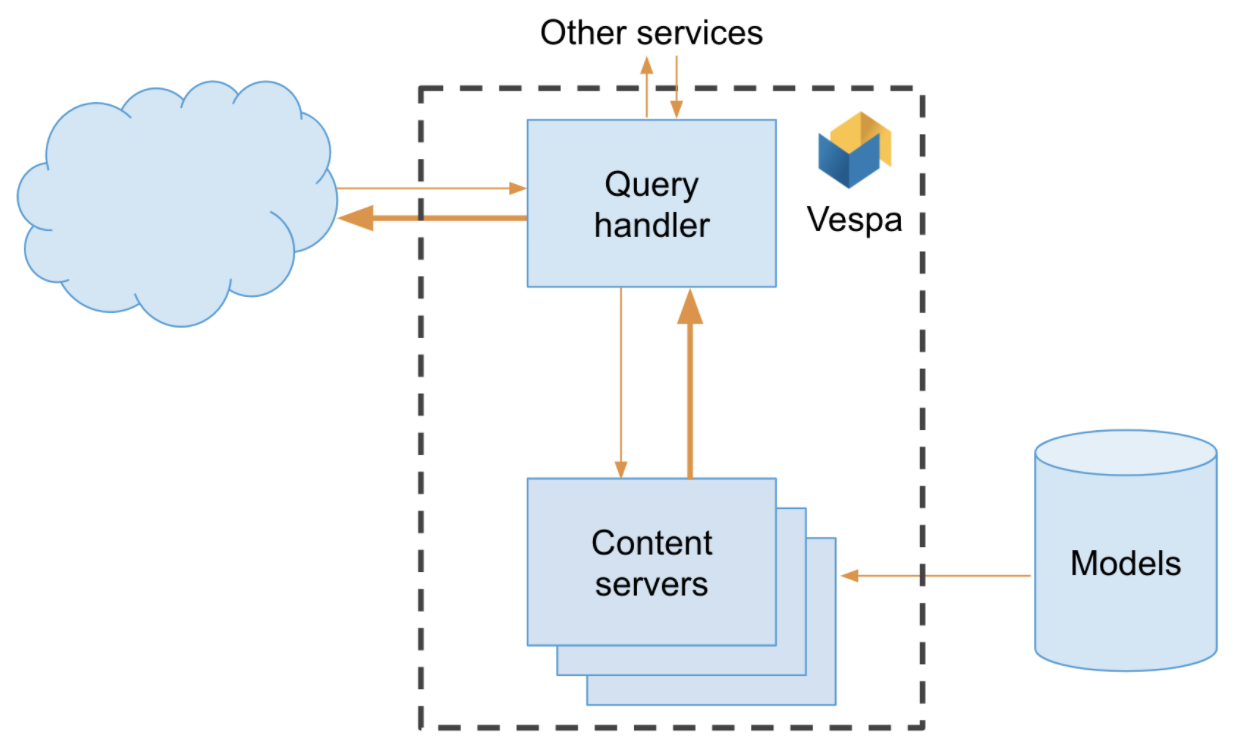
One of the guiding principles in Vespa is to move the computation to the data rather than the other way around. Vespa is a distributed application that consists of a set of stateless nodes and a set of stateful content nodes which contains the data. A query is first processed on the stateless layer before being fanned out to the content nodes. The content nodes handle data-dependent computation and each return their results back to the stateless layer where the globally best results are determined.
So when deploying a Vespa application, the machine learned models are automatically deployed to all content nodes, and evaluated there for each query. This alleviates the cost of query time data transportation. Also, as Vespa takes care of distributing data to all content nodes and redistributing elastically, one can scale up computationally by adding more content nodes thus distributing computation as well. Additionally, this reduces system complexity as there are fewer production services to maintain. This last point is something which one should not discount.
One of the really unique features of Vespa is the flexibility one has to combine results from various features and string models together. For instance, one could use a small, fast model in an early phase, and a more complex and computationally expensive model that only runs on the most promising candidates. From a text search perspective that could be BM25 combined with a Transformer model. For instance:
rank-profile bm25_and_transformer {
first-phase {
expression: bm25(content)
}
second-phase {
rerank-count: 10
expression: onnx("bert.onnx")
}
}
This is an example of how to instruct Vespa to calculate the BM25 score as a first stage and send the top 10 candidates to the BERT model. Note that this is per content node, so with 10 content nodes, the BERT model is running effectively on 100 data points.
Evaluation of models from different platforms such as Tensorflow, PyTorch, XGBoost and LightGBM can be freely combined as well, even within the same expression. To efficiently search for potential candidates one can use WAND. Recently we’ve also added approximate nearest neighbors, giving the option of a highly performant nearest neighbor search which can naturally be based on textual representation as well.
In summary, Vespa offers ease of deployment, flexibility in combining many types of models and computations out of the box without any plugins or extensions, efficient evaluation without moving data around and a less complex system to maintain. This makes Vespa an attractive platform.
Ranking with Transformers
For a taste of how to use Transformer models with Vespa we’ve added a small sample application: transformers. **UPDATE 2025-01-22: Link to MS Marco sample app instead, the transformers app is discontinued: ** MS Marco Passage Ranking. In this sample app we use the MS MARCO dataset which combines both queries, content and relevance judgements. For the purposes of this sample, we won’t fine-tune the model and will just use the base model as-is. Our goal is to set up a Vespa application that indexes the documents and scores content based on a BM25 stage followed by a Transformer stage. The sample app contains a README that goes through all the steps, but here we’ll discuss some of the highlights.
One decision that needs to be made is which Transformer model to use. It’s
worth mentioning that large models have a significant computational cost which
has a direct impact on performance and the scalability of the application. So
to keep latency down we use a fairly small model (“nboost/pt-tinybert-msmarco”)
for this sample application. We download and export the model to ONNX using the
Transformers library. Our export script builds upon the official
convert_graph_to_onnx.py rather than using it directly because we want to use
the equivalent of the Transformer AutoModelForSequenceClassification, and the
official export script does not export the additional tensors required for the
linear transformation on top of the base model. The script puts the exported
model into the “models” directory of the Vespa application package where it
will ultimately be imported and distributed automatically to all content nodes.
We also need to create the data feed. As part of evaluating any Transformer model, text needs to be tokenized. The tokenizer is part of the model as the model is dependent upon stable tokenization during both training and inference. For the purposes of this sample app, we have not implemented a tokenizer in Vespa, meaning that we handle tokenization outside of Vespa. So in the conversion of MS MARCO data to a Vespa feed, we also use the model’s tokenizer to generate tokens for each piece of content. This means that when querying Vespa, we currently need to send in the tokenized representation of the query as well. In a follow-up post we will show how to port a tokenizer and use that during document and query processing in Vespa.
Putting these together, we need to decide which fields to index for each piece of content as well as how to compute each result. This means defining a document schema which includes setting up expressions for how candidates for retrieval should be calculated. The fields we set up for this sample application are:
field id type string {
indexing: summary | attribute
}
field title type string {
indexing: index | summary
}
field url type string {
indexing: index
}
field body type string {
indexing: index
}
field tokens type tensor(d0[128]) {
indexing: attribute
}
</pre>
The `id`, `title`, `url` and `body` fields come directly from MS MARCO. The
`tokens` field stores the token sequence from the tokenizer mentioned above. Note
that we’ve decided upon a sequence length of 128 here to keep sizes small. The
cost of evaluating Transformer type models is generally quadratic in relation
to the sequence length, so keeping them short has significant gains in
performance. This means that we only store the first 128 tokens for each
document. The documents in MS MARCO are significantly larger than that however,
and a common way of handling that is to instead index up each paragraph, or
perhaps even each sentence, for every document. However, we have not done that
explicitly in this application.
We also need to define how to compute each result. Evaluating the model is
fairly easy in Vespa:
rank-profile transformer {
first-phase {
expression: bm25(title) + bm25(body)
}
second-phase {
rerank-count: 10
expression: onnx("rankmodel.onnx", "default", "output_1")
}
}
The first-phase expression tells Vespa to calculate the BM25 score of the query
against the `title` and `body` fields. We use this as a first pass to avoid
evaluating the model on every document. The second-phase instructs Vespa to
evaluate `"rankmodel.onnx"` (the one exported from the
Transformers library) and calculate `"output_1"` with the top 10
candidates from the previous stage. Note that this isn’t the actual expressions
used in the sample app where the output from the model is sent through a linear
transformation for sequence classification.
Most transformer models have three inputs: `input_ids`, `token_type_ids` and an
`attention_mask`. The first is the token sequence for input and in this case is
the combined sequence of tokens from both the query and document. When Vespa
imports the model it looks for functions with the same names as the inputs to
the model. So a simplified version of the `input_ids` function can be as follows:
# Create input sequence: CLS + query + SEP + document + SEP + 0's
function input_ids() {
expression {
tensor(d0[1],d1[128])(
if (d1 == 0,
TOKEN_CLS, # 101
if (d1 < input_length + 1,
query(input){d0:0, d1:(d1-1)},
if (d1 == input_length + 1 || d1 == 127,
TOKEN_SEP, # 102
if (d1 < document_length + input_length + 2,
attribute(tokens){d0:(d1-input_length-2)},
TOKEN_NONE # 0
)))))
}
}
</pre>
This constructs the input tensor (of size 1x128) by extracting tokens from the
query or the document based on the dimension iterators. The values `input_length`
and `document_length` are themselves functions that return lengths of the input
and document respectively. Note that this function in the actual sample app is
a bit more complex to cater for documents shorter than 128 tokens. After
`input_ids` is calculated, it is fairly trivial to find the other two.
One consideration is that Vespa evaluates the model once per candidate. This
means that the latency is directly proportional to the number of candidates to
evaluate the model on. The default number of threads per query is set to 1, but
[this is easily
tuned](https://docs.vespa.ai/en/reference/services-content.html#requestthreads-persearch).
This allows for lower latency when evaluating multiple candidates. Note that
using a larger number of threads per query might have a negative impact when
handling many queries in parallel, so this is something that must be tuned on a
per application basis.
So, when it comes to setting up Vespa, that is basically it. In summary:
1. Put the model in the application package under a "models" directory.
2. Define a document schema.
3. Describe how to score each document.
After feeding the documents to Vespa, we are ready to query. We use the queries
in MS MARCO and tokenize them using the same tokenizer as the input, resulting
in a query looking something like this:
http://localhost:8080/search/?hits=10&ranking=transformer&
yql=select+%2A+from+sources+%2A+where+content+CONTAINS+
%22what%22+or+content+CONTAINS+%22are%22+or+content+CONTAINS+
%22turtle%22+or+content+CONTAINS+%22beans%22%3B&
ranking.features.query(input)=%5B2054%2C2024%2C13170%2C13435%5D
Here, the YQL statement sets up an OR query for “what are turtle beans”. This
means Vespa will match all documents that have at least one occurrence of each
of these terms, and rank them according to their BM25 score. The
`ranking.features.query(input)` defines an input tensor that represents the token
sequence of this sentence, in this case `[2054, 2024, 13170, 13435]`. Both these
input parameters are url-encoded. For this query, the top rated result (aptly
titled “What are Turtle Beans”) receives a positive class probability from this
model of 0.92. This value represents how well the document relates to the
query.
As mentioned previously, we’ve held tokenization outside of Vespa for the
purposes of this post, but we will follow up with another post where we
implement this within Vespa, so that only the textual content of each document
and query is passed to Vespa.
### Looking forward
In this post we’ve showcased some of the work we’ve done recently on supporting
Transformer type models in Vespa. We still have work to do going forward. One
is to continually work to increase performance. Another is to support a growing
number of model types, as there are limits to what we support today. Also we
want to add additional convenience features to make it even easier to deploy
and evaluate models efficiently on Vespa.
Please check out the sample application and let us know what you think!