
In this post, we introduce the recently announced answerai-colbert-small model (announcement post), a small ColBERT model that is optimized for efficient and effective passage search. We demonstrate how to use it using Vespa’s support for both inferencing and scoring using ColBERT models.
What is ColBERT?
The ColBERT retrieval and ranking model was introduced in ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT by Omar Khattab and Matei Zaharia. It is one of the most cited recent information retrieval papers, with over 800 citations. Later improvements (distillation, compression) were incorporated in ColBERT v2.
ColBERT learns token-level vectors usable for retrieval and ranking. Instead of compressing token-level vectors into a single representation like regular text embedding models, it learns token-level vectors.
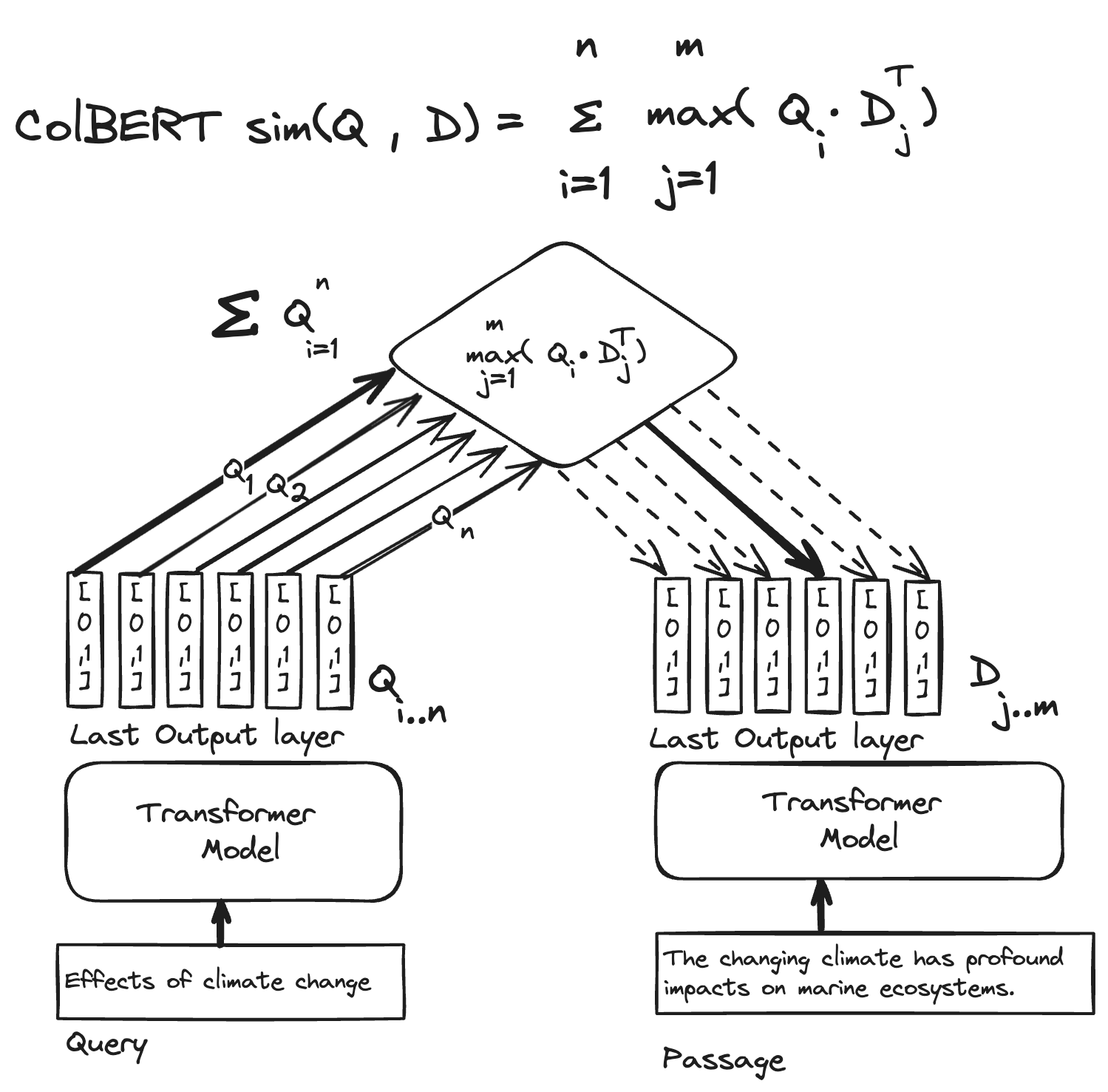 Illustration of the ColBERT model representation and the late-interaction similarity expression (MaxSim). For each query token representation (Qi), compute the dot product for all passage token representations (Dj) and keep track of the max score for query token vector i. The final similarity score is the sum of all max dot product scores for all query token vectors.
Illustration of the ColBERT model representation and the late-interaction similarity expression (MaxSim). For each query token representation (Qi), compute the dot product for all passage token representations (Dj) and keep track of the max score for query token vector i. The final similarity score is the sum of all max dot product scores for all query token vectors.
ColBERT is more of an architecture and approach and not a specific model checkpoint. As demonstrated with the newly released answerai-colbert-small
model checkpoint, it is possible to train models that are both cheaper and more effective.
Despite its small size, it’s a particularly strong model, vastly outperforming the original 110 million parameters ColBERTv2 model on all benchmarks, even ones completely unseen during training such as LoTTe. In fact, it is by far the best performing model of its size on common retrieval benchmarks, and it even outperforms some widely used models that are 10 times larger
Quote from the Answer.ai blog post.
Why ColBERT-small?
A smaller model is cheaper to run inference with and can be more efficient in terms of latency and resource usage. This is particularly important in scenarios where you need to run many queries in parallel, such as in a search engine. With only 33M parameters, the answerai-colbert-small model is a great choice for such scenarios. In short:
- Cheap model inference, enables CPU-based serving
- Reduced token-level storage and compute complexity as
answerai-colbert-smalluses 96-dimensional embeddings instead of 128-dimensional embeddings as in the original ColBERT model checkpoint. - Outperforming larger models on common retrieval benchmarks
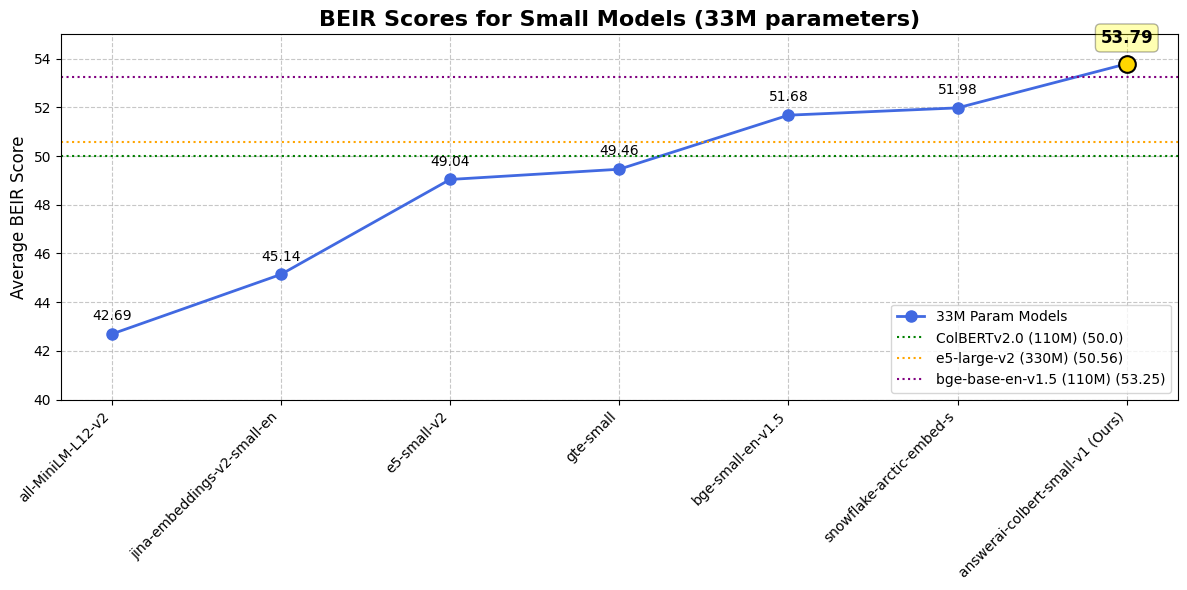 BEIR results for the
BEIR results for the answerai-colbert-small model
Using answerai-colbert-small in Vespa
The answerai-colbert-small model is available in the Hugging Face model hub.
The following examples are inspired by the two Vespa sample applications demonstrating how to use Vespa with ColBERT models:
- Regular Context GitHub colbert (blog post)
- Long-Context GitHub colbert-long (blog post)
Define the embedder
We define the embedder in the services.xml file. The embedder is a component of type colbert-embedder that specifies the transformer model and tokenizer model. See doc.
<!-- See https://docs.vespa.ai/en/embedding.html#colbert-embedder -->
<component id="colbert" type="colbert-embedder">
<transformer-model url="https://huggingface.co/answerdotai/answerai-colbert-small-v1/resolve/main/vespa_colbert.onnx"/>
<tokenizer-model url="https://huggingface.co/answerdotai/answerai-colbert-small-v1/resolve/main/tokenizer.json"/>
</component>
In the schema, we can use the model with and without binarization as described in the ColBERT blog post.
With binarization
Using Vespa’s support for binarization, we can reduce the storage footprint by 32x from 96-dimensional float embeddings to 96-dimensional bits, packed into 12 bytes.
field colbert type tensor<int8>(dt{}, x[12]) {
indexing: (input title || "") . " " . (input chunk || "") | embed colbert | attribute
}
Without binarization
Standard float embeddings can be used as well. Also bfloat16 can be used for reduced storage footprint by 2x.
field colbert type tensor<float>(x[96]) {
indexing: (input title || "") . " " . (input chunk || "") | embed colbert | attribute
}
Usage in queries is the same as the examples in the ColBERT blog post.
Summary
It is exciting to see the release of the answerai-colbert-small model checkpoint, a small but mighty ColBERT model checkpoint that is optimized for efficient and effective passage search. In this post, we have demonstrated how to use it in Vespa, and we look forward to seeing how it can be used in various retrieval applications.
For those interested in learning more about Vespa or ColBERT, join the Vespa community on Slack or Discord to exchange ideas, seek assistance from the community, or stay in the loop on the latest Vespa developments.
