


Elasticsearch vs Vespa Performance Comparison
We recently benchmarked Elasticsearch and Vespa and wrote a very detailed 84-page report that aims to be clear and educational. There, we go beyond the benchmark results: we start by showing how we see fair and comprehensive benchmarking. Then we add details about the architectures of both Elasticsearch and Vespa. Finally, after the results, you’ll see how you can reproduce the benchmark on your own hardware.
Below, you will find the executive summary of the technical report and its table of contents. You can download the full report here. Enjoy!
Executive Summary
This report presents a reproducible and comprehensive performance comparison between Vespa (8.427.7) and Elasticsearch (8.15.2) for an e-commerce search application using a dataset of 1 million products. The benchmark evaluates both write operations (document ingestion and updates) and query performance across different search strategies: lexical matching, vector similarity, and hybrid approaches. All query types are configured to return equivalent results, ensuring a fair, apples-to-apples comparison.
Vespa demonstrates significant query performance, scalability, and update efficiency advantages.
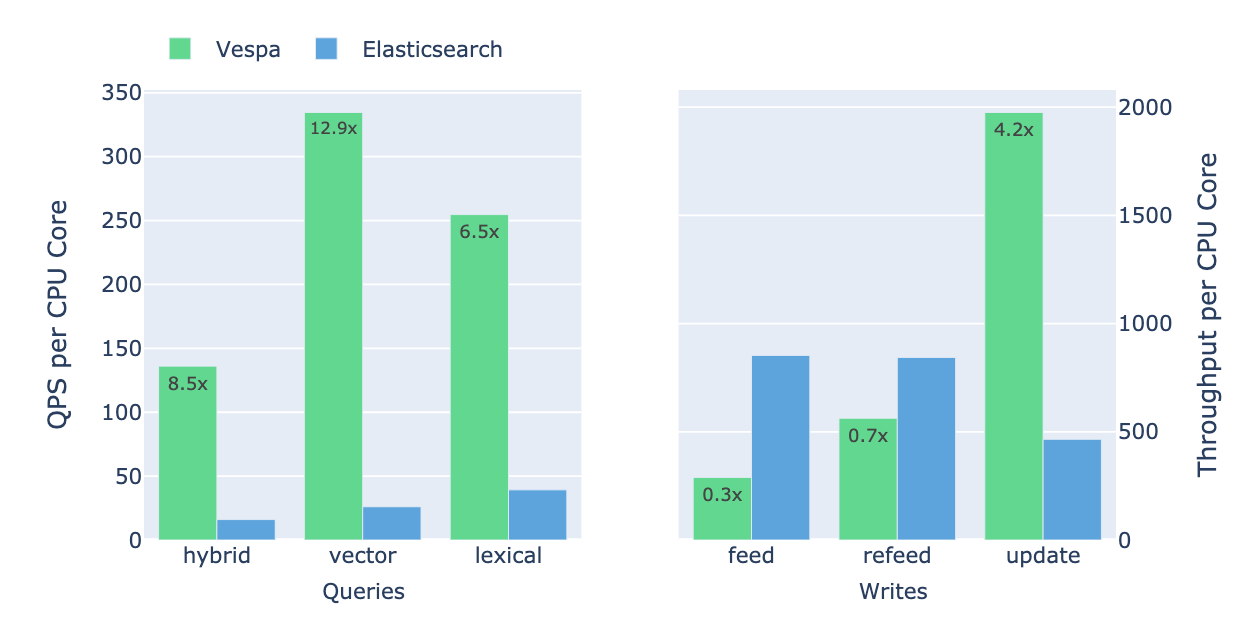 The illustration shows queries per second per CPU core for different query types and reveals Vespa’s significant query efficiency advantages:
The illustration shows queries per second per CPU core for different query types and reveals Vespa’s significant query efficiency advantages:
- Hybrid Queries: Vespa achieves 8.5x higher throughput per CPU core than Elasticsearch.
- Vector Searches: Vespa demonstrates up to 12.9x higher throughput per CPU core.
- Lexical Searches: Vespa yields 6.5x better throughput per CPU core.
Updates: Vespa is about 4x more efficient than Elasticsearch for in-place updates. While Elasticsearch demonstrates high efficiency during the initial write (bootstrap from 0 to 1M) phase, Vespa excels in steady-state operations, handling queries and updates more efficiently.
The following illustration compares how both systems handle hybrid queries, showing the relationship between latency, CPU usage, and query throughput as user concurrency increases.
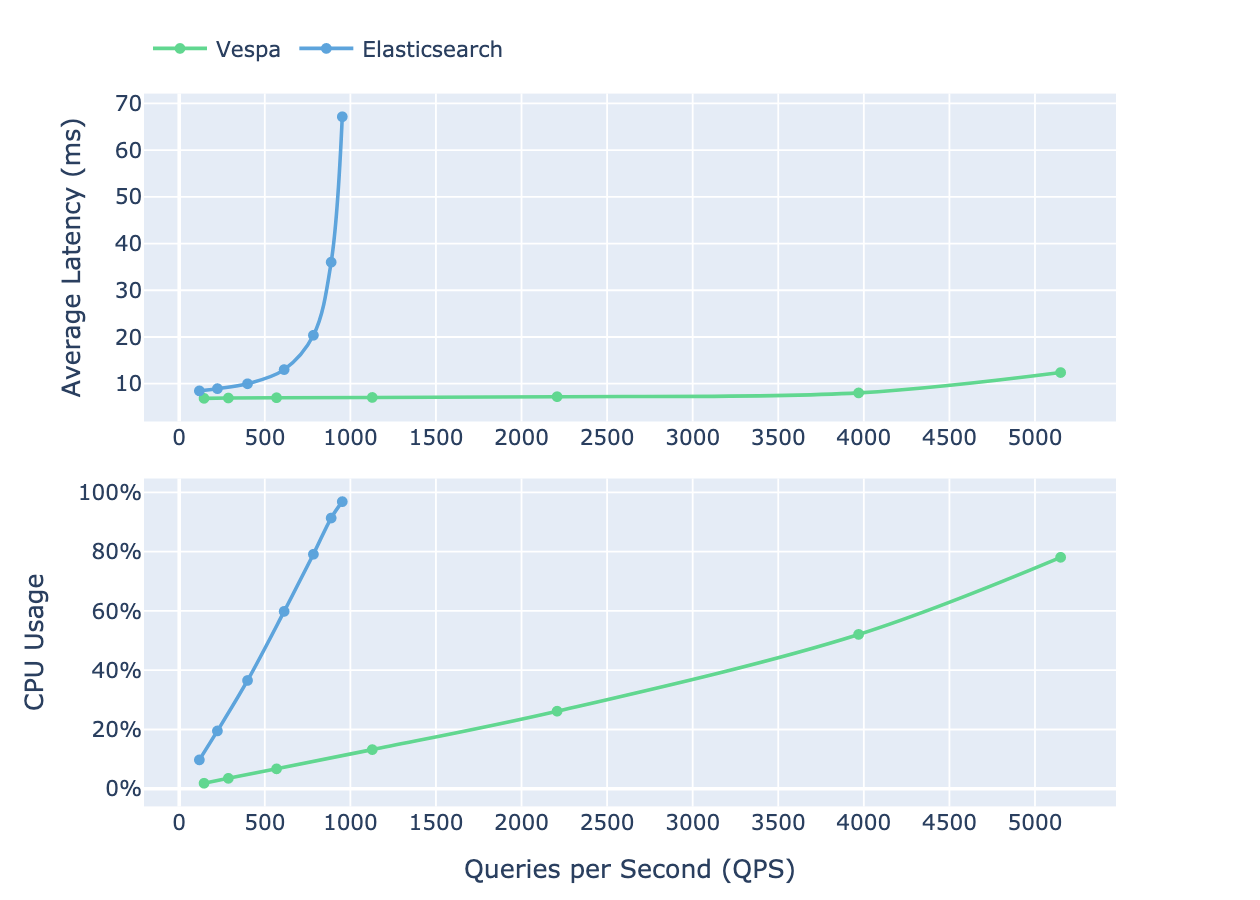 Vespa shows higher CPU efficiency, demonstrated by a lower CPU usage gradient compared to Elasticsearch. This superior performance efficiency directly reduces infrastructure costs, as demonstrated in section 10 of the report, where the efficiency improvements yield up to 5x reduction in infrastructure costs.
Vespa shows higher CPU efficiency, demonstrated by a lower CPU usage gradient compared to Elasticsearch. This superior performance efficiency directly reduces infrastructure costs, as demonstrated in section 10 of the report, where the efficiency improvements yield up to 5x reduction in infrastructure costs.
The findings of this report align with feedback from organizations that have migrated their e-commerce solutions from Elasticsearch to Vespa. In “Vinted Search Scaling Chapter 8: Goodbye Elasticsearch, Hello Vespa Search Engine”, they summarize their migration experience with the following:
The migration was a roaring success. We managed to cut the number of servers we use in half (down to 60). The consistency of search results has improved since we’re now using just one deployment (or cluster, in Vespa terms) to handle all traffic. Search latency has improved by 2.5x and indexing latency by 3x. The time it takes for a change to be visible in search has dropped from 300 seconds (Elasticsearch’s refresh interval) to just 5 seconds. Our search traffic is stable, the query load is deterministic, and we’re ready to scale even further.
Table of Contents
1. Executive Summary
2. Table of Contents
3. Preface
4. Benchmark Use Case & Dataset
4.1 Dataset
4.2 Workloads
4.2.1 Write workloads
Initial writing of product documents
Updating the price of each product by rewriting all documents again
Updating the price of each product by partial update.
4.2.2 Query workloads
5. Elasticsearch vs Vespa Architectural Differences
5.1 Write Path
5.1.1 Write APIs
5.1.2 Real-time
5.1.3 Data structures
Inverted indices
Columnar store
Raw document store
HNSW index for Approximate Nearest Neighbor Search (ANN)
Fundamental data structure differences
Mutable versus immutable data structures
Vespa’s mutable and immutable mix
Apache Lucene segments
Segment merges
5.1.4 Threading
5.2 Query Path
5.2.1 Threading
5.2.2 Lexical search (accelerated by Weak AND)
5.2.3 Vector search using Approximate Nearest Neighbor (ANN) search
5.2.4 Hybrid search
5.2.5 Pre-filtering and post-filtering
5.3 Other Aspects
6. System Configuration
6.1 Hardware Specifications and Software Versions
6.2 Schema
6.3 Queries
6.3.1 Lexical search - accelerated by Weak AND
6.3.2 Vector search
6.3.3 Hybrid search
6.3.4 Result set comparison
6.4 Elasticsearch Refresh Interval
6.5 JVM and Thread Pool Settings
6.6 Test Procedure
7. Description of Sampled Metrics
7.1 Writes
7.2 Queries
7.3 Ratios
8. Results
8.1 Writes
8.2 Queries
8.2.1 Fixed number of clients
Queries with fixed concurrency and no feeding
Queries with fixed concurrency during refeeding
8.2.2 Scaling with increased load & concurrency
Hybrid search
Lexical search
Vector search
8.3 Results Summary
9. Summary
9.1 Key Performance Differences
9.2 Implications of Performance Differences
10. Cost Example
11. How to Reproduce
11.1 Prerequisites
11.2 Run Performance Tests
11.3 Create Report
Appendix A: Other Test Results
A.1 Fixed number of clients
A.1.1 Queries with fixed concurrency and no feeding
A.1.2 Queries with fixed concurrency during refeeding
A.2 Scaling with increased load & concurrency
A.2.1 Hybrid search
A.2.2 Lexical search
A.2.3 Vector search
A.3 Impact of less capable hardware
A.3.1 Overall
A.3.2 Feed Performance
A.3.3 Query Performance
