Video search use cases are emerging in Enterprise search. During recent conversations at a conference, a handful of prospects approached us inquiring if Vespa could help with video search challenges.
These prospects weren’t just looking to search through transcripts. Their use cases ranged from customer service teams needing to locate a specific service process in training videos by just providing a description in natural language to financial analysts wanting to parse quarterly earnings call recordings for key insights.
One approach of converting audio to text using models like OpenAI Whisper provides a foundation. However, some use cases warranted something more sophisticated – the ability to search based on the visual content and context within their videos for a more accurate retrieval. Simply breaking videos into individual frames and generating image embeddings would be both computationally intensive and semantically limiting, missing the temporal relationships and context that make video content unique.
These use cases required a purpose-built video embedding model that could capture these nuanced relationships. This search led to TwelveLabs, a promising solution to bridge this technological gap.
TwelveLabs
TwelveLabs offers a state-of-the-art multi-modal embedding model. According to TwelveLabs, the video embeddings generated capture all the subtle cues and interactions between different modalities, including:
- Visual expressions
- Body language
- Spoken words
- Overall context of the video
TwelveLabs’ state-of-the-art multi-modal embedding Marengo-2.7 model creates video embeddings that encapsulate the essence of all these modalities and their interrelations over time.
Additionally, TwelveLabs provides Pegasus-1.2, a state-of-the-art multimodal AI model designed for advanced video-language understanding and interaction. This model can generate metadata about the videos.
While TwelveLabs provides a complete API for video indexing and search, we’ll focus on using the text generation capabilities of the Pegasus-1.2 model to generate searchable text attributes that give more information on the videos, as well as the Embed API to generate embeddings that we can store and search in Vespa, combining the strengths of both solutions. We have developed step-by-step self-explanatory Python notebooks for this purpose.
Vespa for Video Search Use Cases
Vespa offers a high-quality retrieval platform for storing and searching videos at scale. Below, we explore some of Vespa’s platform features that make it suitable for video search use cases.
Billion Scale Vector Search
Vespa offers platform-native optimizations to run vector search at scale.
These optimizations include the ability to perform approximate nearest neighbor searches using an HNSW index, which balances speed and accuracy when performing semantic search on large datasets.
Vespa also supports a multi-vector representation of embeddings. In this use case, this approach is practical as it allows storing various attributes of a video, such as:
- URL
- Title
- Keywords
- Summary
- Video chunks stored as multi-vector embeddings within a single document (one document per video).
Hybrid Search
Vespa allows performing hybrid search on videos, combining:
- Full lexical search
- Exact matching based on some attributes
- Semantic search on the content of the video
Vespa’s hybrid search capabilities improve retrieval quality. For instance, a hybrid search could:
- Combine full-text search across video metadata
- Perform semantic search to understand the context and meaning of the video
- Match specific metadata attributes
Using the TwelveLabs API text generation capabilities, we have enriched the videos with the following metadata:
- Keywords
- Video summary
This metadata enables various search combinations. A hybrid query can:
- Search for text within video summaries and titles
- Filter by specific attributes like keywords
Using the video document design discussed earlier, the notebook demonstrates a hybrid query that combines semantic video search with lexical search on the text attributes of the video.
Advanced Multi-Phase Ranking
Video search presents a unique challenge: How do you efficiently find and rank the most relevant clips among millions of videos with hundreds of segments or chunks each? This is where Vespa.ai’s ranking capabilities help.
Vespa offers flexibility in ranking search results. You can craft custom ranking expressions that combine traditional lexical ranking techniques with tensor-based approaches. You could also leverage machine-learned inference for personalized and advanced ranking.
However, ranking millions of videos quickly requires more than sophisticated algorithms – it demands efficient execution. This is where Vespa’s phased ranking approach comes into play.
Multi-phase ranking progressively applies more complex ranking criteria to an increasingly refined set of results:
- The first phase performs BM25 lexical ranking on the query terms to rank the top 10 qualifying documents (or more).
- The second phase performs semantic search over the video chunks, which is computationally more expensive.
Web-Scale Platform
Vespa operates as a distributed search platform designed for production workloads. The architecture delivers:
- Query responses in milliseconds
- Hundreds of thousands of queries per second
- Scalability for large video collections (millions of entries)
Vespa’s distributed architecture includes:
- Data redundancy across nodes
- Automatic failover mechanisms
- Self-healing capabilities to handle node failures
Real-world implementations demonstrate this scalability. For example, Spotify uses Vespa to power semantic search across their massive audio library, serving global users searching through millions of songs and podcasts.
Implementation
The notebook contains step-by-step instructions to generate embeddings using TwelveLabs’ SOTA model for a few sample cartoon videos available on the Internet Archive.
The process involves:
- Sign-up for trial accounts on Vespa Cloud and Twelvelabs.
- Generate descriptive text attributes for videos using TwelveLabs Pegasus-1.2.
- Create video embeddings using TwelveLabs’ Embed API.
- Deploy a Vespa application with the required schema and ingest the data.
- Perform search queries and review the results.
Example run from the notebook - the query is “Santa Claus on his sleigh” - observe how the best matching video segments are returned, this image is from 20:15-20:27:
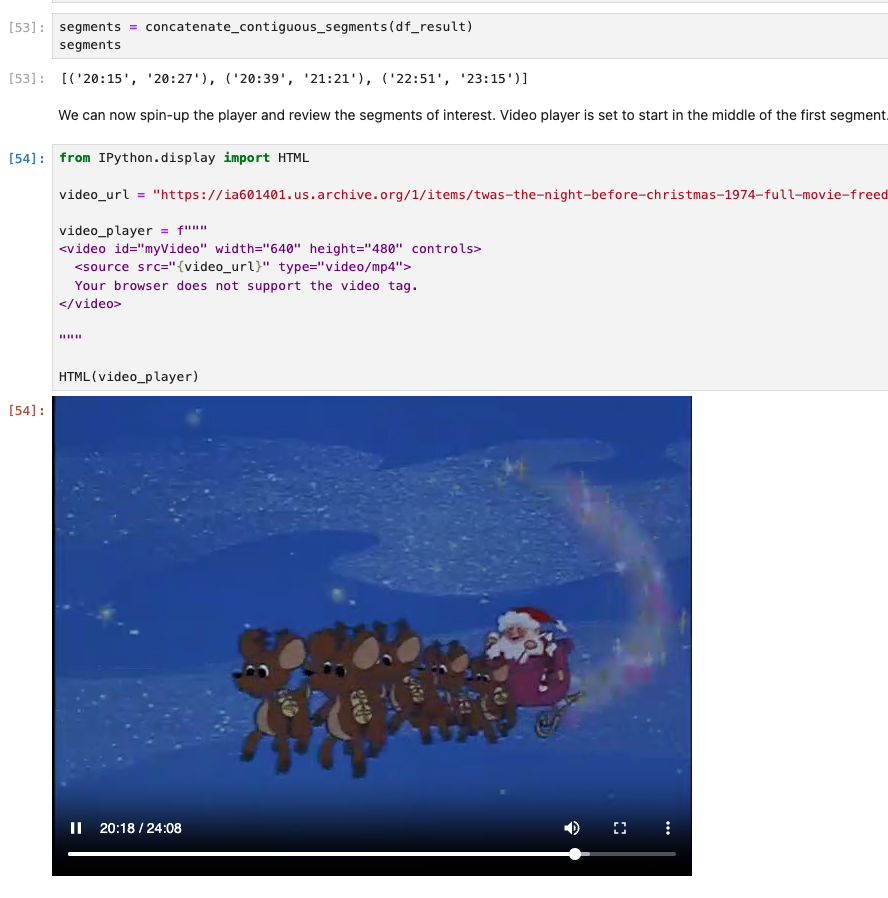
Please run the notebook yourself, it will take some minutes to process, and experiment with different query to match new segments!
Next Steps
This quickstart guide demonstrates an implementation of advanced video retrieval at scale. To go deeper into retrieval and ranking strategies, explore additional resources and technical guides available at:
Check out the TwelveLabs blog: Multivector Video Retrieval with TwelveLabs and Vespa!