

A New Bot: Dawn of a Vespa-Powered Slack Renaissance - A Summer Internship Story

Prologue
Discover how we harnessed the power of Vespa.ai to build an evolving Slackbot that learns and adapts with every interaction!
Vespa.ai saw a dramatic rise in interest in early September 2023, with pulls from vespaengine/vespa soaring from 2M to 11M in just a few months. This surge led to a flood of questions on their Slack channel. To handle the overwhelming number of queries and improve user experience, Vespa introduced search.vespa.ai. This Retrieval-Augmented Generation (RAG) system breaks down all documentation, sample apps, blog posts, and more into paragraphs, which are retrieved and sent to OpenAI for summarization. (Read more)
Vespa’s Slack Channel effectively provides a rich knowledge base for answered questions. This wealth of information is the perfect foundation for an RAG system, one of Vespas’s planned summer intern tasks for 2024.
Join us, two NTNU students, on a summer internship at Vespa. Our mission? To embark on a learning journey and create an intelligent Slackbot that uses Vespa to answer questions based on past conversations and documentation. This blog post chronicles our journey, detailing our steps to bring this project to life, from the initial idea to the final deployment.
We will delve into:
- How we set up the Slack bot
- How a Slack bot works
- Schemas and rank profiles
- Deploying with GCP and Terraform
- Our experience working at Vespa
The Vespa Community Slack Bot - The Hero of our Story
The Vespa Community Slack Bot has the following requirements:
- Users can write
@Vespa Bot <question>to ask questions to the bot - The bot bases its answer on previous conversations and Vespa’s Documentation Search
- A
/helpcommand - Users must consent that they agree to the bot sending their questions to OpenAI
- Users can allow indexing of their messages to improve the bot
- The bot has to anonymize users
- Users can provide feedback with 👍 and 👎 reactions
The bot should feed every message (with users’ consent, of course) posted in the Slack channel into a Vespa app. When a user asks a question, the bot should query the Vespa app to retrieve the best-ranked individual messages. The messages are then grouped by their respective threads or conversations, using the maximum relevance score of the messages in each thread.
How a Slackbot works - Understanding the Hero
A Slackbot is a program that responds to events such as mentions or messages. It can reply with either a chat message, private message, direct message (DM), or a view (modal). Developing a Slackbot using Slack’s SDKs is straightforward. For example, we used the Slack SDK for Java in our implementation.
A Slackbot can either run in Socket Mode or as an HTTP server:
- Socket Mode: The bot connects to the Slack API and is ready to receive events generated from the servers. Socket Mode is the recommended mode during development.
- HTTP Server: When running the bot as an HTTP server, you need to specify the IP of your Slackbot server inside the Slack API page. HTTP Server is the recommended mode for deployment.
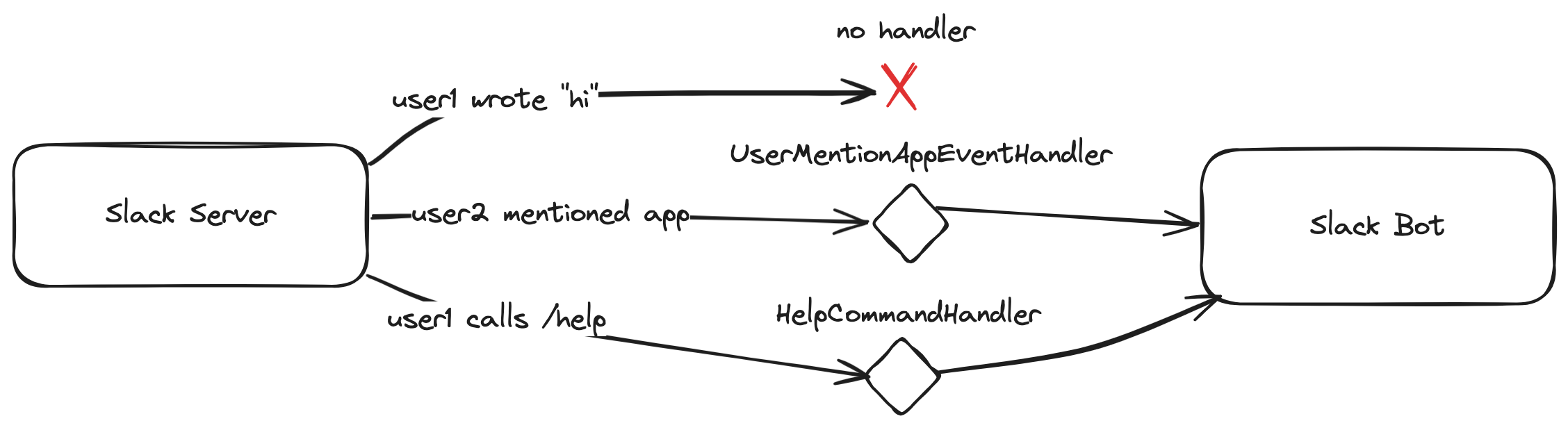
Setting up the Slackbot with Kotlin - Setting the Stage
Neither of us had created a Slackbot before, so we made a quick Google search and found a tutorial on how to do it: Getting Started with Bolt for Java.
We created the bot in Kotlin (because it is fun) and used Gradle as the build system. By following the tutorial, we initially ended up with something that looked like this:
package ai.vespa.community_slackbot
fun main() {
// Create a slack app called app
app.event(AppMentionEvent::class.java) { req, ctx ->
// this event happens every time a user write "@Vespa Bot"
val text = req.event.text
val ts = req.event.ts
ctx.client().chatPostMessage { p ->
p.text(generateVespaSummaryFromQuery(text)).ts(ts)
}
}
app.event(MessageEvent::class.java) { payload, ctx ->
// this event happens every a message is sent from a user in a channel
val text = payload.event.text
val messageId = payload.event.ts
val newThread = event.threadTs == null
// in slack a message is not a thread until it has a reply,
// so the thread has the same id as the first message
val threadId = if (newThread) event.ts else event.threadTs
storeMessageInVespa(text, messageId, threadId)
}
app.start() //which starts the server
}
This is a gross simplification of our work for brevity. However, the code snippet shows the essence of what the bot does. Whenever a user mentions the bot with @BotName, the handler for AppMentionEvent will be called. It should query the Vespa app for a summary of the conversations that match the question. Whenever a user writes a message, the MessageEvent handler will be called to feed that message to the Vespa app.
At a later stage, it was easy to extend the program further, adding slash commands for /help and listening for emoji reactions to messages.
Setting up the Vespa Application Schema - Developing the Hero
With our basic Kotlin app in place, we were ready to dive into the Vespa application to store messages and search conversations. Following their News sample app tutorial, we went from humble beginners to tackling advanced methods involving LLMs in no time. It felt like upgrading from a tricycle to a turbocharged sports car.
Typically, we would have to create a new Vespa application that uses the RAGSearch component. However, since our app should integrate with the existing search.vespa.ai system, we had to extend the already existing Documentation Search Backend with our schemas and searchers.
schema slack_message {
document slack_message {
field message_id type string {
indexing: summary | attribute | index
match: word
}
field thread_id type string {
indexing: summary | attribute | index
match: word
}
field text type string {
indexing: summary | index
stemming: best
}
}
field text_embedding type tensor<float>(x[384]) {
indexing: input text | embed embedder | attribute | index
attribute {
distance-metric: angular
}
}
fieldset default {
fields: text, thread_id
}
document-summary short-summary {
summary text {}
summary thread_id {}
}
}
We included message_id just for deletion purposes if, for example, users delete their messages in Slack. The thread_id field is used for grouping, which means that we take all hits from a search of Slack messages and create hit groups based on who has the same thread_id.
In addition to these fields, we also have a synthesized field (embeddings) called text_embedding. Vespa automatically generates this field when you insert a new slack_message or update a slack messages text field. This field enables us to do a more sophisticated ranking utilizing vector space. To show how this works, let’s have a look at the rank profile, which is the math behind how Vespa should rank the documents:
schema slack_message {
# fields ...
rank-profile hybrid2 {
inputs {
query(q) tensor<float>(x[384])
}
function scale(val) {
expression: 2 * atan(val / 4) / 3.14159
}
function semantic_text() {
expression: cos(distance(field, text_embedding))
}
function scaled_bm25_text() {
expression: scale(bm25(text))
}
first-phase {
expression: 0.7 * semantic_text + 0.3 * scaled_bm25_text
rank-score-drop-limit: 0.0
}
}
}
A lot is going on here. However, the essence of the approach is that the user’s question is converted into an embedding (a vector representation of the text). Using the cosine distance, this embedding is compared to the text_embedding tensor (the text in the message we are comparing against). The result of the cosine distance function is a value between -1 and 1. This value is interpreted as how similar in n-dimensional space the query is to the text.
In addition to semantic comparison, we use the classical information retrieval technique BM25 throughout the corpus to determine the relevance of the document we are searching for. We can obtain a value between -1 and 1 through the scale function, allowing us to compare this against the semantic results.
We also have a function that compares the number of 👍 against 👎 (emoji reactions on Slack), which will alter the ranking to favor those who provide good replies and ask good questions. This value also produces a value between -1 and 1.
Deploying to GCP
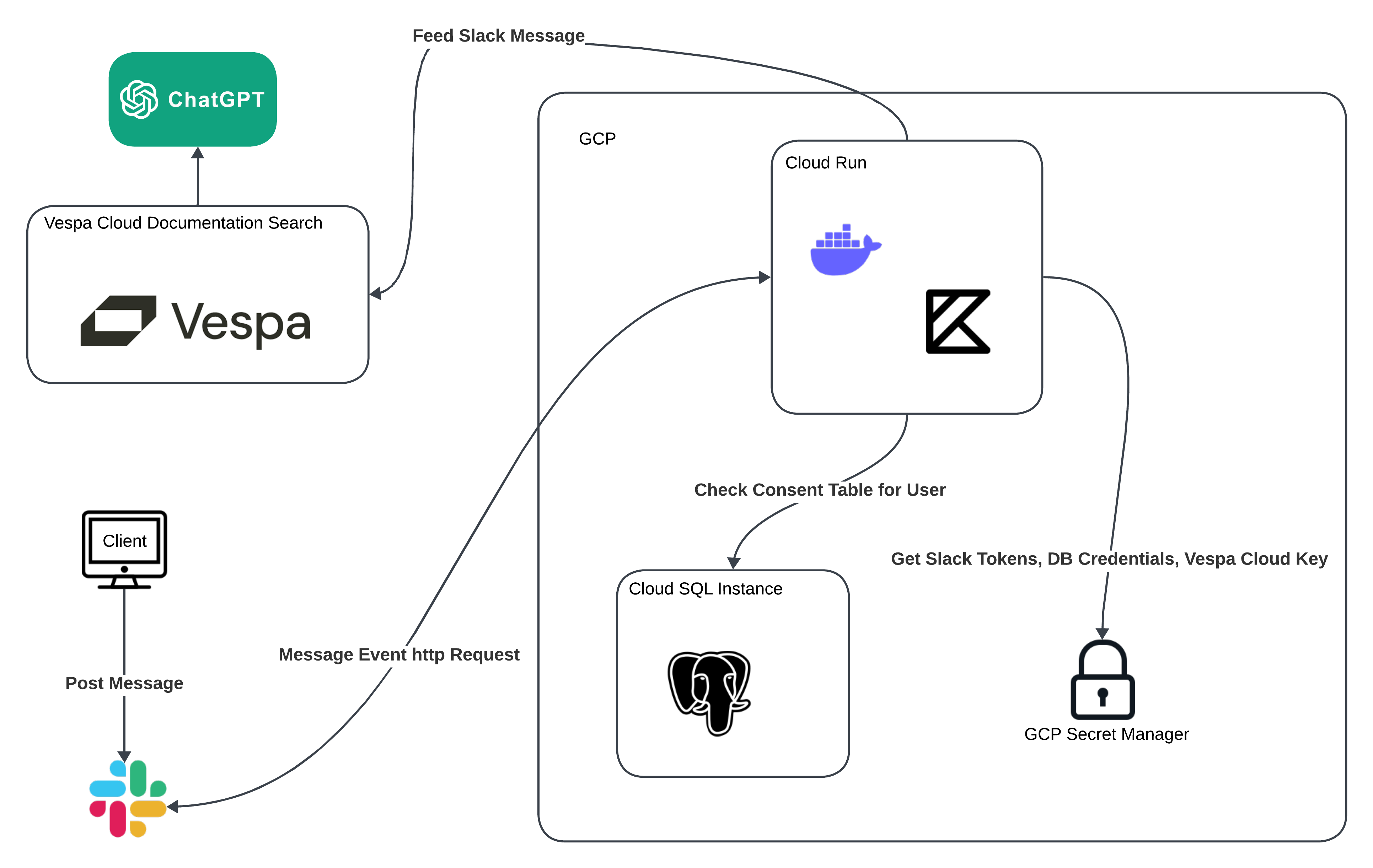
Terraform - The Obstacle of this Journey
No epic story is complete without a formidable adversary; in our journey, that adversary was Terraform. While Terraform is an incredibly powerful tool for infrastructure as code (IaC), it posed unique challenges in our quest to build the perfect Slackbot. Terraform’s complexity and steep learning curve often felt like navigating the dark side of automation, making the integration process more complicated than we initially anticipated.
With no experience with Terraform, we climbed Mount Doom with Andúril in hand, the West’s flame reforged, and conquered the beast with four hands.

Terraform’s initial configuration hurdles and intricate state management threatened to derail our project at multiple stages. Each misconfiguration and state conflict felt like a battle against an invisible Sith Lord. However, these challenges also pushed us to innovate and adapt (meaning learning some Terraform), ensuring our Slackbot not only survived but thrived.
SpaceLift - The Yoda of this Story
Every journey has a mentor who helps the hero overcome their toughest challenges. For us, that mentor was SpaceLift, the goated IaC platform already used by Vespa. Just like Yoda guided Luke Skywalker, SpaceLift gave us the tools we needed to master Terraform.
SpaceLift joined our project as a much-needed source of hope, offering features that made Terraform easier to manage. Its remote handling of Terraform state and smooth integration were game-changers. While Terraform alone felt tricky and complicated, SpaceLift made it a powerful and precise tool in our infrastructure toolkit.
That’s it
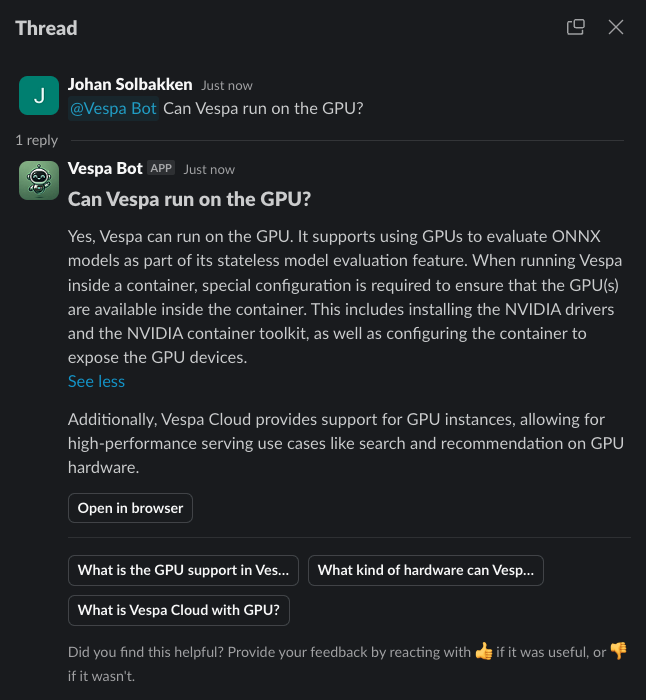
We now have a working Slackbot powered by Vespa and OpenAI capable of learning from conversations. It was that easy! Our implementation is a bit more sophisticated and includes features like:
- handling user consent,
- feedback mechanisms,
- and user anonymization.
The Slackbot will continuously index new messages to enhance its ability to provide users with more accurate and relevant feedback. As it receives and processes more interactions, its capabilities and accuracy will improve, offering a better user experience over time.
Our experience working at Vespa.ai - Epilogue
This summer has been incredibly fun and rewarding! Every day, we had an “interns catchup meeting” just before the whole Vespa team standup. During these meetings, we discussed our tasks, challenges, and successes. These meetings were constructive and boosted our productivity, making it easier to solve problems and achieve our goals.
The Vespa.ai documentation was excellent, and we received fast responses from team members whenever we encountered problems. The people at Vespa are not only incredibly supportive but also exceptionally talented. They consistently referred us to the right experts and provided us with quick and effective solutions when needed.
Working at Vespa.ai was amazing, from the supportive and smart people to the challenging yet fun tasks. The working atmosphere was always positive, with plenty of space for humor and laughs. Vespa’s culture of innovation and excellence is truly inspiring, and we are grateful for the opportunity to be a part of such an outstanding team.
Conclusion
In conclusion, our summer journey at Vespa.ai has been nothing short of transformative. We not only built a powerful Slackbot that learns and adapts but also gained invaluable experience working alongside a brilliant and supportive team—an adventure we’ll carry with us into our future endeavors.