

Photo by Firmbee.com on Unsplash
Introduction
Although a picture is worth a thousand words, preparing visually rich, multi-modal documents, such as PDFs, for a retrieval-augmented generation (RAG) workflow can be both time-consuming and error-prone. In industries where accuracy is critical, like healthcare or financial services, documents like radiology reports or financial statements often contain images or charts that provide valuable contextual information. While these visually rich elements are often left out of RAG workflows, a new approach for retrieving information from visually enhanced documents is set to streamline multi-modal document preparation and transform the potential of RAG and generative AI (GenAI).
Most retrieval systems focus primarily on text-based representations and are blind to the document’s visual elements, such as images, tables and layouts, which are essential for effective information comprehension. Focusing on text alone can reduce retrieval effectiveness, especially when visual features are key to understanding the document’s content. Visual elements allow readers to quickly interpret structured data, grasp hierarchical organization, and access contextual explanations that text alone may not clearly convey.
Additionally, processing steps for a typical real-world RAG pipeline for PDFs (or other complex formats) can be time-consuming, involving steps like:
- Extracting text and metadata
- Optical character recognition (OCR)
- Layout analysis, extracting tables, charts, pie charts, etc.
After completing the processing steps for obtaining text representations, the text can then be used as input for retrieval systems.
A new approach is needed to simplify preprocessing and enhance the relevance of retrieved information in document-heavy contexts. Contextualized Late Interaction over PaliGemma (ColPali) offers a solution by embedding the entire rendered document—including its visual elements—into vector representations optimized for retrieval. This architecture, designed for Retrieval-Augmented Generation (RAG), effectively captures both textual and visual content, making document retrieval more accurate and contextually relevant.
How ColPali Improves Document Retrieval
By treating documents as visual entities rather than text, ColPali opens up new possibilities for more accurate and context-aware document retrieval, especially for visually rich content. ColPali represents a step forward in document retrieval by:
- Eliminating the need for complex preprocessing steps
- Preserving the visual context of documents
- Enabling more holistic document understanding
- Streamlining the RAG pipeline
In bypassing traditional text extraction and OCR processes, ColPali not only simplifies the retrieval process but also has the potential to enhance the quality and relevance of retrieved information in RAG systems. ColPali’s architecture builds upon two key concepts: contextualized vision embeddings from vision-language models (VLMs) and late interaction mechanisms.
Vision Embeddings
ColPali uses PaliGemma models, which are lightweight VLMs created by Google for general tasks like image-text compression. VLMs offer a unique advantage over traditional text-only models by integrating visual and textual data, allowing them to tackle complex tasks that require a comprehensive understanding of visual context, such as interpreting images, generating descriptive text for visual inputs and answering questions based on visual cues.
Using PaliGemma, ColPali can create high-quality contextual embeddings directly from document images without complicated steps like text extraction, OCR or layout analysis. This streamlined approach makes indexing faster and easier, improving the efficiency of document retrieval. Once the documents are retrieved, the generative phase in RAG systems can focus on processing and summarizing the most relevant ones using text and visual information.
In the example below, a search was performed for the word helmet. As you can see, the returned document doesn’t include the term helmet in the text. It does, however, have a photo of people wearing helmets in an image on the document. Colpali understands documents not just by reading the words but by truly seeing and interpreting the visual information on the page.
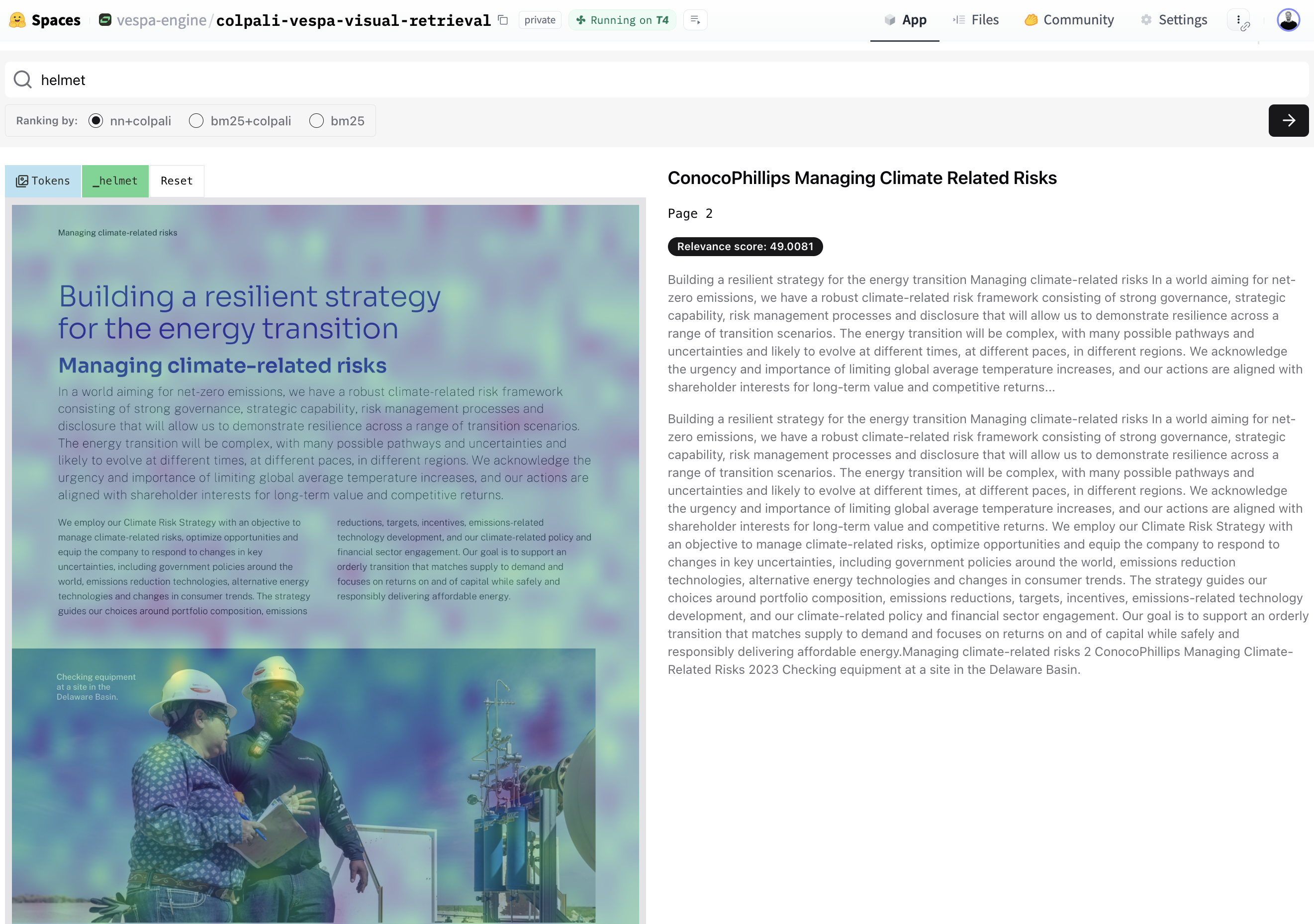
The model’s ability to use both visual elements and text allows for a more comprehensive understanding of document content and produces more relevant signals to use in ranking and filtering. This approach enables ColPali to find relevant documents that traditional text-only methods might miss, especially in cases where visual information is essential, like financial reports with charts or scientific papers with diagrams and figures.
Late Interaction Mechanisms
During the retrieval stage, an interaction describes the process of assessing how relevant a document is to a user’s query by comparing their vector representations. This comparison helps the system match documents to the query’s intent and content, leading to more accurate search results.
ColPali leverages a late interaction model, where query and document processing occurs independently until the final stages of retrieval. It utilizes the Maximum Similarity (MaxSim) scoring mechanism to compare the visual grid cell vector representations (the visual components of a page) with query text token vector representations (the user’s query), significantly enhancing retrieval precision. By executing these similarity comparisons at query time, ColPali sidesteps the computational burden of processing images and text simultaneously, optimizing the retrieval process. This method not only accelerates retrieval but also minimizes system resource usage, making it ideal for managing large-scale document collections with high efficiency.
Looking Ahead
Despite some limitations—such as reduced effectiveness with unstructured formats, non-English languages, or highly specialized fields without fine-tuning—ColPali’s architecture is its key strength and is expected to continue advancing and improving over time.
ColPali’s architecture sets a new standard for document retrieval, offering a flexible framework that can adapt to emerging VLMs. Benchmark results demonstrate ColPali’s superiority over traditional methods, signaling a paradigm shift in the field. ColPali paves the way for more sophisticated, contextually aware systems that revolutionize document interaction and understanding by efficiently integrating visual information into RAG pipelines. MaxSim is gaining significant attention for use cases like multi-vector searches and late interaction, yet its early implementation faces struggles with efficiency and scalability. A key solution to these issues involves conducting MaxSim computations directly where the tensor data is stored, which reduces the need for massive data transfers. Doing so while parallelizing the compute operations systems can achieve significant performance improvements. This approach unlocks the true potential of MaxSim, allowing it to handle large-scale operations seamlessly and elevate its reputation in high-demand applications.
With ColPali and Vespa, developers can build a complete RAG pipeline for complex document formats like PDFs using only the visual representation of the document pages. Vespa’s sophisticated tensor framework and compute engine seamlessly accommodate ColPali embeddings, allowing for the implementation of late-interaction scoring through Vespa ranking expressions. The Vespa Tensor Ranking framework enables complex operations on tensors, allowing users to write sophisticated ranking functions, such as those using the MaxSim (Maximum Similarity) approach. Vespa’s architecture allows in-place tensor operations and parallel processing, making it ideal for modern ranking tasks requiring high throughput and efficiency, such as multi-vector MaxSim interactions.
In multi-modal cases (like PDFs), both text and image data are used in ranking and filtering, producing multiple scores or signals input to the ranking function, often called hybrid ranking. Vespa allows combining the MaxSim score with other scores using, for example, reciprocal rank fusion or other normalization rank features. The sample application features examples of using ColBERT MaxSim in a hybrid ranking pipeline.
You can explore ColPali’s potential with our comprehensive notebook demonstrating how to utilize ColPali embeddings in Vespa. Dive into the world of visual document retrieval and experience the power of ColPali for yourself!
