Photo by Louis Reed on Unsplash
The future of GenAI in pharma and healthcare isn’t about building bigger models — it’s about smarter retrieval.
Originally presented at the Fierce Pharma Webinar: “You Have the Model, Now What? Lessons on Making AI Work in Life Sciences and Breaking the Chatbot Mirage.”
This is a five part quick read series that summarizes the panel discussion highlighting key topics of the conversations.
This recap of the Fierce Pharma x Vespa.ai panel distills how leaders from Novo Nordisk, Alkermes, and Harvard Medical School are reframing AI as a search and retrieval problem across lifesciences R&D, Commercial & Healthcare Providers/Payers. If you directly run into your subsections of interest, please go to the end of the blog for your specific industry.
→ Full video: fierce-pharma-webinar
From Chatbots to Context Engines
Search is the new foundation for intelligence.
Most enterprises now have an LLM strategy. The challenge? Turning demos into production systems that scale safely and meaningfully.
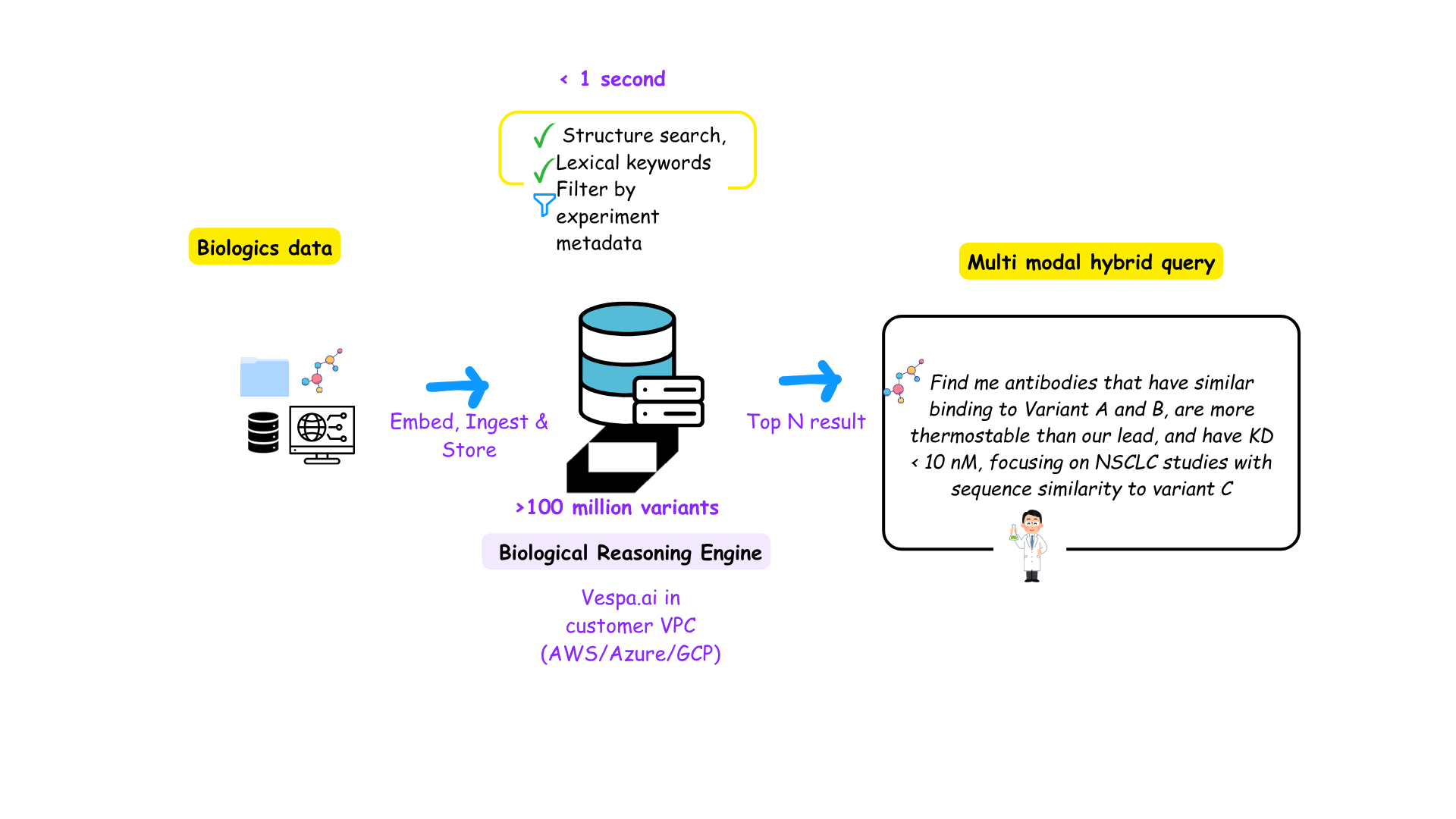
Vespa.ai’s Harini Gopalakrishnan opened it with the key challenges encompassed by all enterprises :
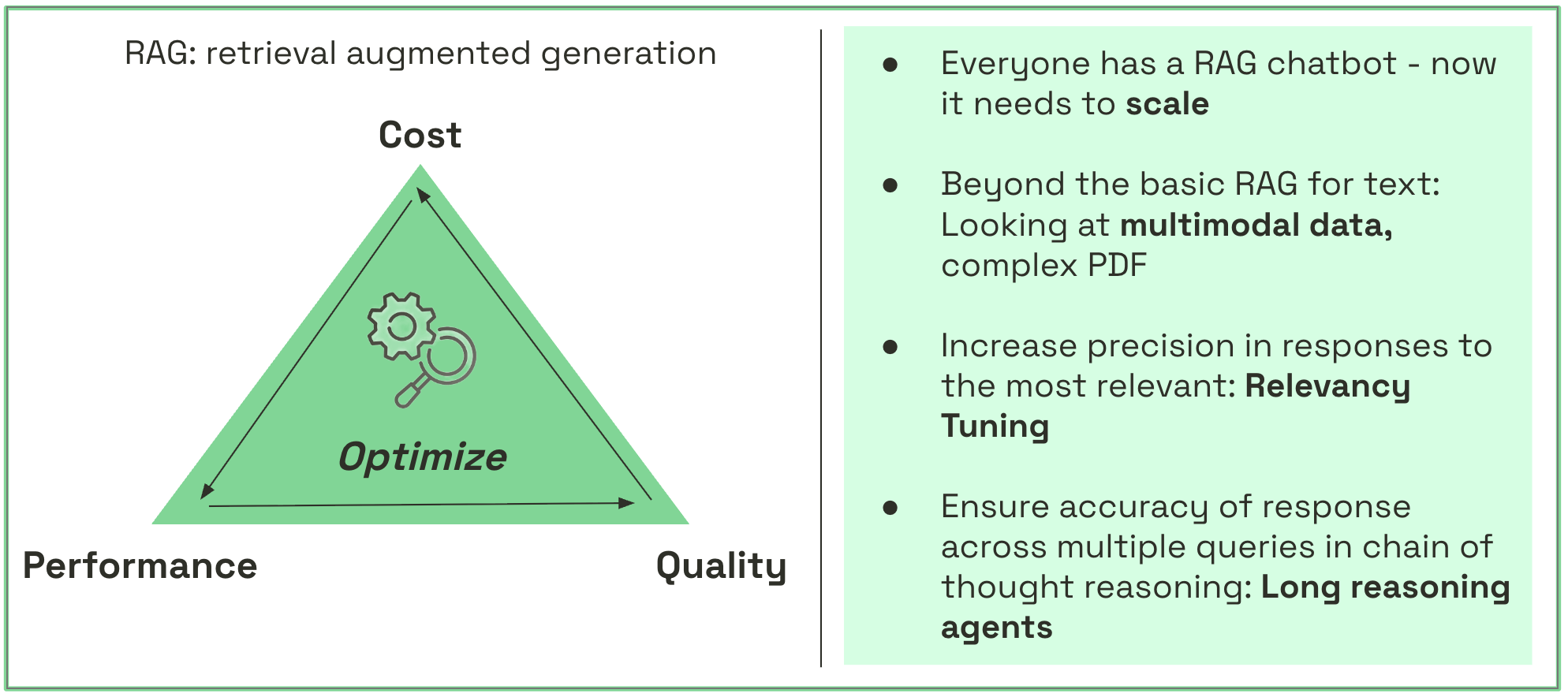
“Every RAG solution has to balance cost, performance, and quality — and that starts with how you design your context engine.”
What is context engineering?
RAG (retrieval-augmented generation) solutions today work on retrieving the most relevant information for a query from a large corpus of data called context and providing it to the LLM for summarization. Therefore, RAG systems succeed not because of the model’s size, but because of how well they search, retrieve, rank, and contextualize information.
It is especially true in a regulated industry like Health & Lifesciences, where traceability of responses and grounding large language models interpretations in factual data become vital. Hence the main takeaway of this discussion resonated across the following theme:
“AI in health & life sciences is becoming increasingly a search problem → one where retrieval precision determines clinical, commercial, and scientific accuracy. “
Read more: vespa-in-context-learning
“People associate prompts with short task descriptions you’d give an LLM in your day-to-day use. In every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step.”
-Andrej Karpathy on X
In the subsequent sections, we look at four different industries, offering various use cases on how this comes to life.
Retrieval Science: Lessons from Search-First Companies
Opening the discussion was to take a leaf out of bleeding edge search companies that have pioneered the art of “retrieval” like Perplexity, Spotify & others who solve for building advanced retrieval solutions. Their differentiators have focused on personalization and precision responses: “you get what you search for”
Kristian Aune, co-founder of Vespa AI and early Vespa engineer at Yahoo, explained therefore that retrieval is the “missing half” of generative AI.
“Large models only know what they’ve been trained on. Retrieval gives them memory, context, and trust.”
Increasing trust with purpose built retrieval systems
Models are trained on specific data but our questions to it can encompass information that the model might not have seen the responses for (like the ones hidden in internal documents). With RAG, the model can provide accurate results based not only on the user query, but also the data you provided to it. You, therefore control the data to a much higher degree.
And since you control the context for the model to provide the responses (and not what the model has been trained for), it leads to fewer wrong answers. The model’s reasoning on your context leads to reduced hallucinations and increased trustworthiness of responses. However all this requires one key ingredient: accuracy in retrieval at each step. And accuracy in ML language means finding the most relevant information based on a combination of input queries and other user signals. When context becomes king, retrieval quality is paramount.
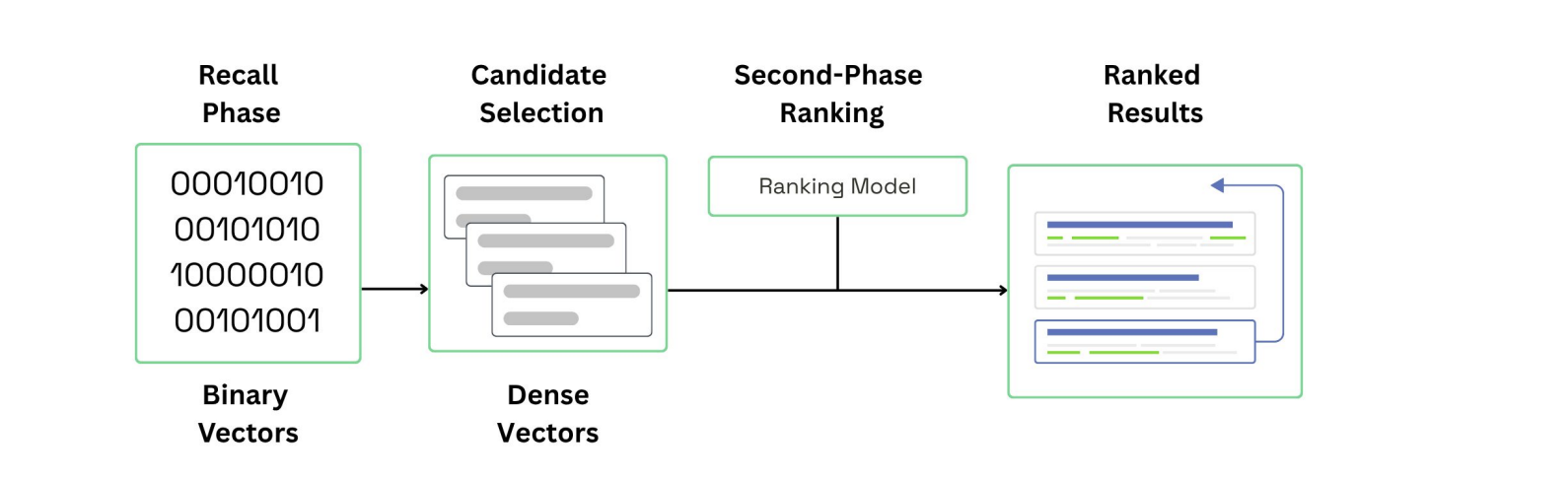
Phased ranking
Drawing parallels with Yahoo and Spotify, he outlined the need for leveraging multi-phase ranking: a tiered process that retrieves broadly, then refines iteratively to balance speed, cost, and accuracy — the same method enterprises need to power RAG systems in health & lifesciences.

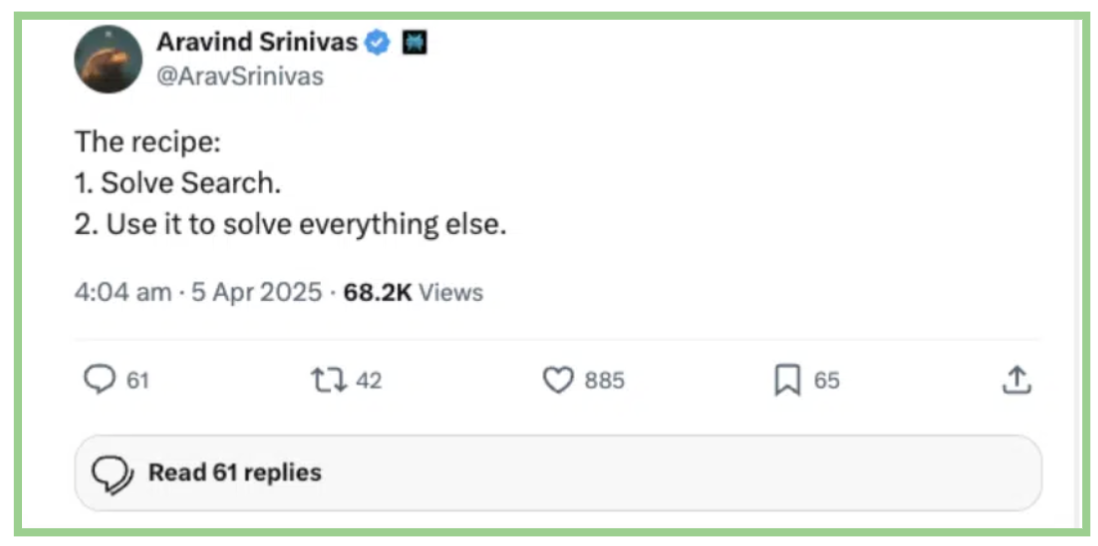
The Perplexity way
This is why Perplexity’s approach is based on a clear principle: the quality of AI answers depends on the quality of information retrieved. While many companies can access foundational LLMs, Perplexity differentiates by retrieving and ranking relevant content with precision so that responses are fluent, accurate, and grounded in fact. More details on the Perplexity use case are here.
Key Takeaways
-
Retrieval quality = model trustworthiness.
-
Context depth (signals, metadata, user intent) drives ranking accuracy.
-
Multi-phase retrieval enables scalable precision — the Vespa advantage.