
Hello, I am Yuhong, the CoFounder of Danswer. We connect all of the disparate knowledge sources of a team (like Google Drive, Slack, Salesforce, etc.) and make all of this available via a single search/chat interface and help users digest the content with GenAI. As one might expect, having a quality and performant search is absolutely core to our value proposition. Today I’ll share why we as a team decided to migrate to Vespa and why it was worth it even when it meant ripping out the core of our previous stack.
Background on the Migration
At Danswer, we’re making Large Language Models more intelligent by bringing in the context of the user and the knowledge of the organization. The way we do this is by retrieving relevant context before passing it to the LLM (Retrieval Augmented Generation - RAG for short). As we scaled to large enterprise scales of data, we discovered that our needs for fine tuning our search pipeline started to exceed the capabilities of our previous vector DB.
Challenges of Enterprise Search and Vespa to the Rescue
 Custom Boost and Decay Functions
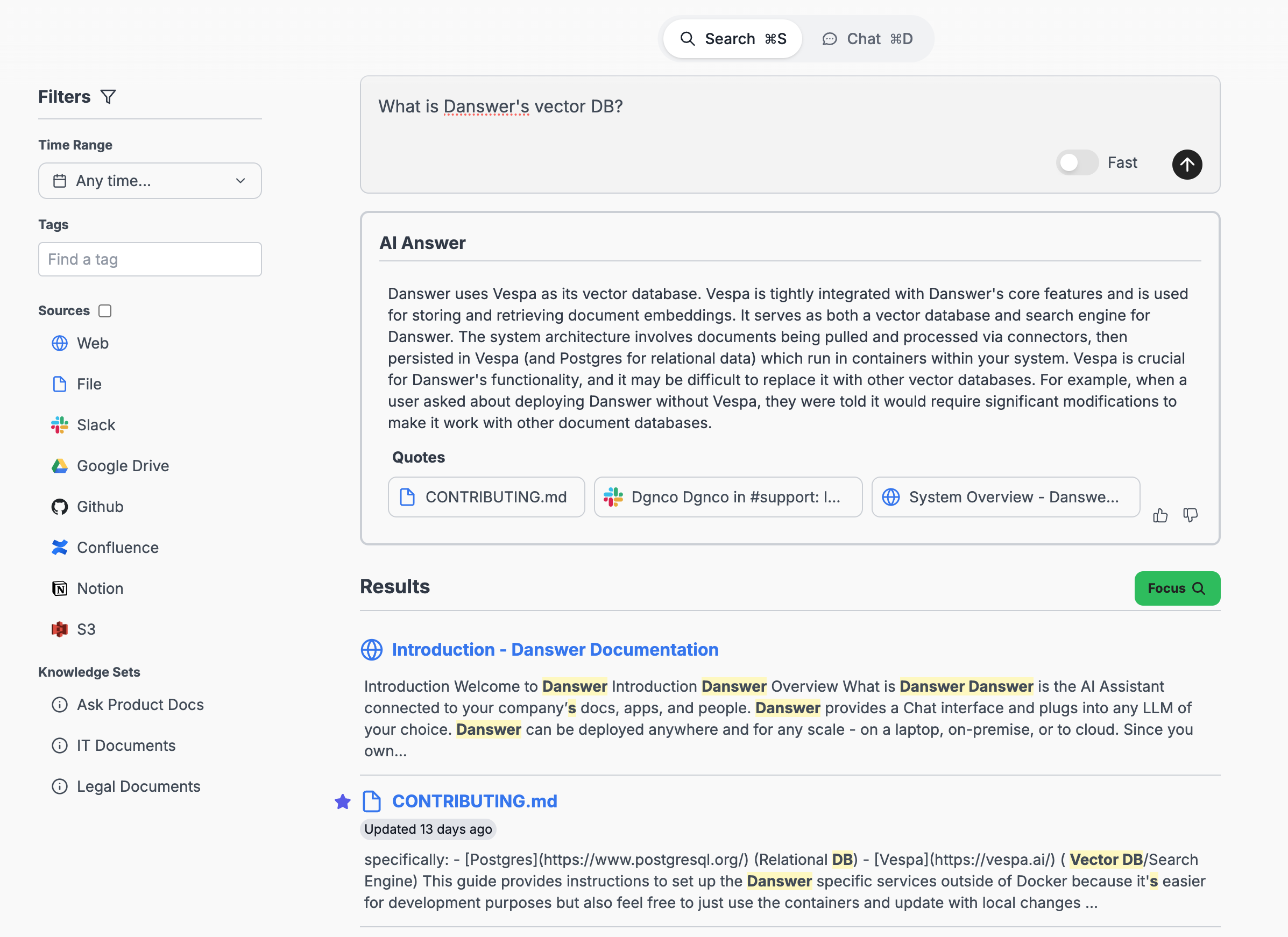
Custom Boost and Decay Functions
We previously used a vector only search but we discovered that a lot of team specific terms were critical for providing a quality experience to our users. Internal names like “Meechum” or “Foundry” were common but had no general English representation that the deep learning models could capture. So in response, we added a keyword search that was completely separate from the vector component. But this led to issues of weighting when the two could not be considered together. Vespa allows for an easy normalization across multiple search types and finally allowed us to achieve the accuracy we wanted.
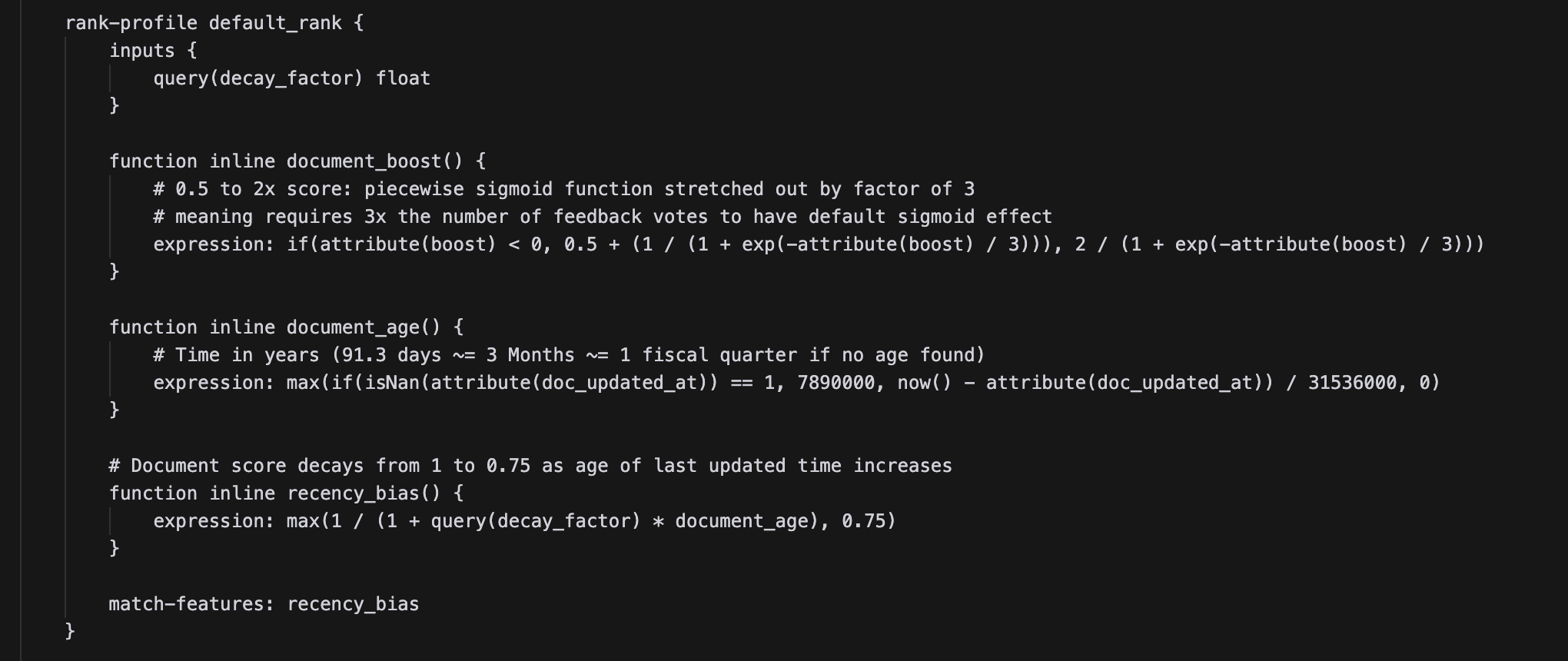
As our pipeline improved, we also introduced other features like time based decay. Since internal documents aren’t always cleaned up correctly, it’s fairly common to run into multiple versions of the same document with conflicting information. Our users asked us to support decaying the relevance of documents if nobody touches or reads them for a long period. At the search engine level, this translated to a requirement to have flexible document ranking functions during the search step. We needed to take a “time last touched” attribute and apply a decay based on the difference of the attribute value and the current time. Luckily Vespa has one of the most flexible syntaxes in terms of ranking functions and there were even plenty of examples of this exact use case which make the implementation really easy.
To capture both overarching contexts and specific details in the documents we index, we also implemented a multipass approach to indexing. This means every document is split into different sections for processing and each pass has a different size context. Vespa is (as far as I know) the only hybrid search engine that is capable of doing multiple vector embeddings for a single document. This optimization prevents duplication of documents for every section and every chunk size which greatly reduces the resources necessary to serve the document index. Since Danswer is largely a self-hosted software (for data security purposes), the savings on resources allows for more teams to use Danswer even if they don’t have access to powerful servers or large budgets for expensive cloud instances.
What brought us to Vespa
As an open source project we immediately limited our choices down to a smaller set of self-hosted options. At the time we were using two separate search engines (one for vector and one for keyword), both of which were relatively new players in the space. We were actually pleasantly surprised at how stable these new search engines were, however they were all built around being “easy to get going” and the actual feature sets were pretty limited. We tried to find hacks around the problems presented above (for example applying the time decay after the initial search as a post processing step), but these workarounds often suffered in accuracy once the scale of documents increased past several million. Of the most established projects, we were looking at OpenSearch, ElasticSearch, Weaviate and Vespa. Vespa was the clear leader in several ways:
- The most advanced NLP options including multiple vectors per doc, late interaction models like ColBERT, different nearest neighbor implementations, etc. We knew we would be using the latest techniques so picking a project that was the most on the cutting edge felt like an easy choice.
- Vespa is permissively licensed, the entire repo is apache-2.0 licensed which means it could be used for anything including building commercial software.
- Scale would never become an issue with Vespa, we were serving scales of up to tens of millions of documents per customer but Vespa was built for internet scales of data (previously serving Yahoo’s search).
Challenges

Vespa is definitely a developer facing software. If you’re more of a weekend hacker whose goal is to prototype something quickly and make a Medium or LinkedIn post about it, Vespa may not be the right choice for you. The downside of flexibility is that there is inherently more complexity with all of the configuration, deployment and even query/indexing options. We’re still in the process of understanding their multi-node kubernetes deployments but luckily Vespa Cloud provides a managed service where all of this complexity is instead managed by the experienced Vespa team. For Danswer Cloud, we’re currently in the process of migrating from our self-managed Vespa running on AWS to Vespa Cloud instead.
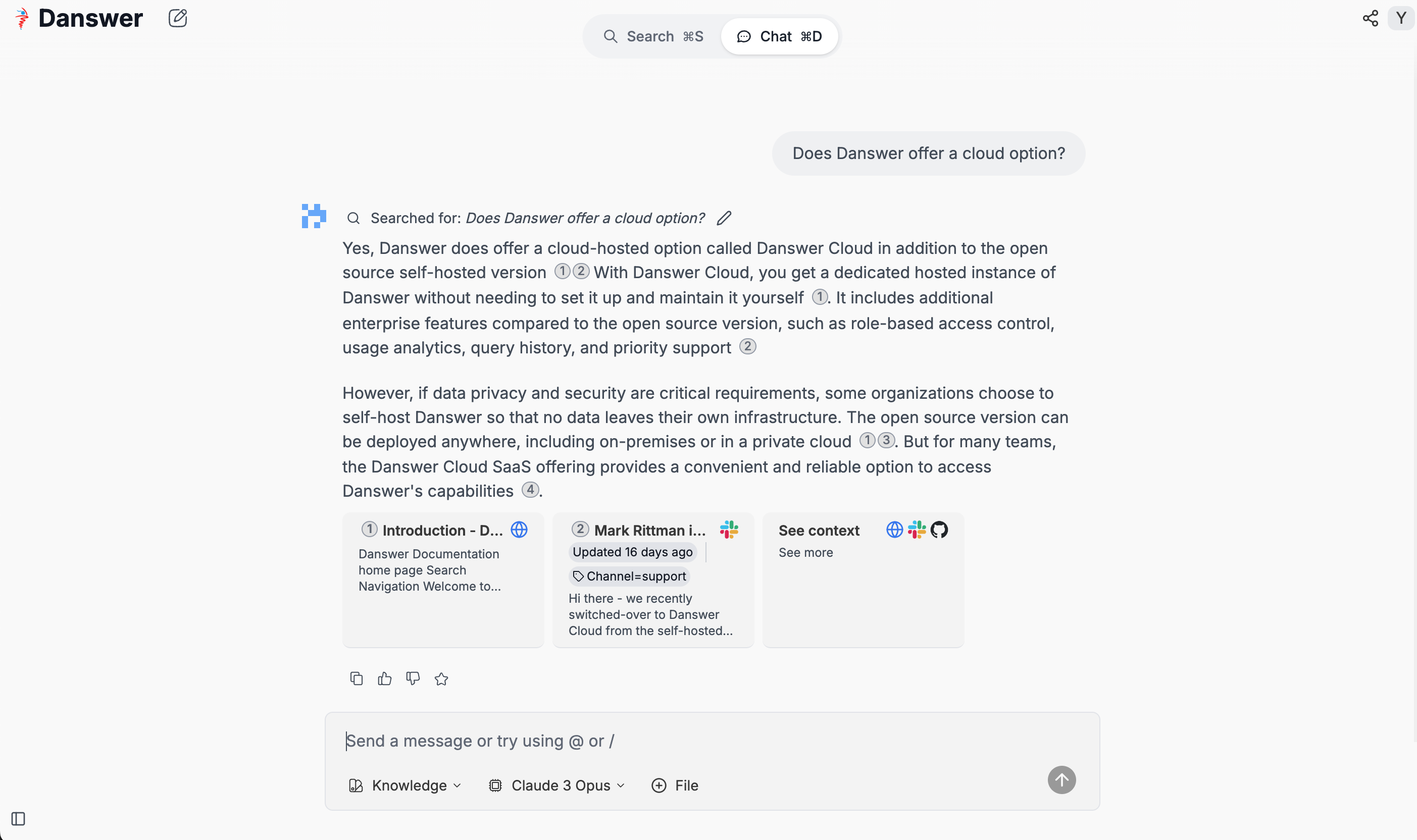 Danswer Chat powered by Vespa
Danswer Chat powered by Vespa
Summary
At Danswer we’re trying to make all the teams in the world more efficient with context aware GenAI assistants. For us, the core value that we provide on top of the LLMs is the ability to bring in the context of the user and the unique knowledge of the team. This of course necessitates a high quality search that remains accurate and performant at scale. We chose Vespa because of its richness of features, the amazing team behind it, and their commitment to staying up to date on every innovation in the search and NLP space. We look forward to the exciting features that the Vespa team is building and are excited to finalize our own migration to Vespa Cloud.
